爬虫基础知识
Posted 404noofound
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫基础知识相关的知识,希望对你有一定的参考价值。
查看网页请求
以chrome浏览器为例,在网页上点击鼠标右键,检查(或者直接F12),选择network,刷新页面,选择ALL下面的第一个链接,这样就可以看到网页的各种请求信息。
请求头(Request Headers)信息详解:
Accept: text/html,image/*(浏览器可以接收的类型)
Accept-Charset: ISO-8859-1(浏览器可以接收的编码类型)
Accept-Encoding: gzip,compress(浏览器可以接收压缩编码类型)
Accept-Language: en-us,zh-cn(浏览器可以接收的语言和国家类型)
Host: www.it315.org:80(浏览器请求的主机和端口)
If-Modified-Since: Tue, 11 Jul 2000 18:23:51 GMT(某个页面缓存时间)
Referer: http://www.it315.org/index.jsp(请求来自于哪个页面)
User-Agent: Mozilla/4.0 (compatible; MSIE 5.5; Windows NT 5.0)(浏览器相关信息)
Cookie:(浏览器暂存服务器发送的信息)
Connection: close(1.0)/Keep-Alive(1.1)(HTTP请求的版本的特点)
Date: Tue, 11 Jul 2000 18:23:51 GMT(请求网站的时间)
响应头(Response Headers)信息详解:
Location: http://www.it315.org/index.jsp(控制浏览器显示哪个页面)
Server:apache tomcat(服务器的类型)
Content-Encoding: gzip(服务器发送的压缩编码方式)
Content-Length: 80(服务器发送显示的字节码长度)
Content-Language: zh-cn(服务器发送内容的语言和国家名)
Content-Type: image/jpeg; charset=UTF-8(服务器发送内容的类型和编码类型)
Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT(服务器最后一次修改的时间)
Refresh: 1;url=http://www.it315.org(控制浏览器1秒钟后转发URL所指向的页面)
Content-Disposition: attachment; filename=aaa.jpg(服务器控制浏览器发下载方式打开文件)
Transfer-Encoding: chunked(服务器分块传递数据到客户端)
Set-Cookie:SS=Q0=5Lb_nQ; path=/search(服务器发送Cookie相关的信息)
Expires: -1(服务器控制浏览器不要缓存网页,默认是缓存)
Cache-Control: no-cache(服务器控制浏览器不要缓存网页)
Pragma: no-cache(服务器控制浏览器不要缓存网页)
Connection: close/Keep-Alive(HTTP请求的版本的特点)
Date: Tue, 11 Jul 2000 18:23:51 GMT(响应网站的时间)
理解网页请求过程
从浏览器输入网址、回车后,到用户看到网页内容,经过的步骤如下:
(1)dns解析,获取ip地址;
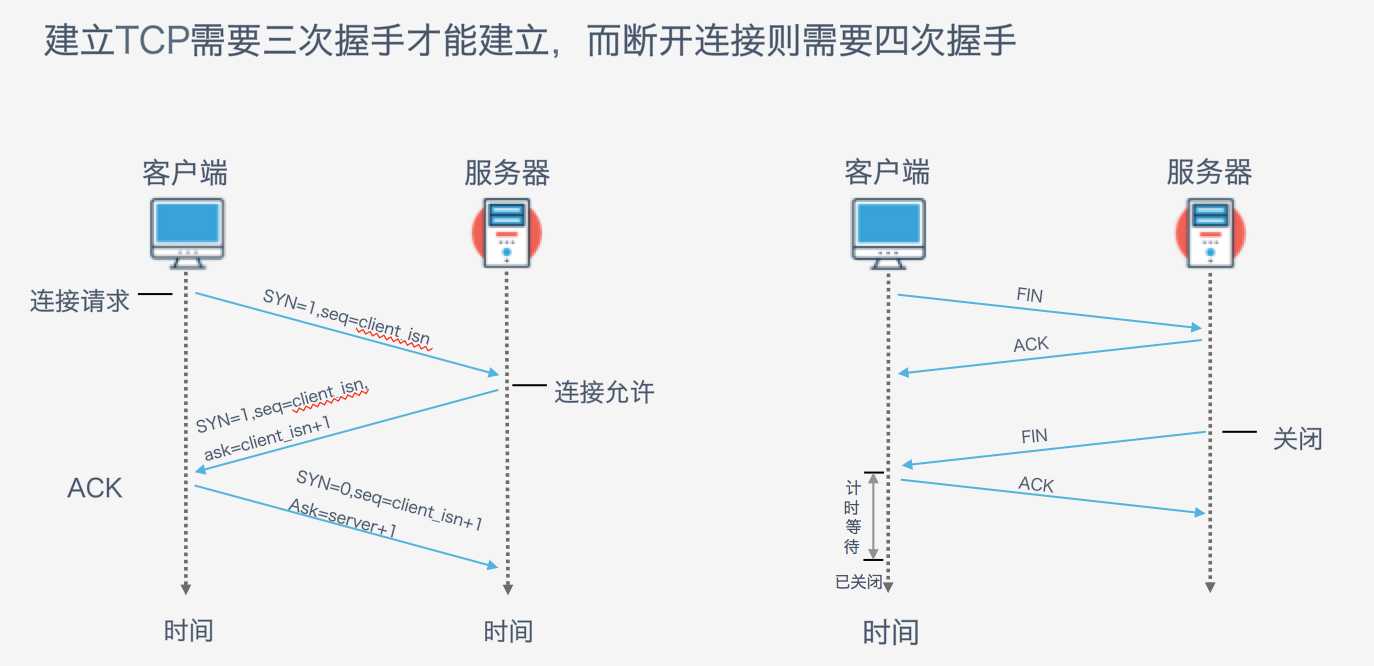
(2)建立TCP连接,3次握手;
(3)发送HTTP请求报文;
(4)服务器接收请求并作处理;
(5)服务器发送HTTP响应报文;
(6)断开TCP连接,4次握手。
通用的网络爬虫框架
1.挑选种子URL;
2.将这些URL放入待抓取的URL队列;
3.取出待抓取的URL,下载并存储进已下载网页库中。此外,将这些URL放入待抓取URL队列,从而进入下一循环;
4.分析已抓取队列中的URL,并且将URL放入待抓取URL队列,从而进入下一循环。
以上是关于爬虫基础知识的主要内容,如果未能解决你的问题,请参考以下文章