爬虫--Scrapy-持久化存储操作2
Posted foremostxl
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫--Scrapy-持久化存储操作2相关的知识,希望对你有一定的参考价值。
1、管道的高级操作
将爬取到的数据值分别存储到本地磁盘、redis数据库、mysql数据。
需求:将爬取到的数据值分别存储到本地磁盘、redis数据库、mysql数据。
1.需要在管道文件中编写对应平台的管道类
2.在配置文件中对自定义的管道类进行生效操作
qiubai.py
import scrapy from qiubaipro.items import QiubaiproItem class QiubaiSpider(scrapy.Spider): name = ‘qiubai‘ #allowed_domains = [‘www.qiushibaike.com/text‘] start_urls = [‘https://www.qiushibaike.com/text/‘] def parse(self, response): # 建议大家使用xpath进行解析(框架集成了xpath解析的接口) div_list = response.xpath("//div[@id=‘content-left‘]/div") # 存储到的解析到的页面数据 data_list = [] for div in div_list: author = div.xpath(‘./div/a[2]/h2/text()‘).extract_first() #content = div.xpath(".//div[@class=‘content‘]/span/text()") content = div.xpath(".//div[@class=‘content‘]/span/text()").extract_first() # 1.将解析到数据值(author和content)储存到items对象 item = QiubaiproItem() item[‘author‘] = author item[‘content‘] = content # 2.将item对象提交给管道 yield item
pipelines.py
import redis import pymysql class QiubaiproPipeline(object): conn = None def open_spider(self,spider): print(‘写入到redis服务器‘) print(‘开始爬虫‘) # redis服务器port self.conn = redis.Redis(host=‘127.0.0.1‘,port=6379) # 该方法可以接受爬虫文件中提交过来的item对象,并且对item对象的页面数据进行持久化处理 # 参数:item表示的就是接受到的item对象 def process_item(self, item, spider): # 1.链接数据库 dict = {‘author‘:item[‘author‘], ‘content‘:item[‘content‘]} self.conn.lpush(‘data‘,dict) return item # 该方法只会在爬虫结束的时候被调用一次 def close_spider(self,spider): print(‘爬虫结束‘) # 实现将数据值存到本地磁盘中 class QiubaiByFiles(object): # 该方法可以接受爬虫文件中提交过来的item对象,并且对item对象的页面数据进行持久化处理 # 参数:item表示的就是接受到的item对象 def open_spider(self,spider): print(‘写入到本地磁盘中‘) print(‘开始爬虫‘) self.fp = open(‘./qiubai_pipe.txt‘, ‘w‘, encoding=‘utf-8‘) # 该方法可以接受爬虫文件中提交过来的item对象,并且对item对象的页面数据进行持久化处理 # 参数:item表示的就是接受到的item对象 def process_item(self, item, spider): author = item[‘author‘] content = item[‘content‘] # 持久化存储io操作 self.fp.write(author+‘:‘+content+‘ ‘) return item # 该方法只会在爬虫结束的时候被调用一次 def close_spider(self,spider): print(‘爬虫结束‘) self.fp.close() # 实现将数据值存储到mysql数据库中 class QiubaiByMysql(object): conn = None # mysql的连接对象声明 cursor = None # mysql游标对象声明 def open_spider(self,spider): print(‘写入到mysql数据库中‘) print(‘开始爬虫‘) # 链接数据库 # host 本机的ip地址 # 在命令行输入 ipconfig查看 self.conn = pymysql.Connect(host=‘10.10.40.140‘,port=3306,user=‘root‘,password=‘123‘,db=‘qiubai‘,charset=‘utf8‘) # 该方法可以接受爬虫文件中提交过来的item对象,并且对item对象的页面数据进行持久化处理 # 参数:item表示的就是接受到的item对象 def process_item(self, item, spider): # 1.链接数据库 # 执行sql语句 # 插入数据 sql = ‘insert into qiubai(author,content) values("%s","%s")‘%(item[‘author‘], item[‘content‘]) # 获取游标 self.cursor = self.conn.cursor() try: self.cursor.execute(sql) self.conn.commit() except Exception as e: print(e) self.conn.rollback() # 提交事务 return item # 该方法只会在爬虫结束的时候被调用一次 def close_spider(self,spider): print(‘爬虫结束‘) self.cursor.close() self.conn.close()
在settings配置
# 数字表示优先级,数字越大优先级越高 ITEM_PIPELINES = { ‘qiubaipro.pipelines.QiubaiproPipeline‘: 300, ‘qiubaipro.pipelines.QiubaiByFiles‘:400, ‘qiubaipro.pipelines.QiubaiByMysql‘:500, }
打开终端,先进入文件目录
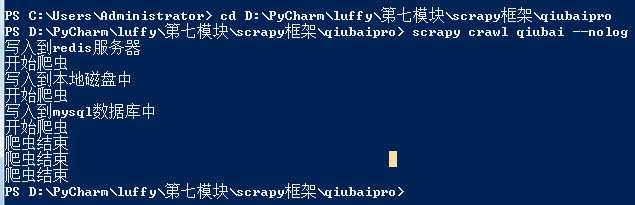
多个url数据爬取
***问题:针对多个url进行数据的爬取
解决方案:请求的手动发送
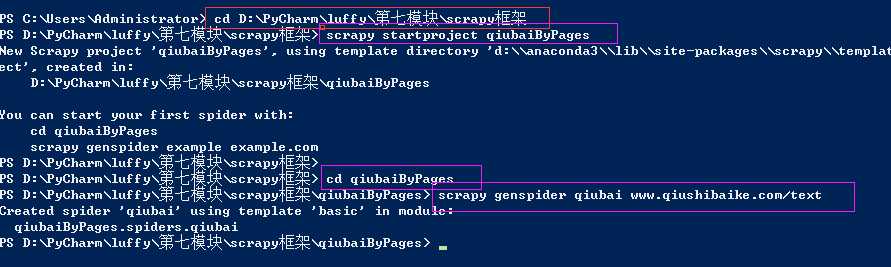
1、新建一个工程
cd 到需要保存工程的目录
scrapy startproject qiubaiByPages
cd qiubaiByPages
爬虫文件的名称,起始url
scrapy genspider qiubai www.qiushibaike.com/text
把实现的步骤在理清一次
以上是关于爬虫--Scrapy-持久化存储操作2的主要内容,如果未能解决你的问题,请参考以下文章