十三周翻译
Posted jiangfan123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了十三周翻译相关的知识,希望对你有一定的参考价值。
《Pro SQL Server Internals, 2nd edition》
作者:Dmitri Korotkevitch
聚集索引
聚集索引指示表中数据的物理顺序,该表根据聚簇索引键进行排序。 该表只能定义一个聚集索引。 假设您要在堆表上使用数据创建聚集索引。 作为第一步,如图2-5所示,SQL Server会创建另一个数据副本,然后根据群集密钥的值对其进行排序。 数据页链接在双链表中,其中每个页面都包含指向链中下一页和上一页的指针。 此列表称为索引的叶级,它包含实际的表数据。
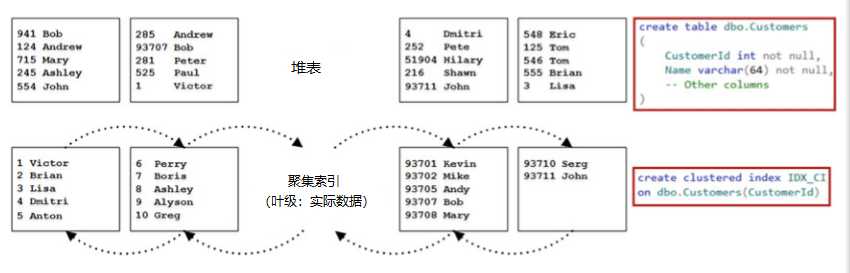
注意页面上的排序顺序由插槽阵列控制。 页面上的实际数据未排序。
当叶级别由多个页面组成时,SQL Server开始构建索引的中间级别,如图2-6所示。
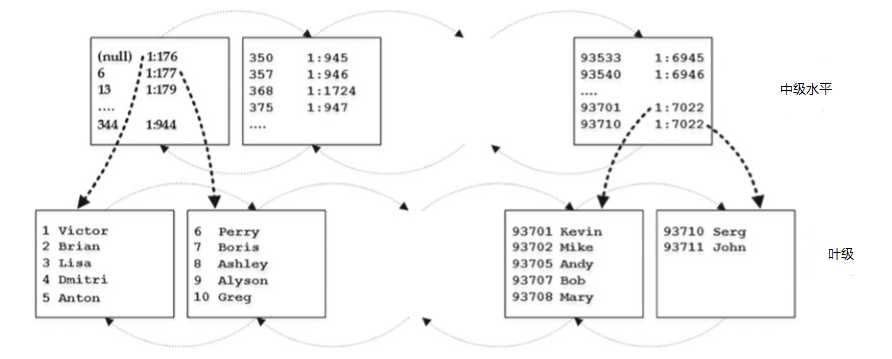
中间级别为每个叶级页面存储一行。 它存储两条信息:它引用的页面中的索引键的物理地址和最小值。 唯一的例外是第一页上的第一行,其中SQL Server存储NULL而不是最小索引键值。 通过这种优化,当您在表中插入具有最低键值的行时,SQL Server不需要更新非叶级行。
中间级别的页面也链接到双链表。 SQL Server添加了越来越多的中间级别,直到只包含单个页面的级别。 此级别称为根级别,它将成为索引的入口点,如图2-7所示。
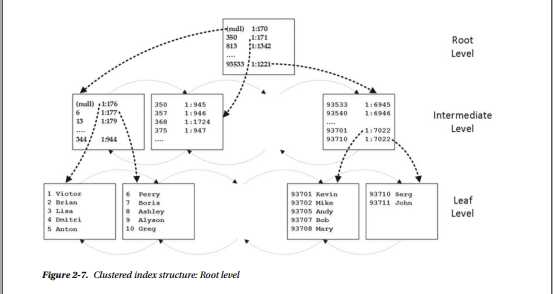
如您所见,索引始终具有一个叶级别,一个根级别以及零个或多个中间级别。唯一的例外是索引数据适合单个页面时。在这种情况下,SQL Server不会创建单独的根级页面,索引只包含单个叶级页面。
索引中的级别数很大程度上取决于行和索引键的大小。例如,4字节整数列上的索引在中间和根级别上每行需要13个字节。这13个字节由一个2字节的插槽数组条目,一个4字节的索引键值,一个6字节的页面指针和一个1字节的行开销组成,这是足够的,因为索引键不包含变量 - length和NULL列。
因此,每行可容纳8,060字节/ 13字节=每页620行。这意味着,使用一个中间级别,您可以存储最多620 * 620 = 384,400个叶级页面的信息。如果数据行大小为200字节,则每个叶级页面可存储40行,索引中最多可存储15,376,000行,只有三个级别。向索引添加另一个中间级别将基本上涵盖所有可能的整数值。
注意在现实生活中,索引碎片会减少这些数字。 我们将在第6章讨论索引碎片。
SQL Server可以通过三种不同的方式从索引中读取数据。 第一个是有序扫描。 假设我们想要运行SELECT Name FROM dbo.Customers ORDER BY CustomerId查询。 索引的叶级别上的数据已根据CustomerId列值进行排序。 因此,SQL Server可以从第一页到最后一页扫描索引的叶级,并按存储顺序返回行。
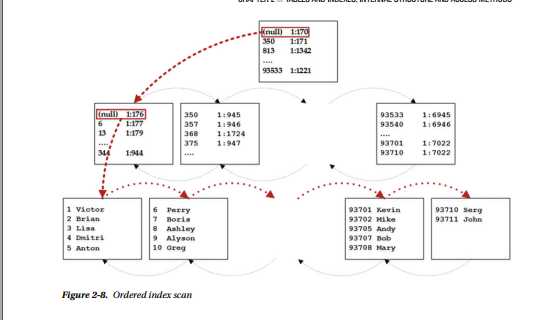
SQL Server从索引的根页开始,从那里读取第一行。 该行使用表中的最小键值引用中间页面。 SQL Server读取该页面并重复该过程,直到找到叶级别的第一页。 然后,SQL Server开始逐个读取行,
移动页面的链接列表,直到读取所有行。 图2-8说明了这个过程。
上述查询的执行计划显示了“集群索引扫描”运算符,其中Ordered属性设置为true,如图2-9所示。

值得一提的是,触发有序扫描不需要order by子句。 有序扫描只意味着SQL Server根据索引键的顺序读取数据。
SQL Server可以向前和向后两个方向导航索引。 但是,您必须记住一个重要方面:SQL Server在向后索引扫描期间不使用并行性。
提示您可以通过检查执行计划中的INDEX SCAN或INDEX SEEK运算符属性来检查扫描方向。 但请记住,Management Studio不会在执行计划的图形表示中显示这些属性。 您需要打开“属性”窗口以通过在执行计划中选择运算符并选择“视图/属性窗口”菜单项或按F4键来查看它。
SQL Server企业版具有称为旋转木马扫描的优化功能,允许多个任务共享相同的索引扫描。 假设您有会话S1,它正在扫描索引。 在扫描中间的某个时刻,另一个会话S2运行需要扫描相同索引的查询。 通过旋转木马扫描,S2将S1连接到当前扫描位置。 SQL Server只读取每个页面一次,将行传递给两个会话。
当S1扫描到达索引的末尾时,S2开始从索引的开头扫描数据,直到S2扫描开始的点。 旋转木马扫描是另一个例子,说明为什么不能依赖索引键的顺序以及为什么在重要时应始终指定ORDER BY子句。
有序扫描之后的下一个访问方法称为分配顺序扫描。 SQL Server通过IAM页面访问表数据,类似于使用堆表的方式。 SELECT名称FROM dbo.Customers WITH(NOLOCK)查询和图2-10说明了这种方法。 图2-11显示了查询执行计划。

不幸的是,当SQL Server使用分配顺序扫描时,检测起来并不容易。 即使执行计划中的Ordered属性显示为false,也表示SQL Server不关心是否按索引键的顺序读取行,而不是使用分配顺序扫描。
尽管扫描大型表的启动成本较高,但分配顺序扫描可以更快地扫描大型表。 当表很小时,SQL Server不使用此访问方法。 另一个重要的考虑是数据一致性 SQL Server不在具有聚簇索引的表中使用转发指针,并且分配顺序扫描可能会产生不一致的结果。 由于页面拆分导致的数据移动,可以多次跳过或读取行。 因此,SQL Server通常会避免使用分配顺序扫描,除非它读取READ UNCOMMITTED或SERIALIZABLE事务隔离级别中的数据。
注意我们将在第6章“索引碎片”中讨论页面拆分和碎片,并讨论第三部分“锁定,阻塞和并发”中的锁定和数据一致性。
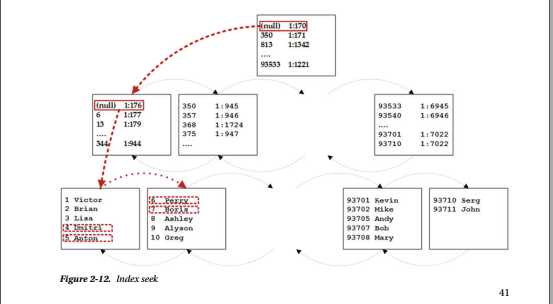
最后一个索引访问方法称为索引查找。 SELECT名称来自dbo.Customers WHERE CustomerId BETWEEN 4和7查询以及图2-12说明了操作。
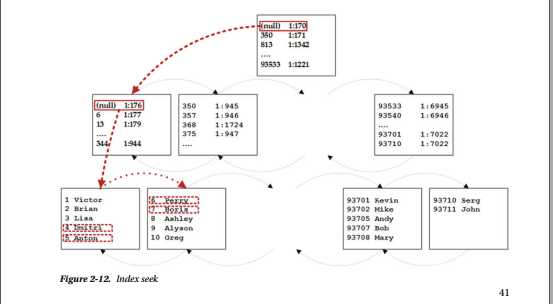
为了从表中读取行的范围,SQL Server需要从该范围中找到具有最小键值的行,即4. SQL Server以根页面开始,其中第二行引用该页面的页面。 最小键值350.它大于我们要查找的键值(4),SQL Server读取根页面第一行引用的中间级数据页(1:170)。
同样,中间页面将SQL Server引导到第一个叶级页面(1:176)。 SQL Server读取该页面,然后它读取CustomerIds等于4和5的行,最后,它从第二页读取剩余的两行。
执行计划如图2-13所示。
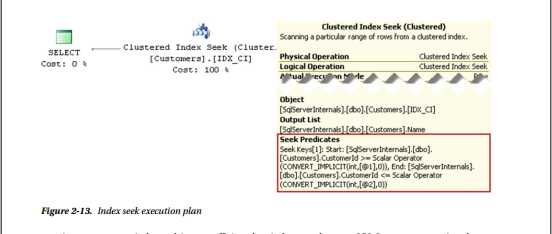
您可以猜测,索引搜索比索引扫描更有效,因为SQL Server只处理行和数据页的子集,而不是扫描整个表。
从技术上讲,索引搜索操作有两种。第一种称为单例查找,有时称为点查找,其中SQL Server寻找并返回单行。您可以考虑将WHERE CustomerId = 2谓词作为示例。另一种类型的索引查找操作称为范围扫描,它要求SQL Server查找键的最低值或最高值,并扫描(向前或向后)行集,直到达到扫描范围的末尾。 CustomerId BETWEEN 4和7之间的谓词WHERE导致范围扫描。这两种情况都在执行计划中显示为INDEX SEEK操作。
您可以猜到,范围扫描完全可以强制SQL Server处理索引中的大量甚至所有数据页。例如,如果您将查询更改为使用WHERE CustomerId> 0谓词,则SQL Server将读取所有行/页,即使您在执行计划中显示了Index Seek运算符。您必须牢记此行为,并始终在查询性能调整期间分析范围扫描的效率。
关系数据库中有一个名为SARGable谓词的概念,它代表搜索参数。如果索引存在,如果SQL Server可以使用索引查找操作,则谓词是SARGable。简而言之,当SQL Server可以隔离要处理的索引键值的单个值或范围时,谓词是SARGable,因此在谓词评估期间限制搜索。显然,使用SARGable谓词编写查询并尽可能利用索引查找是有益的。
SARGable谓词包括以下运算符:=,>,> =,<,<=,IN,BETWEEN和LIKE(在前缀匹配的情况下)。非SARGable运算符包括NOT,<>,LIKE(在非前缀匹配的情况下)和NOT IN。
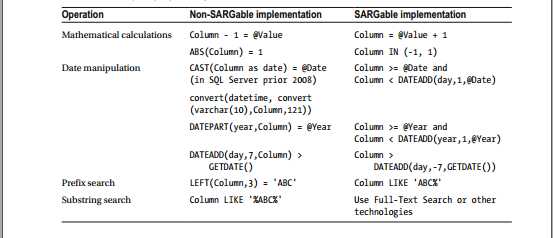
使谓词非SARGable的另一种情况是对表列使用函数或数学计算。 SQL Server必须为其处理的每一行调用该函数或执行计算。幸运的是,在某些情况下,您可以重构查询以使这样的谓词成为SARGable。表2-1列出了一些例子。
表2-1。 将非SARGable谓词重构为SARGable的示例。
您必须牢记的另一个重要因素是类型转换。 在某些情况下,您可以使用不正确的数据类型使谓词非SARGable。 让我们创建一个包含varchar列的表
用一些数据填充它,如例2-6所示。
例2-6 SARG谓词和数据类型:测试表创建
create table dbo.Data ( VarcharKey varchar(10) not null, Placeholder char(200) ); create unique clustered index IDX_Data_VarcharKey on dbo.Data(VarcharKey); ;with N1(C) as (select 0 union all select 0) -- 2 rows ,N2(C) as (select 0 from N1 as T1 cross join N1 as T2) -- 4 rows ,N3(C) as (select 0 from N2 as T1 cross join N2 as T2) -- 16 rows ,N4(C) as (select 0 from N3 as T1 cross join N3 as T2) -- 256 rows ,N5(C) as (select 0 from N4 as T1 cross join N4 as T2) -- 65,536 rows ,IDs(ID) as (select row_number() over (order by (select null)) from N5) insert into dbo.Data(VarcharKey) select convert(varchar(10),ID) from IDs;
聚集索引键列定义为varchar,即使它存储整数值。 现在,让我们运行两个选择,如例2-7所示,并查看执行计划。
例2-7 SARG谓词和数据类型:使用整数参数选择
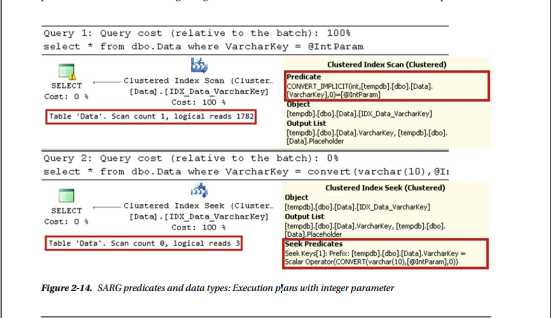
declare @IntParam int = ‘200‘ select * from dbo.Data where VarcharKey = @IntParam; select * from dbo.Data where VarcharKey = convert(varchar(10),@IntParam);
如图2-14所示,对于整数参数,SQL Server扫描聚集索引,将varchar转换为每行的整数。 在第二种情况下,SQL Server在开始时将整数参数转换为varchar,并使用更高效的聚集索引查找操作。
提示请注意连接谓词中的列数据类型。 隐式或显式数据类型转换可能会显着降低查询的性能。在unicode字符串参数的情况下,您将观察到非常类似的行为。 让我们运行例2-8中所示的查询。 图2-15显示了语句的执行计划。
例2-8 SARG谓词和数据类型:使用字符串参数选择。
select * from dbo.Data where VarcharKey = ‘200‘;
select * from dbo.Data where VarcharKey = N‘200‘; --
unicode parameter
如您所见,对于varchar列,unicode字符串参数是非SARGable。这是一个比看起来更大的问题。虽然您很少以这种方式编写查询,如清单2-8所示,但现在大多数应用程序开发环境都将字符串视为unicode。因此,除非将参数数据类型显式指定为varchar,否则SQL Server客户端库会为字符串对象生成unicode(nvarchar)参数。这使得谓词不具有SARG,并且由于不必要的扫描,它可能导致主要的性能命中,即使对varchar列进行索引也是如此。
重要始终在客户端应用程序中指定参数数据类型例如,在ADO.Net中,使用Parameters.Add(“@ ParamName”,SqlDbType.Varchar,<Size>)。Value = stringVariable而不是Parameters.Add(“@ ParamName”)。Value = stringVariable overload。在ORM框架中使用映射来显式指定类中的非unicode属性。
值得一提的是,对于nvarchar unicode数据列,varchar参数是SARGable。
以上是关于十三周翻译的主要内容,如果未能解决你的问题,请参考以下文章