爬虫原理和网页构造
Posted wuxingqueshui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫原理和网页构造相关的知识,希望对你有一定的参考价值。
网络连接像是在自助饮料售货机上购买饮料一样:购买者只需选择所需饮料,投入硬币(或纸币),自助饮料售货机就会弹出相应的商品。网络连接也正是如此,如下图所示,本机电脑(购买者)带着请求头和消息体(硬币和所需饮料)向服务器(自助饮料售货机)发起一次Requests请求(购买),相应的服务器(自助饮料售货机)会返回本机电脑相应的html文件作为Response(相应的商品)。
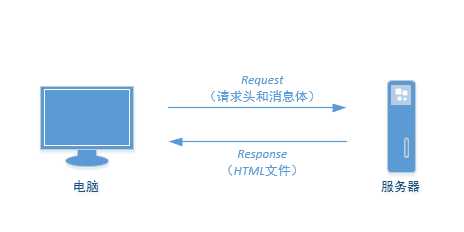
了解网络连接的基本原理后,爬虫原理就很好理解了。网络连接需要电脑一次Requests请求和服务器端的Response回应。爬虫也是需要二件事:
(1)模拟电脑对服务器发起Requests请求。
(2)接收服务器端的Response的内容并解析提取所需信息。
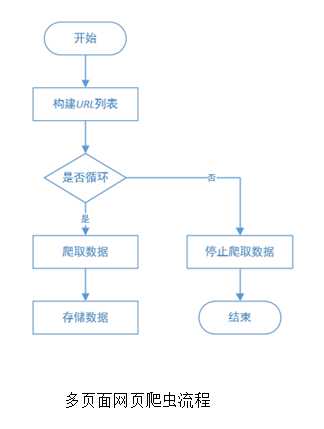
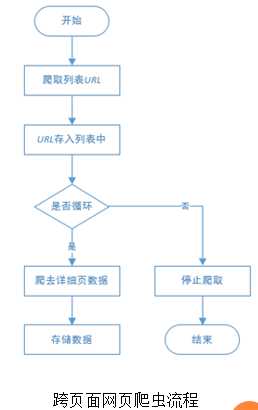
现在任意打开一个网页(http://www.anjuke.com/),标右击空白处,在弹出的快捷菜单中选择“检查”命令,可以看到网页的代码,如图所示。
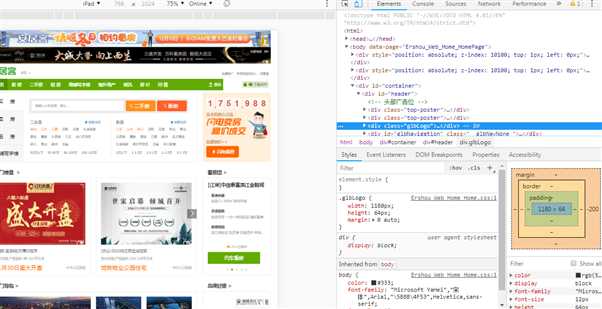
分析这个图,上半部分为HTML文件,下部分为CSS样式,用<script></script>标签的就是javascript。用户浏览的网页就是浏览器渲染后的结果,浏览器就像翻译官,把HTML、CSS和JavaScript进行翻译得到用户使用的网页界面。
右击网页空白处,从快捷菜单中选择“查看网页源代码”命令,即可查看该网页的源代码,如图所示。
以上是关于爬虫原理和网页构造的主要内容,如果未能解决你的问题,请参考以下文章