Medical Image Report论文合辑
Posted czhwust
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Medical Image Report论文合辑相关的知识,希望对你有一定的参考价值。
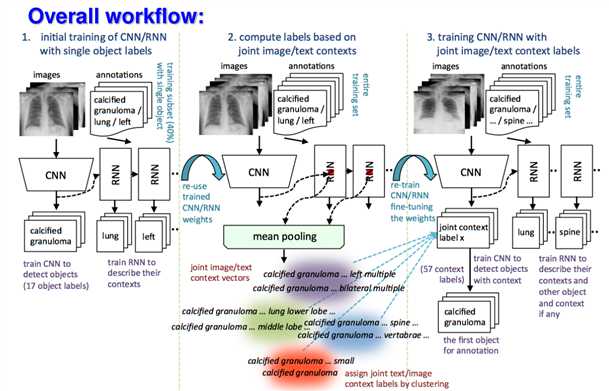
Learning to Read Chest X-Rays:Recurrent Neural Cascade Model for Automated Image Annotation (CVPR 2016)
Goals:
-Learn to read chest x-rays from an existing dataset of images and text with minimal human effort
-To generate text description about disease in image as well as their context (with pre-defined grammar, thus not multiple-instance-learning)
Approach
-Text-mining based image labeling;train CNN for image, RNN for text
-Extensive regularization (e.g.,batch-normalization, data dropout) to deal with data bias(normal vs. diseased)
-Joint image/text context vector for more composite image labeling
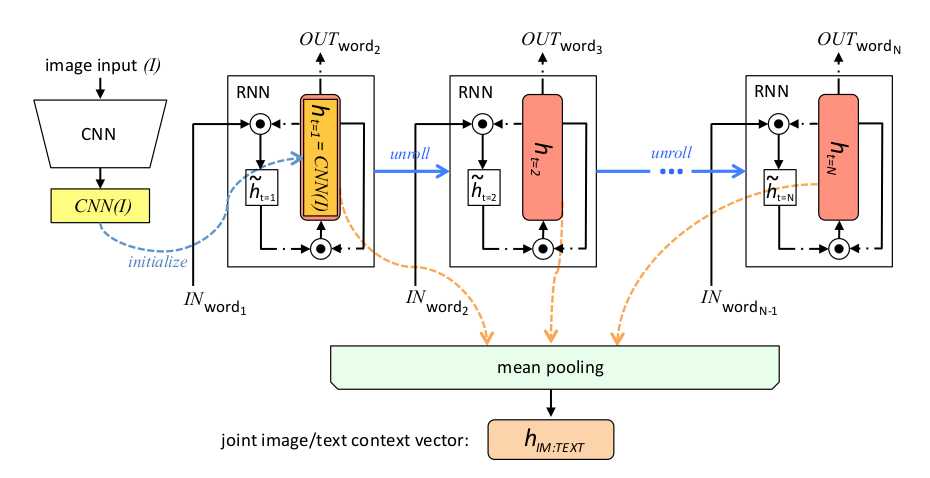
The above picture is an illustration of how joint image/text context vector is obtained. RNN‘s state vector (h) is initialized with the CNN image embedding (CNN(I)), and it‘s unrolled over the annotation sequences with the words as input. Mean-pooling is applied over the state vectors in each word of the sequence, to obtain the joint image/text vector. All RNNs share the same parameters, which are trained in the first round.
MDNet: A Semantically and Visually Interpretable Medical Image Diagnosis Network (CVPR 2017)
TandemNet: Distilling Knowledge from Medical Images Using Diagnostic Reports as Optional Semantic References (MICCAI 2017)
Hybrid Retrieval-Generation Reinforced Agent for Medical Image Report Generation (NIPS 2018)
On the Automatic Generation of Medical Imaging Reports (ACL 2018)
TieNet: Text-Image Embedding Network for Common Thorax Disease Classification and Reporting in Chest X-rays (CVPR 2018)
Reading a chest X-ray image remains a challenging job for learning-oriented machine intelligence ,due to
(1).shortage of large-scale machine-learnable medical image datasets
(2).lack of techniques that can mimic the high-level reasoning of human radiologists that requires years of knowledge accumulation and professional training.
Contributions:
(1).proposed the Text-Image Embedding Network, which is a multi-purpose end-to-end trainable multi-task CNN-RNN framework
(2).show how raw report data, together with paired image, can be utilized to produce meaningful attention-based image and text representations using the proposed TieNet.
(3).outline how the developed text and image embeddings are able to boost the auto-annotation framework and achieve extremely high accuracy for chest x-ray labeling
(4).present a novel image classification framework which takes images as the sole input, but uses the paired text-image representations from training as a prior knowledge injection, in order to produce improved classification scores and preliminary report generations.
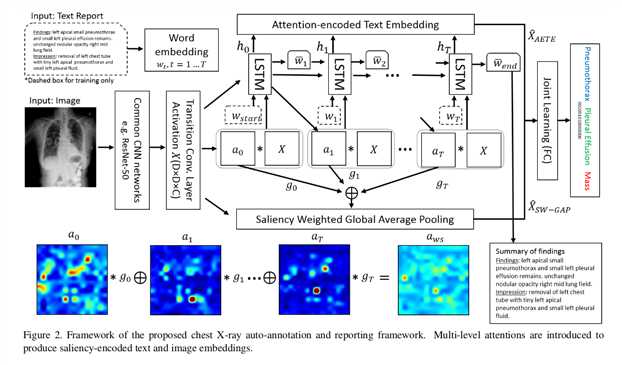
Knowledge-Driven Encode, Retrieve, Paraphrase for Medical Image Report Generation (AAAI 2019)
Christy Y. Li, Xiaodan Liang**, Zhiting Hu, Eric Xing.
End-to-End Knowledge-Routed Relational Dialogue System for Automatic Diagnosis (AAAI 2019)
Lin Xu, Qixian Zhou, Ke Gong, Xiaodan Liang**, Jianheng Tang, Liang Lin.
以上是关于Medical Image Report论文合辑的主要内容,如果未能解决你的问题,请参考以下文章