通过AI自学习,Google让Pixel 3的人像模式更优秀
Posted xiexiaokui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了通过AI自学习,Google让Pixel 3的人像模式更优秀相关的知识,希望对你有一定的参考价值。
通过AI自学习,Google让Pixel 3的人像模式更优秀
Link: https://news.cnblogs.com/n/613720/

虽然双摄手机已经在市场上普及,其所带来的人像模式、多倍变焦也成为了不少智能手机的「标配」,但仍然有厂商依然坚持用一个摄像头的配置。

比如以软件著称的 Google,从 Pixel 手机的初代到今天的 Pixel 3 / 3XL,在往今的两年时间里(初代 Pixel 于 2016 年发布),他们仍坚持采用单摄配置。
有意思的是,Pixel 不但是 DxOMark 榜单前列的常客,夜景表现长期吊打各旗舰, 而且还带来了比双摄出品更优秀的人像模式出品。
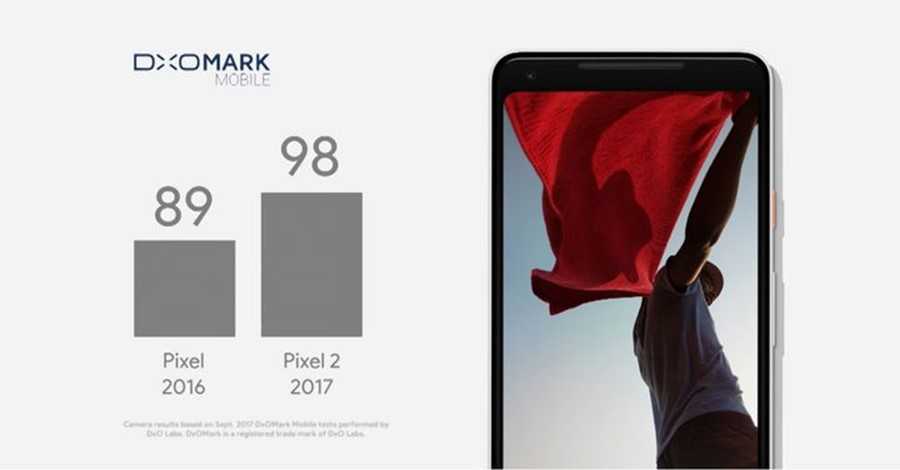
这些其实都是要归功于软件算法和 AI 神经网络。昨天,Google 就在他们的 Google AI Blog 上解析了 Pixel 3「人像模式」(Portrait Mode)的算法原理。实际上,他们在这套算法上下了不少功夫。
Google 的算法原理
如果你对 Google 的相机算法陌生,不妨先来了解一下 Pixel 2 的人像算法原理。
去年,Google 通过 AI(神经网络)算法,让 Pixel 2 / 2XL 在仅一颗摄像头的硬件条件下,拍出能与双摄手机媲美的人像背景虚化照片。

▲ 图片来自:Google
通过去年 Google?公布的这组对比图,我们能快速区分出左边的 HDR+ 样张和右边 Portrait Mode「人像模式」下的样张在背景虚化上的不同。
正如你所见那样,在「人像模式」下,人像后的背景被进行了软件虚化处理,与正常 HDR+ 对比看上去视觉冲击更强,同时也避免了背景对拍摄主体的视觉干扰。
- 拍摄一张 HDR+ 照片
根据 Google 去年在 AI Blog 的介绍,Pixel 2 的相机会先拍摄一组 HDR+ 照片,通过多帧合成,从而提升最终成片的动态范围、细节保留、高光表现。
通过下面这组 HDR+ 的对比图,我们能看到该功能在开启前后的区别(注意右上角远景曝光及地板线条细节)。

▲ 左:HDR+ 前;右:HDR+ 后图片来自:Google
- 分割远近景
如果你想拍摄一张「人像模式」照片,那么在得到一张 HDR+ 成片后,相机会使用 TensorFlow 的 AI 神经网络将人物像素点、物体的像素点、远近物的像素点筛选出来。

Google 在 AI Blog 给出的这组对比图能看到更直观的展示效果:
左边是 HDR+ 拍摄的原图,右边黑色部分是 AI 识别出来的背景部分,白色部分是被识别出来的主体人物轮廓(包括人物五官细节以及在该轮廓内的物体)。

有意思的是,从最终成片中我们能看到,桌上的饼干在 AI 识别下是属于「非人」部分,但最终这部分没有被虚化。这是因为系统除了将主体和背景识别出来以外,还识别出了主体周边的物体,因此 AI 最终没有将人物下方的物体虚化。因为这部分虽然不属于对焦主体,属于近景,但是这种效果还不是最完美的。
- 得到深度优化图并合成最终成片
虽然去年的 Pixel 2 和今年的 Pixel 3 系列都没有配置双摄像头,但 Google 似乎一直都不是以硬件取胜的公司,他们更擅长于用软件和算法去解决问题。
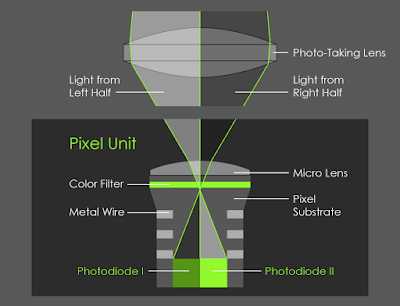
▲ 图片来自:Google
尽管没有硬件上的双摄,但 Pixel 的相机都配备了 PDAF 双核相位对焦技术,Google 便可以通过像素点划分将一颗摄像头「一分为二」:
镜头左侧拍摄到的画面会和右侧的画面约有 1mm 的不同视觉间距,如果是在纵向拍摄下,镜头则是分为上下两部分排列。
在拍摄后,系统会并排两侧镜头拍摄到的像素。通过 Google 自家的 Jump Assembler 算法去得出立体演算的深度优化图,利用双向求解器将深度图转变成高解析度。

▲ 图 1 、2 为上半部分、下半部分相机拍摄,图 3 动图为前面两图区别图片来自:Google

上图左边是通过 PDAF 拍摄并演算得到的深度图,白色部分越深,代表与镜头距离越近;右边是决定像素模糊程度,黑色部分为「不需模糊」范围,红色部分为「需模糊范围」,通过红色的深浅,系统会自动判断出背景虚化的力度。

▲ 最终效果图
最后系统会将第 2 步骤分割出的背景图和第 3 步骤得出的深度图合并。在 AI 物体的判别下,系统能估算出近景的饼干和瓷盘到对焦(人物)主体的距离,并进行虚化。最终得到了比步骤 2 的初级处理更全面和自然的人像照片。
对比步骤 2 和步骤 3 最终的效果图,你能看到位于近景的饼干也被适当虚化了。通过软件算法,我们能将虚化范围「捏造」成任何形状。
Google 是怎样训练神经网络的?
了解了 Pixel 2 的人像模式原理,那么 Pixel 3 的优化就不难理解了。
通过软件算法,相机系统可大致估算出对焦主体和背景的距离,并对远景进行虚化。但在手持拍摄时,手机难免会出现轻微的抖动,因而影响到最终虚化效果。正是如此,此前有不少用户在 Pixel 2 系列上遇到了景深识别错误的问题。

根据 Google AI Blog 的介绍,基于神经网络学习的特性,在 Pixel 3 上,Google 正通过增加对 AI 系统的识别提示和训练 AI 神经网络的算法,去修复「人像模式」中的识别误差问题。
例如,通过像素点数量去判断物体与镜头的远近距离,得出给 AI 更精准的距离判断结果;或者通过对焦点内外的清晰情况,给 AI 提供散焦提示。

「Franken Phone」是 Google 用于训练由 TensorFlow 编写的神经网络系统的装置,这套装置由 5 台 Pixel 3 和 WiFi 组成。
在测试时,Google 会用 Franken Phone 里的 5 台手机在不同的角度同时拍摄,最终得出一张由多个角度、和立体算法合成的动态深度图。从而达到模拟拍摄动态、在复杂场景下训练神经网络精准识别出人物(近景)和背景(远景)的目的。

▲ 图一为 Google Franken Phone。图片来自:Google
当然,如果您对 Google 这套算法感兴趣,也可以自己动手去亲自研究他们。Google AI Blog?表示,在使用 Google Camera App 6.1 版本的「人像模式」拍摄后,通过 Google Photos 能查看照片的深度图了。
或者,您也可以通过第三方软件提取深度图,去看看在 AI 神经网络优化下识别方式。
以上是关于通过AI自学习,Google让Pixel 3的人像模式更优秀的主要内容,如果未能解决你的问题,请参考以下文章