模型评估:分类器和回归器的评估
Posted yongfuxue
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模型评估:分类器和回归器的评估相关的知识,希望对你有一定的参考价值。
分类器的评估
混淆矩阵
from sklearn.metrics import confusion_matrix
y_true = [2, 0, 2, 2, 0, 1]
y_pred = [0, 0, 2, 2, 0, 2]
confusion_matrix(y_true, y_pred)
>>>array([ [2, 0, 0],
[0, 0, 1],
[1, 0, 2] ])
个人理解:每一行的行索引代表一个类别,每一行代表一个类别被预测分到任意类别的个数
准确率
from sklearn.metrics import accuracy_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
accuracy_score(y_true, y_pred)
>>>0.5
accuracy_score(y_true, y_pred, normalize=False)
>>>2
Jaccard相似度
from sklearn.metrics import jaccard_similarity_score
y_pred = [0, 2, 1, 3]
y_true = [0, 1, 2, 3]
jaccard_similarity_score(y_true, y_pred)
>>>0.5
jaccard_similarity_score(y_true, y_pred, normalize=False)
>>>2
分类报告
该classification_report函数构建一个显示主分类指标的文本报告。
from sklearn.metrics import classification_report
y_true = [0, 1, 2, 2, 0]
y_pred = [0, 0, 2, 1, 0]
target_names = [‘class 0‘, ‘class 1‘, ‘class 2‘]
print(classification_report(y_true, y_pred, target_names=target_names))
>>>
precision recall f1-score support
class 0 0.67 1.00 0.80 2
class 1 0.00 0.00 0.00 1
class 2 1.00 0.50 0.67 2
avg / total 0.67 0.60 0.59 5
roc_auc_score
from sklearn.metrics import roc_auc_score
y_true = np.array([0, 0, 1, 1])
y_scores = np.array([0.1, 0.4, 0.35, 0.8])
roc_auc_score(y_true, y_scores)
>>>0.75
roc_curve
import numpy as np
from sklearn import metrics
y = np.array([1, 1, 2, 2])
scores = np.array([0.1, 0.4, 0.35, 0.8])
fpr, tpr, thresholds = metrics.roc_curve(y, scores, pos_label=2)
#打印
fpr
>>>array([0. , 0. , 0.5, 0.5, 1. ])
tpr
>>>array([0. , 0.5, 0.5, 1. , 1. ])
thresholds
>>>array([1.8 , 0.8 , 0.4 , 0.35, 0.1 ])
其他
from sklearn.metrics import f1_score
from sklearn.metrics import precision_score
回归器的评估
MSE(mean square error,均方误差)
from sklearn.metrics import mean_squared_error
MAE(平均绝对误差)
from sklearn.metrics import mean_absolute_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
mean_absolute_error(y_true, y_pred)
>>>0.5
Quantiles of Errors (中间绝对误差)
为了改进RMSE的缺点,提高评价指标的鲁棒性,使用误差的分位数来代替,如中位数来代替平均数。假设100个数,最大的数再怎么改变,中位数也不会变,因此其对异常点具有鲁棒性。
from sklearn.metrics import median_absolute_error
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
median_absolute_error(y_true, y_pred)
>>>0.5
R-square(决定系数)
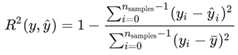
from sklearn.metrics import r2_score
y_true = [3, -0.5, 2, 7]
y_pred = [2.5, 0.0, 2, 8]
r2_score(y_true, y_pred)
>>>0.948
以上是关于模型评估:分类器和回归器的评估的主要内容,如果未能解决你的问题,请参考以下文章