一. 一个.py文件批量执行测试用例(一个.py文件下多个用例执行)
如果直接使用:unittest.main(),则按字母顺序执行,
对于前后之间又依赖关系的用例,需要按特定的顺序执行,则使用 suite.addTest(类名("方法名")),如这里按照新增,修改,删除的顺序,可以避免执行完毕后的测试数据处理。

def test_modifyCategory(self): ...
def test_addCategory(self): ...
def test_delCategory(self): ...
if __name__=="__main__": #unittest.main() suite=unittest.TestSuite() suite.addTest(test_category("test_addCategory"))
suite.addTest(test_category("test_modifyCategory"))
suite.addTest(test_category("test_delCategory"))
二.单个.py文件如何生成html测试报告
(下载 HTMLTestRunner.py文件,放到 python安装包的 lib 目录下,打开IDLE ,输入 " import HTMLTestRunner "若不报错,则说明导入成功)
1.在测试报告名中显示时间:(引入time包) now=time.strftime("%Y-%m-%d-%H_%M_%S",time.localtime(time.time()))
time.time():获取当前时间戳
time.ctime():获取当前时间的字符串
time.localtime():当前时间的struct_time形式
time.strftime("%Y-%m-%d-%H_%M_%S",time.localtime()):获取特定格式的时间,通常用这个
2.TestSuite是个容器,往里面用addTest()添加测试用例
3.fielname定义报告保存的路径以及文件名
file是file类的构造函数,file(name[, mode[, buffering]])
file()函数用于创建一个file对象,它有一个别名叫open(),它们是内置函数。来看看它的参数。它参数都是以字符串的形式传递的。
name是文件的名字。mode是打开的模式,可选的值为r w a U,分别代表读(默认) 写 添加支持各种换行符的模式。
用w或a模式打开文件的话,如果文件不存在,那么就自动创建。
此外,用w模式打开一个已经存在的文件时,原有文件的内容会被清空因为一开始文件的操作的标记是在文件的开头的,这时候进行写操作,无疑会把原有的内容给抹掉。
在模式字符的后面,还可以加上+ b t这两种标识,分别表示可以对文件同时进行读写操作和用二进制模式、文本模式(默认)打开文件。
这里常用的为 file(filename,‘wb‘):以二进制形式打开文件 filename
4.runner定义测试报告格式,stream定义报告写入的二进制文件,title为报告的标题,description为报告的说明,runner.run()用来运行测试case,注意最后用fp.close()将文件关闭!!
5.添加测试用例的中文注释: 在每个测试方法后面添加: u""" 测试用例中文说明 """ 即可!!!!!!
if __name__=="__main__":
#unittest.main()
suite=unittest.TestSuite()
suite.addTest(test_category("test_addCategory"))
suite.addTest(test_category("test_modifyCategory"))
suite.addTest(test_category("test_delCategory"))
now=time.strftime("%Y-%m-%d-%H_%M_%S",time.localtime(time.time()))
filename=‘C:\\\\Users\\\\DELL\\\\Desktop\\\\2.a .py a report\\\\‘+now+"category.html"
fp=file(filename,"wb")
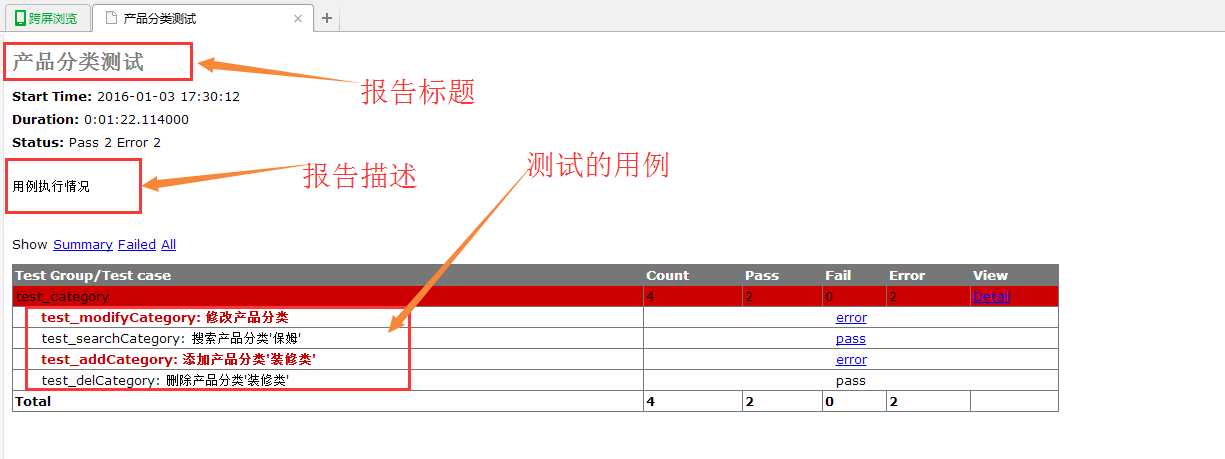
runner=HTMLTestRunner.HTMLTestRunner( stream=fp, title=u"产品分类测试", description=u"用例执行情况")
runner.run(suite)
fp.close()
测试报告效果图如下:
三.多个.py文件如何执行,如何生成一个测试报告,结构优化
测试报告优化思路:(1)所有的测试用例(包括共通是登录)放到用例文件夹下(2)执行用例的py文件单独列出 (3) 所有生成的报告放到Report文件夹下

文件结构如下:新建一个__init__.py文件(注意是双下划线,里面导入所有的用例),和所有的测试案例一起放到 test_case文件夹下

新建一个 test_all.py执行文件,代码如下:
#coding=utf-8
import sys
sys.path.append("\\test_case")
from test_case import *
import unittest
import HTMLTestRunner
import time
#注意使用套件时,在单个py文件中下的多个用例用 (类名("方法名")),
#导入多个py的类下,用(py名.类名)
suite=unittest.TestSuite()
suite.addTest(unittest.makeSuite(category.test_category))
suite.addTest(unittest.makeSuite(product.test_product))
now=time.strftime("%Y-%m-%d-%H_%M_%S",time.localtime(time.time()))
filename=‘C:\\\\Users\\\\DELL\\\\Desktop\\\\Report\\\\‘+now+"test_all.html"
fp=file(filename,‘wb‘)
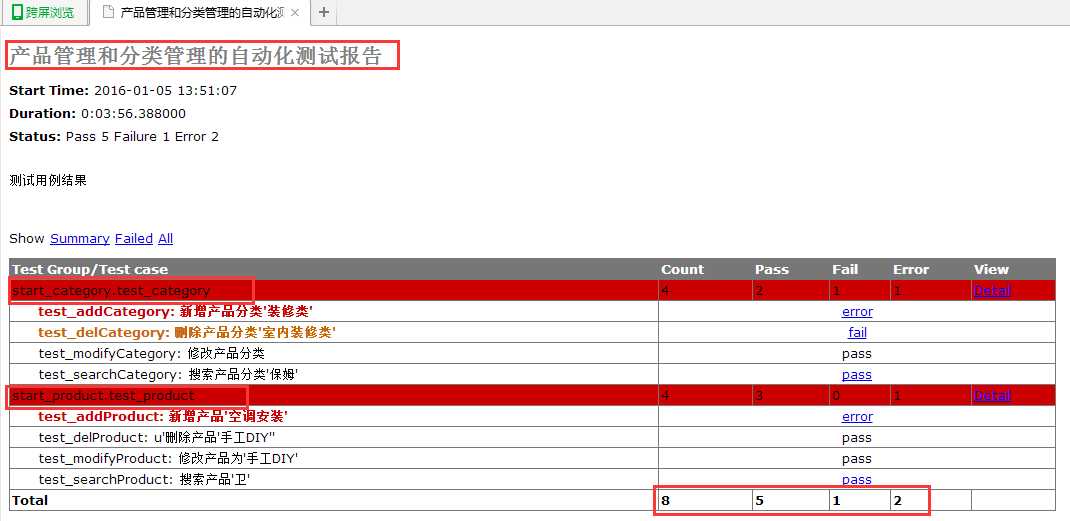
runner=HTMLTestRunner.HTMLTestRunner(stream=fp,title=u‘产品管理和分类管理的自动化测试报告‘,description=u‘测试用例结果‘)
runner.run(suite)
fp.close()
1.如果不创建__init__.py文件,用例执行的py文件将找不到引入的包,这里我们来普及一下包的导入过程中执行了什么操作:
(1)创建一个新的,空的module(类)对象
(2)将该对象加入到sys(系统)的module(类)中
(3)装载加入的module,此时会现在当前目录下寻找,后在python的path中寻找,而创建引用__init__.py 是为了标识它所在的文件夹(目录)是可引用的module!!!!!
2.把模块的路径通过sys.path.append(路径)添加到程序中,这里使用的是相对路径: \\用例所在文件夹
3.当重新添加一个py文件一起执行时,需要两个地方改动:
(1)首先需要在 __init__.py文件下引入该py
(2)在用例执行的文件(test_all.py)下使用: suite.addTest(unittest.makeSuite(py名.类名)) 将此文件下的用例添加上去并执行!!!!!
第一步简化:使用数组进行loop
all=[category.test_category,product.test_product]
suite=unittest.TestSuite()
for a in all:
suite.addTest(a)
第二步简化:将上述操作专门写到一个py文件中,直接调用
第三步简化:实现自动查找用例文件夹下的py文件,自动添加到addTest中,(只需在__init__.py中导入包即可),不用每次都两个地方进行设置!!!!!!!
实现思路如下:
使用TestLoader:测试用例加载器,可以加载多个测试用例,返回一个测试套件
discover=unittest.defaultTestLoader.discover(allcase,pattern=‘start_*.py‘,top_level_dir=None) 找到指定目录下的指定的测试模块,如果不在顶级目录下,需要指定。
实现代码如下:
#coding=utf-8
import sys
import unittest
import HTMLTestRunner
import time,os
#注意使用套件时,在单个py文件中下的多个用例用 (类名("方法名")),
#导入多个py的类下,用(py名.类名)
allcase=‘C:\\\\Users\\\\DELL\\\\Desktop\\\\test_casea‘ #指明要自动查找的py文件所在文件夹路径
def createSuite(): #产生测试套件
testunit=unittest.TestSuite()
#使用discover找出用例文件夹下test_casea的所有用例
discover=unittest.defaultTestLoader.discover(allcase, #查找的文件夹路径
pattern=‘start_*.py‘, #要测试的模块名,以start开头的.py文件
top_level_dir=None) #测试模块的顶层目录,即测试用例不是放在多级目录下,设置为none
for suite in discover: #使用for循环出suite,再循环出case
for case in suite:
testunit.addTests(case)
print testunit
return testunit
allcasenames=createSuite()
now=time.strftime("%Y-%m-%d-%H_%M_%S",time.localtime(time.time()))
filename=‘C:\\\\Users\\\\DELL\\\\Desktop\\\\Report\\\\‘+now+"test_all.html"
fp=file(filename,‘wb‘)
runner=HTMLTestRunner.HTMLTestRunner(stream=fp,title=u‘产品管理和分类管理的自动化测试报告‘,description=u‘测试用例结果‘)
runner.run(allcasenames) #执行case
fp.close()
可以看到运行结果如下:
四.问题汇总
截止到现在,涉及测试报告的所有内容介绍完毕,下面介绍一下上述过程中遇到的问题:
1.element not visible :页面上有两个结构类似的元素
解决方法:使用全路径的xpath(或者是往前定位,直到能区分出元素1和元素2)
2.搜索结果的数量为空,一定要在点击搜索按钮前后都设置等待,设置等待很重要!!!!!
3.新增产品时有多个下拉框选择,导致上一个选择后使下一个被覆盖,无法点击,
解决方法: 刚开始使用ul/li的定位方式时由于点两次,第一项点击后的覆盖到第二项导致第二项不可见,所以此方法导致部分项下拉选中失败为空!!
所以对于select的最好使用 Select(driver.find_element_by_id("gender")).select_by_value("2") ,注意导入包
from selenium.webdriver.support.ui import Select
下面说一下两种下拉框:下拉框分为两种
(1)select下时option的
from selenium.webdriver.support.ui import Select
...
# 通过index进行选择
Select(driver.find_element_by_id("gender")).select_by_index(1)
# 通过value进行选择
Select(driver.find_element_by_id("gender")).select_by_value("2")
# 通过选项文字进行选择
Select(driver.find_element_by_id("gender")).select_by_visible_text("Male")
注:Select only works on <select> elements(Select只对<select>标签的下拉菜单有效).
(2)ul下的li
定位非<select>标签的下拉菜单中的选项,需要两个步骤,先定位到下拉菜单,再对其中的选项进行定位。
定位代码(选择硕士):
# 先定位到下拉菜单
drop_down = driver.find_element_by_css_selector("div#select2_container > ul")
# 再对下拉菜单中的选项进行选择
drop_down.find_element_by_id("li2_input_2").click()
注:也可以用此方法定位<select>标签的下拉菜单。
4.生成报告为空(python在安装时,默认的编码是ascii,当程序中出现非ascii编码时,python的处理常常会报这样的错)
UnicodeDecodeError: ‘ascii‘ codec can‘t decode byte 0xe5 in position 97: ordinal not in range(128)
在python的Lib\\site-packages文件夹下新建一个sitecustomize.py,内容为:
Python代码
# encoding=utf8
import sys
reload(sys)
sys.setdefaultencoding(‘utf8‘)
此时重启python解释器,执行sys.getdefaultencoding(),发现编码已经被设置为utf8的了,多次重启之后,效果相同,这是因为系统在python启动的时候,自行调用该文件,设置系统的默认编码,而不需要每次都手动的加上解决代码,属于一劳永逸的解决方法。
截止到现在,总结一下自动化测试的思路与文件架构:
1.设计测试case: (按照正向思维,每个用例必须形成一个完整的流程,包括浏览器执行case,然后关闭)
分类管理为一个.py文件:里面包含4个用例(搜索,新增,修改,删除),按此执行顺序可以减少对测试数据的后续处理(如新增的需要进行删除),产品管理以此类推,此时有两个py文件。
.py文件的优化:
(1)登录模块化,直接在setUp方法中引用即可
(2)所有的共用模块都放到setUp方法中,直到登录到要测试的页面
2.一共需要三个文件夹:
测试用例文件夹:放所有的.py文,且有用例的py文件以start开头,并新增一个__init__.py文件
报告执行文件夹:使用discover对用例进行loop,测试报告设置
测试报告:专门放每天执行的文件测试报告