一、前言
这一篇里,我将对HashSet、LinkedHashSet、TreeSet进行汇总分析,并不打算一一进行详细介绍,因为JDK对Set的实现进行了取巧。我们都知道Set不允许出现相同的对象,而Map也同样不允许有两个相同的Key(出现相同的时候,就执行更新操作)。所以Set里的实现实际上是调用了对应的Map,将Set的存放的对象作为Map的Key。
二、源码分析
这里笔者就以最常用的HashSet为例进行分析,其余的TreeSet、LinkedHashSet类似,就不赘述了。
2.1 结构概览
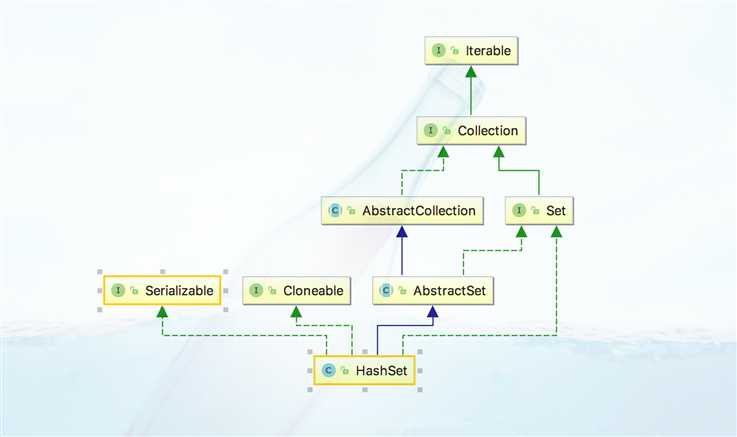
关系也很简单,实现了Set的接口,继承了AbstractSet抽象类,抽象类里面定义了集合的常见操作,与我们之前分析过的ArrayList之类的相似。
2.2 成员变量
// HashMap就是HashSet里实现具体操作的对象
private transient HashMap<E,Object> map;
// 将对象作为Value存进去
private static final Object PRESENT = new Object();由于使用Map进行操作,把E作为Key,要定义一个PRESENT对象作为Value,每个存入的对象都使用它来作为Value。
2.3 构造方法
2.3.1 HashSet()
public HashSet() {
map = new HashMap<>();
}看了这个,相信园友们应该就知道它是怎么实现的了,我们平时构建HashSet的时候,其实它是在里面new了一个HashMap。
2.3.2 HashSet(Collection<? extends E> c)
public HashSet(Collection<? extends E> c) {
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}调用传集合的构造方法则是使用了HashMap里指定初始化容量的构造方法,然后再调用addAll()。
public boolean addAll(Collection<? extends E> c) {
boolean modified = false;
for (E e : c)
if (add(e))
modified = true;
return modified;
}addAll方法很简单,其实就是遍历集合c,然后调用add方法,实现插入HashMap。
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}add方法则是调用了map的put()方法,将对象作为Key,之前域里的PRESENT作为Value,插入到HashMap中。
2.3.3 HashSet(int initialCapacity, float loadFactor, boolean dummy)
最后值得一提的是这个构造方法:
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}注意它是包访问权限的,而不是public,因为这个构造方法是提供给LinkedHashSet使用的,所以里面初始化的也是LinkedHashMap,有兴趣的园友们也可以去LinkedHashSet里看一下它的构造方法。
三、Set的使用注意事项
笔者前端时间恰好碰到了因为HashSet的底层事项导致的一个bug,在此跟大家分享一下:
/**
* @author joemsu 2018-02-04 上午10:33
*/
public class UserInfo {
private Long id;
private String name;
private Integer age;
public UserInfo(Long id, String name, Integer age) {
this.id = id;
this.name = name;
this.age = age;
}
public void setName(String name) {
this.name = name;
}
@Override
public String toString() {
return "UserInfo{" +
"id=" + id +
", name='" + name + '\\'' +
", age=" + age +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
UserInfo info = (UserInfo) o;
return Objects.equals(id, info.id) &&
Objects.equals(name, info.name) &&
Objects.equals(age, info.age);
}
@Override
public int hashCode() {
return Objects.hash(id, name, age);
}
}UserInfo为当时笔者要处理的一个pojo对象,由第三方提供,重写了equals和hashCode方法(当时没有发现)。而笔者当时要获取所有的UserInfo对象,放入集合当中进行复杂的逻辑处理,出于可能出现重复对象的考虑(使用递归遍历不同部门下的人员信息,可能存在一个人在多个部门),选择使用HashSet。然后在遍历HashSet集合a的时候,会将每个遍历到的对象加入另一个集合b作记录,事后会将a,b做一个差集,取出其中没有访问到的元素。这个过程中可能会涉及到更新某个对象,具体过程简化如下:
public static void main(String[] args) {
// 将对象加入set
UserInfo info1 = new UserInfo(1L, "zhangsan", 22);
UserInfo info2 = new UserInfo(2L, "lisi", 23);
UserInfo info3 = new UserInfo(3L, "wangwu", 24);
Set<UserInfo> userInfoSet = new HashSet<>();
userInfoSet.add(info1);
userInfoSet.add(info2);
userInfoSet.add(info3);
// 对访问到的元素加入集合
List<UserInfo> visited = new ArrayList<>();
visited.add(info1);
visited.add(info2);
visited.add(info3);
// 假设对其中一个对象进行修改
info1.setName("liliu");
// 去掉访问过的元素
userInfoSet.removeAll(visited);
userInfoSet.stream().forEach(System.out::println);
}最后的输出结果:
UserInfo{id=1, name='liliu', age=22}是的,所有修改过的元素都无法移除。当笔者通过debug发现这一现象后立刻就意识到,可能就是hashCode导致被修改过的元素无法访问到,为什么呢,我们可以回顾一下HashMap的remove操作:
final Node<K,V> removeNode(int hash, Object key, Object value,
boolean matchValue, boolean movable) {
Node<K,V>[] tab; Node<K,V> p; int n, index;
if ((tab = table) != null && (n = tab.length) > 0 &&
(p = tab[index = (n - 1) & hash]) != null) {
// 省略
}
return null;
}在HashMap中,是通过Key的hash值来定位桶的位置,当笔者修改了对象的name属性之后,由于重写的hashCode方法里包括了name这一字段,所以,hash值也发生了改变,导致在对应的桶里找不到该对象,也就无法实现remove操作(虽然两个是同一个引用)。
四、总结
Set的各种底层实现都是对应的Map,熟悉了Map里的各种方法,相信对于Set的了解也会更加深入。最后谢谢各位园友观看,如果有描述不对的地方欢迎指正,与大家共同进步!