京东JData算法大赛高潜用户购买意向预测——复现
Posted 1113127139aaa
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了京东JData算法大赛高潜用户购买意向预测——复现相关的知识,希望对你有一定的参考价值。
一、前言
完全是重现别人的过程,学习思路和处理方式,仅供记录,具体请看参考链接,更完善清晰
参考链接 http://izhaoyi.top/2017/06/25/JData/#%E6%95%B0%E6%8D%AE%E9%9B%86%E8%A7%A3%E6%9E%90
尝试重现别人的挖掘过程,学习别人的思路
二、具体过程
数据集介绍等前期信息可以看参考链接,或是算法大赛的官网,这里直接进行操作
数据预处理:
异常值判断
#文件名 #coding=utf-8 import matplotlib import matplotlib.pyplot as plt import numpy as np import pandas as pd ACTION_201602_FILE = "D:dataJData_Action_201602.csv" #读取数据 ACTION_201603_FILE = "D:dataJData_Action_201603.csv" ACTION_201604_FILE = "D:dataJData_Action_201604.csv" COMMENT_FILE = "D:dataJData_Comment.csv" PRODUCT_FILE = "D:dataJData_Product.csv" USER_FILE = "D:dataJData_User.csv" #USER_TABLE_FILE = "D:data User_table.csv" #ITEM_TABLE_FILE = "D:dataItem_table.csv"
判断是否空值
def check_empty(file_path,file_name): #判断是否存在空值 file = open(file_path) #直接用pd.read_csv会报错,因此先用file open df_file = pd.read_csv(file) print(‘判断missing value in {0},{1}‘.format(file_name,df_file.isnull().any().any())) ‘‘‘ isnull()判断是否空值,但是直接使用的话得到的是一个矩阵, 因此用.any()得到每列是否存在空值的情况, 再使用.any()得到整个文件是否存在空值的情况 ‘‘‘
check_empty(USER_FILE,‘user‘) check_empty(ACTION_201602_FILE,‘Action 2‘) check_empty(ACTION_201603_FILE,‘Action 3‘) check_empty(ACTION_201604_FILE,‘Action 4‘) check_empty(COMMENT_FILE,‘Comment‘) check_empty(PRODUCT_FILE,‘Product‘)
得到结果
判断missing value in user,True 判断missing value in Product,False 判断missing value in Action 2,True 判断missing value in Action 3,True 判断missing value in Action 4,True 判断missing value in Comment,False
查看每个表空值的情况,也就是列列空值情况
def empty_detail(file_path,file_name): file = open(file_path) df_file = pd.read_csv(file) print(‘空值详细信息 of {0}‘.format(file_name)) print(pd.isnull(df_file).any()) #.any()查看列情况 empty_detail(USER_FILE,‘User‘) empty_detail(ACTION_201604_FILE,‘Action 2‘) empty_detail(ACTION_201603_FILE,‘Action 3‘) empty_detail(ACTION_201602_FILE,‘Action 4‘)
得到结果
空值详细信息 of User user_id False age True sex True user_lv_cd False user_reg_tm True dtype: bool 空值详细信息 of Action 2 user_id False sku_id False time False model_id True type False cate False brand False dtype: bool 空值详细信息 of Action 3 user_id False sku_id False time False model_id True type False cate False brand False dtype: bool 空值详细信息 of Action 4 user_id False sku_id False time False model_id True type False cate False brand False dtype: bool
可得,存在空值的情况为
User
age,sex,user_reg_tm
Action
model_id
接着查看缺失值的数量和占比
def empty_records(file_path,file_name,col_name): file = open(file_path) df_file = pd.read_csv(file) missing = df_file[col_name].isnull().sum().sum() #使用.sum() print(‘缺失数 of {0} in {1} is {2}‘.format(col_name,file_name,missing)) print(‘占百分比为:‘,missing*1.0/df_file.shape[0]) #df.shape 获取df的size #df.shape[0] 获取df的行数 df.shape[1] 获取列数 empty_records(USER_FILE,‘User‘,‘age‘) empty_records(USER_FILE,‘User‘,‘sex‘) empty_records(USER_FILE,‘User‘,‘user_reg_tm‘) empty_records(ACTION_201602_FILE,‘Action 2‘,‘model_id‘) empty_records(ACTION_201602_FILE,‘Action 3‘,‘model_id‘) empty_records(ACTION_201602_FILE,‘Action 4‘,‘model_id‘)
结果为
缺失数 of age in User is 3 占百分比为: 2.8484347850855955e-05 缺失数 of sex in User is 3 占百分比为: 2.8484347850855955e-05 缺失数 of user_reg_tm in User is 3 占百分比为: 2.8484347850855955e-05 缺失数 of model_id in Action 2 is 4959617 占百分比为: 0.4318183638671067 缺失数 of model_id in Action 3 is 10553261 占百分比为: 0.4072043168995297 缺失数 of model_id in Action 4 is 5143018 占百分比为: 0.38962452388019514
填充user文件的空值,age用-1,sex用2
userfile = open(USER_FILE) user = pd.read_csv(userfile) #填充空值,age用-1,sex用2 user[‘age‘].fillna(‘-1‘,inplace=True) user[‘sex‘].fillna(‘2‘,inplace=True) print(pd.isnull(user).any())
查看结果
user_id False
age False
sex False
user_lv_cd False
user_reg_tm True
dtype: bool
查看各个文件中未知记录所占比重
print(‘未知文件 of age in user:{0} 所占比重:{1}‘.format(user[user[‘age‘]==‘-1‘].shape[0], user[user[‘age‘]==‘-1‘].shape[0]/user.shape[0])) print(‘未知文件 of sex in user: {0} 所占比重: {1} ‘.format(user[user[‘sex‘]==2].shape[0], user[user[‘sex‘]==2].shape[0]/user.shape[0] ))
结果
未知文件 of age in user:14415 所占比重:0.13686729142336287 未知文件 of sex in user: 54735 所占比重: 0.5196969265388669
def unknown_records(file_path, file_name, col_name): file_path1 = open(file_path) df_file = pd.read_csv(file_path1) missing = df_file[df_file[col_name] == -1].shape[0] print( ‘No. of unknown {0} in {1} is {2}‘.format(col_name, file_name, missing)) print (‘percent: ‘, missing / df_file.shape[0]) ‘‘‘ unknown_records(PRODUCT_FILE, ‘Product‘, ‘a1‘) unknown_records(PRODUCT_FILE, ‘Product‘, ‘a2‘) unknown_records(PRODUCT_FILE, ‘Product‘, ‘a3‘) ‘‘‘
数据一致性验证:利用pd.Merge连接sku 和 Action中的sku, 观察Action中的数据是否减少
def user_action_check(): user_f = open(USER_FILE) df_user = pd.read_csv(user_f) df_sku = df_user.ix[:,‘user_id‘].to_frame() Ac2 = open(ACTION_201602_FILE) df_month2 = pd.read_csv(Ac2) Ac3 = open(ACTION_201603_FILE) print (‘Is action of Feb. from User file? ‘, len(df_month2) == len(pd.merge(df_sku,df_month2))) df_month3 = pd.read_csv(Ac3) print (‘Is action of Mar. from User file? ‘, len(df_month3) == len(pd.merge(df_sku,df_month3))) Ac4 = open(ACTION_201604_FILE) df_month4 = pd.read_csv(Ac4) print (‘Is action of Apr. from User file? ‘, len(df_month4) == len(pd.merge(df_sku,df_month4))) user_action_check()
结果
Is action of Feb. from User file? True Is action of Mar. from User file? True Is action of Apr. from User file? True
结论: User数据集中的用户和交互行为数据集中的用户完全一致
#重复记录分析
#检查是否存在注册时间在2016年-4月-15号之后的用户
将user_id转换为int
import pandas as pd df_month = pd.read_csv(‘dataJData_Action_201602.csv‘) df_month[‘user_id‘] = df_month[‘user_id‘].apply(lambda x:int(x)) print df_month[‘user_id‘].dtype df_month.to_csv(‘dataJData_Action_201602.csv‘,index=None) df_month = pd.read_csv(‘dataJData_Action_201603.csv‘) df_month[‘user_id‘] = df_month[‘user_id‘].apply(lambda x:int(x)) print df_month[‘user_id‘].dtype df_month.to_csv(‘dataJData_Action_201603.csv‘,index=None) df_month = pd.read_csv(‘dataJData_Action_201604.csv‘) df_month[‘user_id‘] = df_month[‘user_id‘].apply(lambda x:int(x)) print df_month[‘user_id‘].dtype df_month.to_csv(‘dataJData_Action_201604.csv‘,index=None)
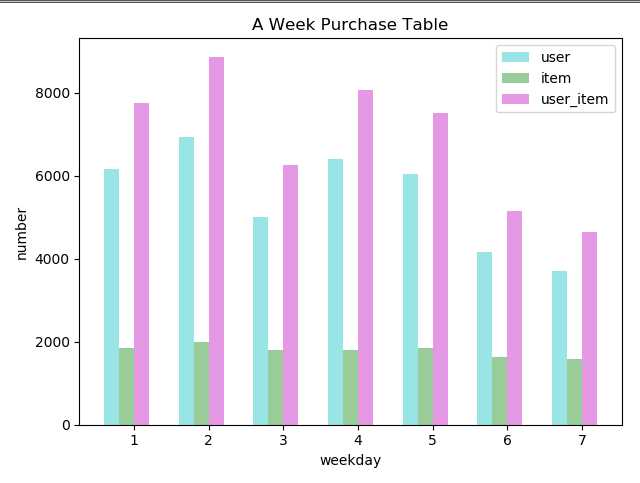
按照星期对用户进行分析
def get_from_action_data(fname, chunk_size=100000): reader = pd.read_csv(fname, header=0, iterator=True) chunks = [] loop = True while loop: try: chunk = reader.get_chunk(chunk_size)[ ["user_id", "sku_id", "type", "time"]] chunks.append(chunk) except StopIteration: loop = False print("Iteration is stopped") df_ac = pd.concat(chunks, ignore_index=True) # type=4,为购买 df_ac = df_ac[df_ac[‘type‘] == 4] return df_ac[["user_id", "sku_id", "time"]] df_ac = [] df_ac.append(get_from_action_data(fname=ACTION_201602_FILE)) df_ac.append(get_from_action_data(fname=ACTION_201603_FILE)) df_ac.append(get_from_action_data(fname=ACTION_201604_FILE)) df_ac = pd.concat(df_ac, ignore_index=True) print(df_ac.dtypes) # 将time字段转换为datetime类型 df_ac[‘time‘] = pd.to_datetime(df_ac[‘time‘]) # 使用lambda匿名函数将时间time转换为星期(周一为1, 周日为7) df_ac[‘time‘] = df_ac[‘time‘].apply(lambda x: x.weekday() + 1) # 周一到周日每天购买用户个数 df_user = df_ac.groupby(‘time‘)[‘user_id‘].nunique() df_user = df_user.to_frame().reset_index() df_user.columns = [‘weekday‘, ‘user_num‘] # 周一到周日每天购买商品个数 df_item = df_ac.groupby(‘time‘)[‘sku_id‘].nunique() df_item = df_item.to_frame().reset_index() df_item.columns = [‘weekday‘, ‘item_num‘] # 周一到周日每天购买记录个数 df_ui = df_ac.groupby(‘time‘, as_index=False).size() df_ui = df_ui.to_frame().reset_index() df_ui.columns = [‘weekday‘, ‘user_item_num‘] # 条形宽度 bar_width = 0.2 # 透明度 opacity = 0.4 plt.bar(df_user[‘weekday‘], df_user[‘user_num‘], bar_width, alpha=opacity, color=‘c‘, label=‘user‘) plt.bar(df_item[‘weekday‘]+bar_width, df_item[‘item_num‘], bar_width, alpha=opacity, color=‘g‘, label=‘item‘) plt.bar(df_ui[‘weekday‘]+bar_width*2, df_ui[‘user_item_num‘], bar_width, alpha=opacity, color=‘m‘, label=‘user_item‘) plt.xlabel(‘weekday‘) plt.ylabel(‘number‘) plt.title(‘A Week Purchase Table‘) plt.xticks(df_user[‘weekday‘] + bar_width * 3 / 2., (1,2,3,4,5,6,7)) plt.tight_layout() plt.legend(prop={‘size‘:10}) #plt.show()
结果
以上是关于京东JData算法大赛高潜用户购买意向预测——复现的主要内容,如果未能解决你的问题,请参考以下文章