21.1 引言
可靠性的保证之一就是超时重传
前面两个超时重传的例子
1) ICMP端口不能到达时,TFTP客户使用UDP实现了一个简单的超时和重传机制,假定5s是一个适当是时间间隔,并每隔5s进行重传
2) 在向一个不存在的主机发送ARP的 例子中,可看到当TCP试图建立连接的时候,在每个重传之间使用一个较长的时延来重传SYN
对于每个连接,TCP管理4个不同的定时器:
1) 重传定时器使用于当希望收到另一端的确认
2) 坚持(persist)定时器使窗口大小信息保持不断流动,即使另一端关闭了其接收窗口。22章介绍
3) 保活(keepalive)定时器可以检测到一个空闲连接的另一端何时崩溃或重启。23章介绍
4) 2MSL定时器测量一个连接处于TIME_WAIT状态的时间。
21.1 超时重传的简单的例子
下面是具体的操作:

下面是tcpdump的输出:

19行表示发送方的TCP最终放弃并发送一个复位信号的
可以看到连续重传的时间差,取整后分别为1, 3, 6, 12, 24, 48 和多个64。这种倍乘关系称为指数退避(exponential backoff)。
注意最后放弃的时间,大约是9分组,首次分组(第六行)传输到复位信号传输(19行)。该时间在目前的TCP实现中是不可变的。
// ++++++++++++++++++++++++++++++++++++++
有篇文章:
http://blog.csdn.net/qq_35420908/article/details/72461315
下面这个文章好一点:
https://www.cnblogs.com/menghuanbiao/p/5213722.html
第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据,在上述过程中,还有一些重要的概念:
未连接队列:在三次握手协议中,服务器维护一个未连接队列,该队列为每个客户端的SYN包(syn=j)开设一个条目,该条目表明服务器已收到SYN包,并向客户发出确认,正在等待客户的确认包。这些条目所标识的连接在服务器处于Syn_RECV状态,当服务器收到客户的确认包时,删除该条目,服务器进入ESTABLISHED状态。
Backlog参数:表示未连接队列的最大容纳数目。
SYN-ACK 重传次数 服务器发送完SYN-ACK包,如果未收到客户确认包,服务器进行首次重传,等待一段时间仍未收到客户确认包,进行第二次重传,如果重传次数超过系统规定的最大重传次数,系统将该连接信息从半连接队列中删除。注意,每次重传等待的时间不一定相同。
半连接存活时间:是指半连接队列的条目存活的最长时间,也即服务从收到SYN包到确认这个报文无效的最长时间,该时间值是所有重传请求包的最长等待时间总和。有时我们也称半连接存活时间为Timeout时间、SYN_RECV存活时间。
// ------------------------------------------------
21.3 往返时间测量
TCP超时与重传中最重要的部分就是对一个给定连接的往返时间(RTT)的测量。一般这个时间会变,TCP应该跟踪这些变化并相应的改变其超时时间。
(这一段有点难懂,先不看)
21.4 往返时间RTT的例子
并不是所有的报文段都被计时。
大多数源于伯克利的TCP实现在任何时候对每个连接仅测量一次RTT值,。在发送一个报文段时,如果给定连接定时器已经被使用,则该报文段不被计时,
对于每个连接而言,除了这个滴答计数器,报文段中的数据起始序号也被记录下来。当收到一个包含这个序号的确认后,该定时器就被关闭。如果ACK到达时数据没有被重传,则平滑的RTT和被平滑的均值偏差将基于这个新测量进行更新。
21.4.2 RTT估计器的计算
21.4.3 慢启动
21.5 拥塞举例
下面是报文段中数据的起始序号与该报文段发送时间的对比图。
通常代表数据的点将向上和向右移动,这些点的斜率代表传输速率。当这些点向下或向右移动测表示发生了重传。
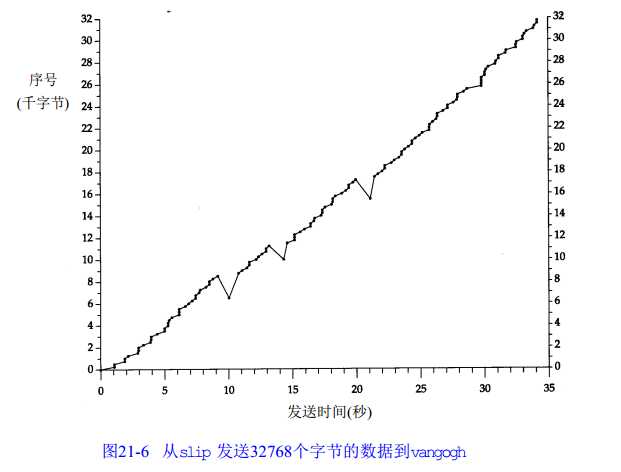
源于伯克利的TCP实现对收到的重复的ACK进行计数,,当收到第3个时,就假定一个报文段已经丢失并重传自那个序号起的一个报文段。这就是Jacobson的快速重传算法
21.6 拥塞避免算法
拥塞避免算法是一种处理丢失分组的方法。
该算法假定由于分组收到损坏引起的丢失是非常少的(远小于1%),因此分组丢失就意味着在源主机和目的主机之间的某处网络上发生了拥塞。有两种分组丢失的指示:发生超时和接收到重复的确认。
拥塞避免算法和慢启动算法是两个目的不同,独立的算法、当发生拥塞时,我们希望降低分组进入网络的传输速率,于是可以调用慢启动来做到这一点,在实际中这两个算法通常在一起实现。
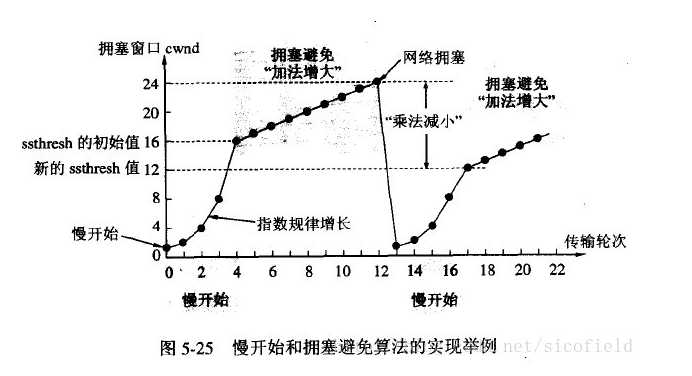
这两个算法需要对每个连接都维持两个变量:一个拥塞窗口cwnd,和一个慢启动门限ssthresh。具体工作过程如下:
1) 对于一个给定的连接,初始化cwnd为一个报文段,ssthresh为65535个字节。
2) TCP输出例程的输出不能超过cwnd和接收方通告窗口的大小。拥塞避免是发送方使用的流量控制(发送方感受到网络拥塞的估计),通告窗口是接收方进行的流量控制(与接收方在该该连接上可用的缓存大小有关。)
3) 当拥塞发生时(超时或收到重复确认),ssthresh被设置为当前窗口大小的一半(当前窗口是指cwnd和接收方通告窗口大小的最小值,但是最少为两个报文段)。此外,如果是超时引起了拥塞,则cwnd被设置为1个报文段(这就是慢启动)。
4) 当新的数据被对方确认时,就增加cwnd。但是增加的方法依赖于我们是否正在进行慢启动或拥塞 避免。如果cwnd小于等于ssthresh,则正在进行慢启动,否则正在进行拥塞避免。慢启动一直持续到我们回到当拥塞发生是所处位置的半时候才停止,然后转为执行拥塞避免。
慢启动算法初始值cwnd为1个报文段,此后每收到一个确认就加一。这会使窗口按指数方式增长:发生一个报文段,然后是2个,再然后是4个。(指数增长)
拥塞避免算法要求每收到一个确认时将cwnd增加1/cwnd.这是一种加性增长(additive increase)。我们希望在一个往返时间内最多为cwnd增加一个报文段,然后慢启动将根据这个往返时间中所收到的确认个数来增加cwnd,
术语慢启动并不完全正确。它只是采用了比引起拥塞更慢些的分组传输速率,但是在慢启动期间进入网络的分组数增加的速率仍然是在增加的。只有在的达到ssthresh拥塞避免算法起作用时,这种增长的速率才会慢下来。
// ++++++++++++++++++++++++++++++++++
下面是一篇博客里面的东西:http://blog.csdn.net/smilesundream/article/details/71149434
为了防止cwnd增长过大引起网络拥塞,还需设置一个慢启动门限ssthreah, ssthreah用法如下:
1) 当cwnd < ssthreah:这时候用慢启动算法
2) 当cwnd > ssthreah:使用拥塞避免算法
3) 两者相等时,慢启动和拥塞避免算法任意
拥塞避免算法让拥塞窗口缓慢增长。每经过一个往返时间RTT就把发送方的拥塞窗口cwnd加1,这样就是线性缓慢增长的。
无论是在慢启动阶段还是拥塞避免阶段,只要发生方判断网络出现了拥塞(没有收到确认或收到重复确认),就把慢启动门限设为出现拥塞时发送窗口大小的一半。然后把拥塞窗口设置为1.算法如下:
// -------------------------------------------------------
21.7 快速重传与快速恢复算法
收到重复的确认ack就需要立即重传丢失的数据报文段,而无需等待超时定时器溢出。接下来执行的不是慢启动算法,而是拥塞避免算法,这就是快速恢复算法。
具体如下:
1) 在收到第三个重复的ACK时,1的报文段。设置cwnd为ssthresh加上3倍的报文段大小
2) 每次收到一个重复的ack,cwnd增加一个报文段 大小,并发送一个分组。
3) 当下一个确认新数据的ack到达时,设置cwnd为ssthresh(第一步设置的值)。这个ack应该是在进行重传后的一个往返时间内对步骤1中重传的确认。另外,这个ack也应该是对 丢失的分组和收到的第一个重复的ack之间的所有中间报文段的确认。
// 下面是一篇博客的内容。好像有点差异。不过都是快重传和快恢复(cwnd和ssthresh值设的不一样)
http://blog.csdn.net/smilesundream/article/details/71149434
快重传:接收方在收到一个失序的报文后立即发送重复确认,不需要等自己发送数据时捎带确认。
快重传算法规定:发送方只要一连收到3个重复确认就应答立即重传对方 尚未收到的报文段,而不必继续等待设置的重传定时器时间到期。
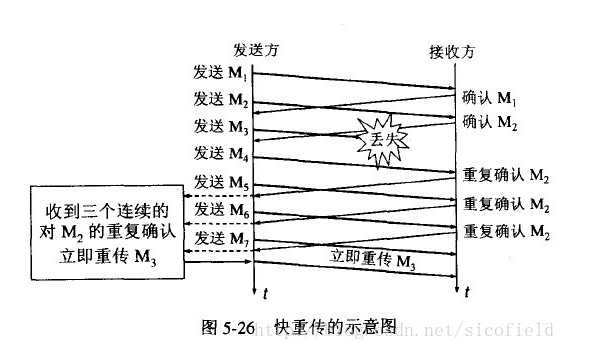
快速恢复,有以下要点:
1) 发送方连续收到三个重复确认时,执行“乘法减小”算法,把ssthresh门限减半。
2) 不执行慢启动算法,而是执行拥塞避免算法。(具体如何设置cwnd和ssthresh还是看书上的靠谱一点。)
// -------------------------------------------------------------------
21.8 拥塞举例
分析一个快发送快启动的例子:
一个快速重传算法,ssthresh立即设置为当重传发生时正在起作用窗口大小的一半,但是在收到重复ACK的过程中cwnd允许保持增加,这是因为每个重复的ACK 表示一个报文段已经离开了网络,这就是快速恢复算法。
20.9 按每条路由进行度量
较新的TCP实现在啊路由表项中维持许多我们在本章已经介绍过的指标。
当一个TCP连接关闭时,如果已经发送了足够多的数据来获得有意义统计资料,且目的节点的路由表项不是一个默认的表项,那么下列信息就保存在路由表项中以备下次使用:被平滑的RTT、被平滑的均值偏差以及慢 启动门限
当建立一个新的连接时,不论是主动还是被动,如果该连接将要使用的路由表项已经有这些度量的值,则用这些度量来对相应的变量进行初始化。
21.10 ICMP差错
来看看TCP是怎样处理一个给定的连接返回的ICMP的差错。TCP能够遇到的最常见的ICMP差错就是源站抑制,主机不可达,和网络不可达。
当前基于伯克利的实现对这些错误的处理是:、
1) 一个接收到的源站抑制引起拥塞窗口cwnd设置为1个报文段大小来发起慢启动,但是慢启动门限ssthresh没有变化,所以窗口将打开直至它或者开放了所有的通路或者发生了拥塞。
2) 一个接收到的主机不可达或网络不可达实际上都被忽略,因为这个差错都被认为是短暂现象。
当前基于伯克利的实现记录发生的ICMP差错,如果连接超时,ICMP差错被转换为一个更合适的差错码而不是“连接超时 ”。
21.11 重新分组
当TCP超时并重传时,它不一定要重传相同的报文段。相反,TCP允许进行重新分组而发送一个较大的报文段,这有助于提高性能。
在协议中这是允许的,因为TCP是使用字节序号而不是报文段序号来识别 它所要发送的数据和进行确认。