拒绝推断问题(转)
Posted gczr
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了拒绝推断问题(转)相关的知识,希望对你有一定的参考价值。
拒绝推断(Reject Inference)是金融领域信用评分中的一个术语。对于要向银行借钱的人,我们需要考虑他们赖账的可能性。这样就需要根据他们的各种行为信息和人口统计学特征作为输入,来建立一个信用评分模型,这个建模过程与机器学习中训练一个模型类似。机器学习算法能够成功应用的一个条件是训练样本和测试样本有相同的分布,但在信用评分中,这个条件很难保证。信用评分的训练样本均来自于以前申请贷款被接受的那些人,而评分模型则是要应用到所以来申请贷款的人,并帮助做出接受/拒绝的决定。因此,模型不光要针对被接受的那些人,也要在被拒绝的那部分上面表现得好。可以想见,这两种人在输入空间上的分布是完全不同的,这就导致使用了部分数据,但是为估计总体而建立的信用评分模型存在参数估计的偏差。拒绝推断就是要把被拒掉那部分用户能够识别出来到底是好客户还是坏客户,然后加入到模型训练中,使得模型的样本尽量接近总体的分布。这就是拒绝推断要解决的。
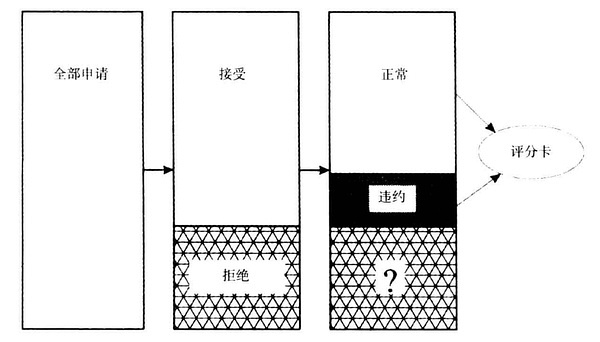 |
在其他更加“机器学习化”的领域,例如计算广告,也会有被称为selection bias的类似问题存在。一般来说,网络广告点击率模型是根据广告本身、所出现的场景以及用户信息三者建立的,期望是能挑出那些被点击概率高的广告展示出来以改善用户体验并获得更高的广告提成。显然,建这样的模型需要广告的"被点击/不被点击"的信息作为模型的目标变量。只有那些历史上出现过的"广告-场景-用户"三元组,才会有被或不被点击的信息;从来没有出现过的三元组不会出现在训练数据中——它们是被已存在的点击率模型筛选过的。而优化点击率模型时,总是要面对新广告和新用户,并且尝试新的广告/场景匹配会不会更好,因此测试数据的分布不会和训练数据一致。
对于计算广告来说,这个问题好解决一些。我们可以把一小部分流量做成不经过模型筛选的"自然流量“,采用简单的诸如竞价排名之类的策略。这样用户体验的影响不大,而利润几乎也没什么损失。这部分流量累积下来的数据可以在模型训练中赋予更高的权重,因为某种意义下它们和测试数据"更加接近"。但在金融行业,要说服管理层开放这样的"自然流量"绝非易事。并且相对互联网广告,信贷的样本要少得多,即使有一些这样的"自然流量"样本,它们能起的作用也有限。所以有必要从另外的角度考虑问题的解决方法。
下面我首先会总结一些信用评分中常用的拒绝推断的方法。这些方法往往是比较ad-hoc的思路,或者有少许的统计学理论作为支撑。即使是经常在使用这些方法的信用评分建模专家,往往也对它们并不信服。然后我会看看机器学习的相关文献中对付selection bias的方法——这些方法一般是基于半监督学习(semi-supervised learning)这一理念的——并且检查它们是否能用到信用评分的拒绝推断中。
常用方法:

来源:https://www.douban.com/note/410573602/?type=like
以上是关于拒绝推断问题(转)的主要内容,如果未能解决你的问题,请参考以下文章