Gluon 实现 dropout 丢弃法
Posted treedream
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Gluon 实现 dropout 丢弃法相关的知识,希望对你有一定的参考价值。
多层感知机中:
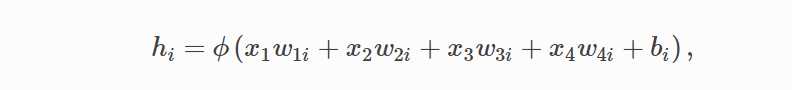
hi 以 p 的概率被丢弃,以 1-p 的概率被拉伸,除以 1 - p
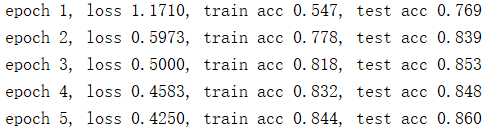
import mxnet as mx import sys import os import time import gluonbook as gb from mxnet import autograd,init from mxnet import nd,gluon from mxnet.gluon import data as gdata,nn from mxnet.gluon import loss as gloss ‘‘‘ # 模型参数 num_inputs, num_outputs, num_hiddens1, num_hiddens2 = 784,10,256,256 W1 = nd.random.normal(scale=0.01,shape=(num_inputs,num_hiddens1)) b1 = nd.zeros(num_hiddens1) W2 = nd.random.normal(scale=0.01,shape=(num_hiddens1,num_hiddens2)) b2 = nd.zeros(num_hiddens2) W3 = nd.random.normal(scale=0.01,shape=(num_hiddens2,num_outputs)) b3 = nd.zeros(num_outputs) params = [W1,b1,W2,b2,W3,b3] for param in params: param.attach_grad() # 定义网络 ‘‘‘ # 读取数据 # fashionMNIST 28*28 转为224*224 def load_data_fashion_mnist(batch_size, resize=None, root=os.path.join( ‘~‘, ‘.mxnet‘, ‘datasets‘, ‘fashion-mnist‘)): root = os.path.expanduser(root) # 展开用户路径 ‘~‘。 transformer = [] if resize: transformer += [gdata.vision.transforms.Resize(resize)] transformer += [gdata.vision.transforms.ToTensor()] transformer = gdata.vision.transforms.Compose(transformer) mnist_train = gdata.vision.FashionMNIST(root=root, train=True) mnist_test = gdata.vision.FashionMNIST(root=root, train=False) num_workers = 0 if sys.platform.startswith(‘win32‘) else 4 train_iter = gdata.DataLoader( mnist_train.transform_first(transformer), batch_size, shuffle=True, num_workers=num_workers) test_iter = gdata.DataLoader( mnist_test.transform_first(transformer), batch_size, shuffle=False, num_workers=num_workers) return train_iter, test_iter # 定义网络 drop_prob1,drop_prob2 = 0.2,0.5 # Gluon版 net = nn.Sequential() net.add(nn.Dense(256,activation="relu"), nn.Dropout(drop_prob1), nn.Dense(256,activation="relu"), nn.Dropout(drop_prob2), nn.Dense(10) ) net.initialize(init.Normal(sigma=0.01)) # 训练模型 def accuracy(y_hat, y): return (y_hat.argmax(axis=1) == y.astype(‘float32‘)).mean().asscalar() def evaluate_accuracy(data_iter, net): acc = 0 for X, y in data_iter: acc += accuracy(net(X), y) return acc / len(data_iter) def train(net, train_iter, test_iter, loss, num_epochs, batch_size, params=None, lr=None, trainer=None): for epoch in range(num_epochs): train_l_sum = 0 train_acc_sum = 0 for X, y in train_iter: with autograd.record(): y_hat = net(X) l = loss(y_hat, y) l.backward() if trainer is None: gb.sgd(params, lr, batch_size) else: trainer.step(batch_size) # 下一节将用到。 train_l_sum += l.mean().asscalar() train_acc_sum += accuracy(y_hat, y) test_acc = evaluate_accuracy(test_iter, net) print(‘epoch %d, loss %.4f, train acc %.3f, test acc %.3f‘ % (epoch + 1, train_l_sum / len(train_iter), train_acc_sum / len(train_iter), test_acc)) num_epochs = 5 lr = 0.5 batch_size = 256 loss = gloss.SoftmaxCrossEntropyLoss() train_iter, test_iter = load_data_fashion_mnist(batch_size) trainer = gluon.Trainer(net.collect_params(),‘sgd‘,{‘learning_rate‘:lr}) train(net,train_iter,test_iter,loss,num_epochs,batch_size,None,None,trainer)
以上是关于Gluon 实现 dropout 丢弃法的主要内容,如果未能解决你的问题,请参考以下文章
深度学习入门基础CNN系列——批归一化(Batch Normalization)和丢弃法(dropout)