数据预处理—独热编码
Posted neilzhang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据预处理—独热编码相关的知识,希望对你有一定的参考价值。
问题引入
在很多机器学习任务中,特征并不总是连续值,而有可能是分类值。
例如,考虑一下的三个特征:
["male", "female"] ["from Europe", "from US", "from Asia"] ["uses Firefox", "uses Chrome", "uses Safari", "uses Internet Explorer"]
如果将上述特征用数字表示,效率会高很多。例如:
["male", "from US", "uses Internet Explorer"] 表示为[0, 1, 3] ["female", "from Asia", "uses Chrome"]表示为[1, 2, 1]
但是,即使转化为数字表示后,上述数据也不能直接用在我们的分类器中。这个的整数特征表示并不能在分类器中直接使用,因为这样的连续输入,估计器会认为类别之间是有序的,但实际却是无序的。(例如:浏览器的类别数据则是任意排序的)。
1、Why do we binarize categorical features?
We binarize the categorical input so that they can be thought of as a vector from the Euclidean space (we call this as embedding the vector in the Euclidean space).使用one-hot编码,将离散特征的取值扩展到了欧式空间,离散特征的某个取值就对应欧式空间的某个点。
2、Why do we embed the feature vectors in the Euclidean space?
Because many algorithms for classification/regression/clustering etc. requires computing distances between features or similarities between features. And many definitions of distances and similarities are defined over features in Euclidean space. So, we would like our features to lie in the Euclidean space as well.
将离散特征通过one-hot编码映射到欧式空间,是因为,在回归,分类,聚类等机器学习算法中,特征之间距离的计算或相似度的计算是非常重要的,而我们常用的距离或相似度的计算都是在欧式空间的相似度计算,计算余弦相似性,基于的就是欧式空间。
3、Why does embedding the feature vector in Euclidean space require us to binarize categorical features?
Let us take an example of a dataset with just one feature (say job_type as per your example) and let us say it takes three values 1,2,3.
Now, let us take three feature vectors x_1 = (1), x_2 = (2), x_3 = (3). What is the euclidean distance between x_1 and x_2, x_2 and x_3 & x_1 and x_3? d(x_1, x_2) = 1, d(x_2, x_3) = 1, d(x_1, x_3) = 2. This shows that distance between job type 1 and job type 2 is smaller than job type 1 and job type 3. Does this make sense? Can we even rationally define a proper distance between different job types? In many cases of categorical features, we can properly define distance between different values that the categorical feature takes. In such cases, isn‘t it fair to assume that all categorical features are equally far away from each other?
Now, let us see what happens when we binary the same feature vectors. Then, x_1 = (1, 0, 0), x_2 = (0, 1, 0), x_3 = (0, 0, 1). Now, what are the distances between them? They are sqrt(2). So, essentially, when we binarize the input, we implicitly state that all values of the categorical features are equally away from each other.
将离散型特征使用one-hot编码,确实会让特征之间的距离计算更加合理。比如,有一个离散型特征,代表工作类型,该离散型特征,共有三个取值,不使用one-hot编码,其表示分别是x_1 = (1), x_2 = (2), x_3 = (3)。两个工作之间的距离是,(x_1, x_2) = 1, d(x_2, x_3) = 1, d(x_1, x_3) = 2。那么x_1和x_3工作之间就越不相似吗?显然这样的表示,计算出来的特征的距离是不合理。那如果使用one-hot编码,则得到x_1 = (1, 0, 0), x_2 = (0, 1, 0), x_3 = (0, 0, 1),那么两个工作之间的距离就都是sqrt(2).即每两个工作之间的距离是一样的,显得更合理。
4、About the original question?
Note that our reason for why binarize the categorical features is independent of the number of the values the categorical features take, so yes, even if the categorical feature takes 1000 values, we still would prefer to do binarization.
5、Are there cases when we can avoid doing binarization?
没必要用one-hot 编码的情形
Yes. As we figured out earlier, the reason we binarize is because we want some meaningful distance relationship between the different values. As long as there is some meaningful distance relationship, we can avoid binarizing the categorical feature. For example, if you are building a classifier to classify a webpage as important entity page (a page important to a particular entity) or not and let us say that you have the rank of the webpage in the search result for that entity as a feature, then 1] note that the rank feature is categorical, 2] rank 1 and rank 2 are clearly closer to each other than rank 1 and rank 3, so the rank feature defines a meaningful distance relationship and so, in this case, we don‘t have to binarize the categorical rank feature.
More generally, if you can cluster the categorical values into disjoint subsets such that the subsets have meaningful distance relationship amongst them, then you don‘t have binarize fully, instead you can split them only over these clusters. For example, if there is a categorical feature with 1000 values, but you can split these 1000 values into 2 groups of 400 and 600 (say) and within each group, the values have meaningful distance relationship, then instead of fully binarizing, you can just add 2 features, one for each cluster and that should be fine.
将离散型特征进行one-hot编码的作用,是为了让距离计算更合理,但如果特征是离散的,并且不用one-hot编码就可以很合理的计算出距离,那么就没必要进行one-hot编码,比如,该离散特征共有1000个取值,我们分成两组,分别是400和600,两个小组之间的距离有合适的定义,组内的距离也有合适的定义,那就没必要用one-hot 编码。
离散特征进行one-hot编码后,编码后的特征,其实每一维度的特征都可以看做是连续的特征。就可以跟对连续型特征的归一化方法一样,对每一维特征进行归一化。比如归一化到[-1,1]或归一化到均值为0,方差为1。
有些情况不需要进行特征的归一化:
It depends on your ML algorithms, some methods requires almost no efforts to normalize features or handle both continuous and discrete features, like tree based methods: c4.5, Cart, random Forrest, bagging or boosting. But most of parametric models (generalized linear models, neural network, SVM,etc) or methods using distance metrics (KNN, kernels, etc) will require careful work to achieve good results. Standard approaches including binary all features, 0 mean unit variance all continuous features, etc。
基于树的方法是不需要进行特征的归一化,例如随机森林,bagging 和 boosting等。基于参数的模型或基于距离的模型,都是要进行特征的归一化。
Tree Model不太需要one-hot编码
对于决策树来说,one-hot的本质是增加树的深度
tree-model是在动态的过程中生成类似 One-Hot + Feature Crossing 的机制
1. 一个特征或者多个特征最终转换成一个叶子节点作为编码 ,one-hot可以理解成三个独立事件
2. 决策树是没有特征大小的概念的,只有特征处于他分布的哪一部分的概念
独热编码
为了解决上述问题,其中一种可能的解决方法是采用独热编码(One-Hot Encoding)。独热编码即 One-Hot 编码,又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候,其中只有一位有效。例如:
自然状态码为:000,001,010,011,100,101 独热编码为:000001,000010,000100,001000,010000,100000
可以这样理解,对于每一个特征,如果它有m个可能值,那么经过独热编码后,就变成了m个二元特征(如成绩这个特征有好,中,差变成one-hot就是100, 010, 001)。并且,这些特征互斥,每次只有一个激活。因此,数据会变成稀疏的。
这样做的好处主要有:
1. 决了分类器不好处理属性数据的问题
2. 一定程度上也起到了扩充特征的作用
实际运用
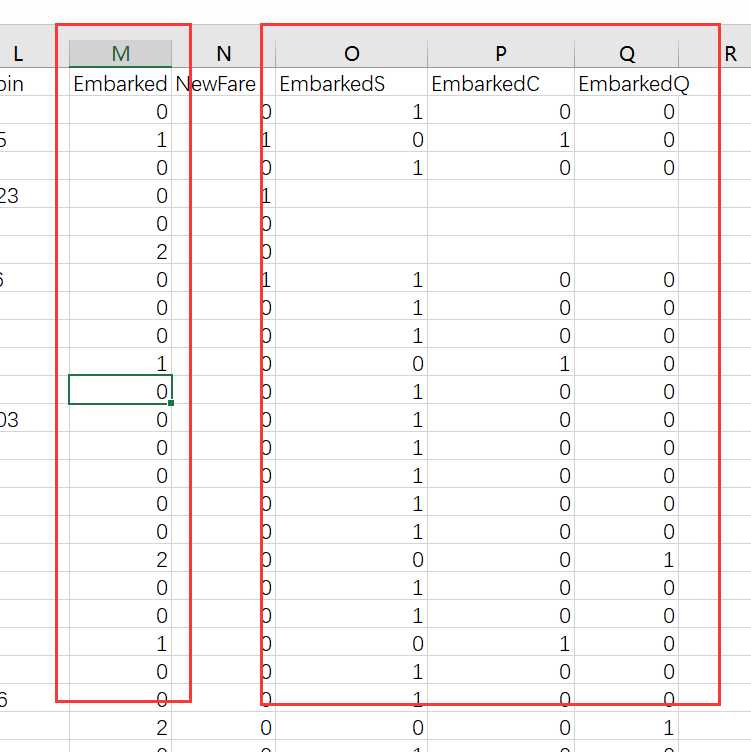
kaggle中tianic问题中: 登陆的地点有三个,在数据中分别用 S,C,Q表示。
由于这三个值是没有任何关联的,可以对其进行编码为 0 ,1,2。 理论上计算这三个特征值之间的距离应该时相等的,但是这时在计算欧式距离时他们的距离并不相等。 所以采用独热码进行编码,python代码如下:
数据填充:
def dataPreprocess(df): df.loc[df[‘Sex‘] == ‘male‘, ‘Sex‘] = 0 df.loc[df[‘Sex‘] == ‘female‘, ‘Sex‘] = 1 # 由于 Embarked中有两个数据未填充,需要先将数据填满 df[‘Embarked‘] = df[‘Embarked‘].fillna(‘S‘) # 部分年龄数据未空, 填充为 均值 df[‘Age‘] = df[‘Age‘].fillna(df[‘Age‘].median())df.loc[df[‘Embarked‘]==‘S‘, ‘Embarked‘] = 0 df.loc[df[‘Embarked‘] == ‘C‘, ‘Embarked‘] = 1 df.loc[df[‘Embarked‘] == ‘Q‘, ‘Embarked‘] = 2
df[‘NewFare‘] = df[‘Fare‘]
df.loc[(df.Fare < 40), ‘NewFare‘] = 0
df.loc[((df.Fare >= 40) & (df.Fare < 100)), ‘NewFare‘] = 1
df.loc[((df.Fare >= 100) & (df.Fare < 150)), ‘NewFare‘] = 2
df.loc[((df.Fare >= 150) & (df.Fare < 200)), ‘NewFare‘] = 3
df.loc[(df.Fare >= 200), ‘NewFare‘] = 4
return df
利用独热码对 ‘Embarked‘ 属性进行编码
def data_process_onehot(df): #copy_df = df.copy() train_Embarked = df["Embarked"].values.reshape(-1,1) onehot_encoder = OneHotEncoder(sparse=False) train_OneHotEncoded = onehot_encoder.fit_transform(train_Embarked) df["EmbarkedS"] = train_OneHotEncoded[:, 0] df["EmbarkedC"] = train_OneHotEncoded[:, 1] df["EmbarkedQ"] = train_OneHotEncoded[:, 2] return df
编码后效果:
整个数据处理过程:
data_train = ReadData.readSourceData() data_train = dataPreprocess(data_train) data_train = data_process_onehot(data_train) precent = linearRegression(data_train)
参考:
https://blog.csdn.net/wl_ss/article/details/78508367
以上是关于数据预处理—独热编码的主要内容,如果未能解决你的问题,请参考以下文章