Scrapy架构图
Posted xuxaut-558
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Scrapy架构图相关的知识,希望对你有一定的参考价值。
Scrapy架构图
=================================================================================
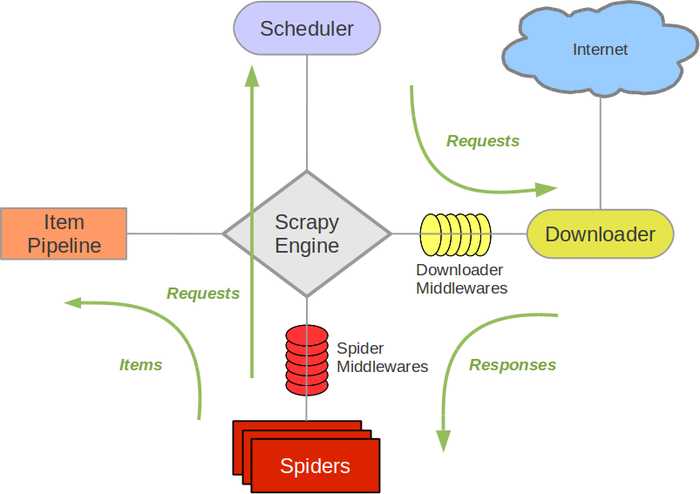
- scrapy概述
- 包含各个部件
- ScrapyEngine: 神经中枢,大脑,核心、
- Scheduler调度器:引擎发来的request请求,调度器需要处理,然后交换引擎
- Downloader下载器:把引擎发来的requests发出请求,得到response
- Spider爬虫: 负责把下载器得到的网页/结果进行分解,分解成数据+链接
- ItemPipeline管道: 详细处理Item
- DownloaderMiddleware下载中间件: 自定义下载的功能扩展组件
- SpiderMiddleware爬虫中间件:对spider进行功能扩展
- 爬虫项目大概流程
- 新建项目:scrapy startproject xxx
- 明确需要目标/产出: 编写item.py
- 制作爬虫 : 地址 spider/xxspider.py
- 存储内容: pipelines.py,
- ItemPipeline
- 对应的是pipelines文件
- 爬虫提取出数据存入item后,item中保存的数据需要进一步处理,比如清洗,去重,存储等
- process_item:
- spider提取出来的item作为参数传入,同时传入的还有spider
- 此方法必须实现
- 必须返回一个Item对象,被丢弃的item不会被之后的pipeline处理
- __init__:构造函数
- 进行一些必要的参数初始化
- open_spider(spider):
- spider对象被开启的时候调用
- close_spider(spider):
- 当spider对象被关闭的时候调用
- Spider
- 对应的是文件夹spiders下的文件
- __init__: 初始化爬虫名称,start_urls列表
- start_requests:生成Requests对象交给Scrapy下载并返回response
- parse: 根据返回的response解析出相应的item,item自动进入pipeline; 如果需要,解析出url,url自动交给
requests模块,一直循环下去
- start_request: 此方法仅能被调用一次,读取start_urls内容并启动循环过程
- name:设置爬虫名称
- start_urls: 设置开始第一批爬取的url
- allow_domains:spider允许爬去的域名列表
- start_request(self): 只被调用一次
- parse
- log:日志记录
- 中间件(DownloaderMiddlewares)
- 中间件是处于引擎和下载器中间的一层组件
- 可以有很多个,被按顺序加载执行
- 作用是对发出的请求和返回的结果进行预处理
- 在middlewares文件中
- 需要在settings中设置以便生效
- 一般一个中间件完成一项功能
- 必须实现以下一个或者多个方法
- process_request(self, request, spider)
- 在request通过的时候被调用
- 必须返回None或Response或Request或raise IgnoreRequest
- None: scrapy将继续处理该request
- Request: scrapy会停止调用process_request并冲洗调度返回的reqeust
- Response: scrapy不会调用其他的process_request或者process_exception,直接讲该response作为结果返回
同时会调用process_response函数
- process_response(self, request, response, spider)
- 跟process_request大同小异
- 每次返回结果的时候会自动调用
- 可以有多个,按顺序调用
- 案例代码
import random
import base64
# 从settings设置文件中导入值
from settings import USER_AGENTS
from settings import PROXIES
# 随机的 User-Agent
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
request.headers.setdefault("User-Agent", useragent)
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXIES)
if proxy[‘user_passwd‘] is None:
# 没有代理账户验证的代理使用方式
request.meta[‘proxy‘] = "http://" + proxy[‘ip_port‘]
else:
# 对账户密码进行 base64 编码转换
base64_userpasswd = base64.b64encode(proxy[‘user_passwd‘])
# 对应到代理服务器的信令格式里
request.headers[‘Proxy-Authorization‘] = ‘Basic ‘ + base64_userpasswd
request.meta[‘proxy‘] = "http://" + proxy[‘ip_port‘]
- 设置settings的相关代码
USER_AGENTS = [
"Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; Win64; x64; Trident/5.0; .NET CLR
3.5.30729; .NET CLR 3.0.30729; .NET CLR 2.0.50727; Media Center PC 6.0)",
"Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0; WOW64; Trident/4.0;
SLCC2; .NET CLR 2.0.50727; .NET CLR 3.5.30729; .NET CLR 3.0.30729; .NET CLR 1.0.3705; .NET
CLR 1.1.4322)",
"Mozilla/4.0 (compatible; MSIE 7.0b; Windows NT 5.2; .NET CLR 1.1.4322; .NET CLR
2.0.50727; InfoPath.2; .NET CLR 3.0.04506.30)",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN) AppleWebKit/523.15 (Khtml, like Gecko,
Safari/419.3) Arora/0.3 (Change: 287 c9dfb30)",
"Mozilla/5.0 (X11; U; Linux; en-US) AppleWebKit/527+ (KHTML, like Gecko, Safari/419.3)
Arora/0.6",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.8.1.2pre) Gecko/20070215 K-
Ninja/2.1.1",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; zh-CN; rv:1.9) Gecko/20080705 Firefox/3.0
Kapiko/3.0",
"Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5"
]
PROXIES = [
{‘ip_port‘: ‘111.8.60.9:8123‘, ‘user_passwd‘: ‘user1:pass1‘},
{‘ip_port‘: ‘101.71.27.120:80‘, ‘user_passwd‘: ‘user2:pass2‘},
{‘ip_port‘: ‘122.96.59.104:80‘, ‘user_passwd‘: ‘user3:pass3‘},
{‘ip_port‘: ‘122.224.249.122:8088‘, ‘user_passwd‘: ‘user4:pass4‘},
]
- 去重
- 为了放置爬虫陷入死循环,需要去重
- 即在spider中的parse函数中,返回Request的时候加上dont_filter=False参数
myspeder(scrapy.Spider):
def parse(.....):
......
yield scrapy.Request(url=url, callback=self.parse, dont_filter=False)
- 如何在scrapy使用selenium
- 可以放入中间件中的process_request函数中
- 在函数中调用selenium,完成爬取后返回Response
calss MyMiddleWare(object):
def process_request(.....):
driver = webdriver.Chrome()
html = driver.page_source
driver.quit()
return HtmlResponse(url=request.url, encoding=‘utf-8‘, body=html, request=request)
================
把selenium放入中间件的process_request函数中,就不会访问downloadr了,
直接访问selenium的process_request函数;然后返回。
把请求包装成HtmlResponse返回。
以上是关于Scrapy架构图的主要内容,如果未能解决你的问题,请参考以下文章