聊聊错误注入技巧
Posted Android路上的人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了聊聊错误注入技巧相关的知识,希望对你有一定的参考价值。
前言
什么是“错误注入”?错误注入指的是将错误引入到我们的程序中。可能有人会很好奇,这么做有什么目的呢?答案很简单:程序的测试。因为在很多时候,当我们要进行边缘情况测试的时候,往往模拟测试的场景不是非常好造的(尤其是分布式类的程序更是如此),这个时候,我们需要有快捷的方式将错误注入到程序中,以便在我们需要发生错误时,进行错误的产生。本文笔者将结合HDFS现有的错误注入方法来介绍此部分内容。
错误注入技术的原理
错误注入技术的一个核心关键词是“拦截”。正常情况下,应用程序是不会发生错误等异常的。而错误注入器的作用是对用户应用程序中的某个方法进行拦截,然后将错误注入到此处,然后接着往下执行,结果是程序终止了还是错误被处理了则还要看应用程序本身。
拦截的层面可以根据应用程序本身而定,比较简单的可以在应用程序同级别进行拦截,比较高级的是在OS层面,在系统回调方法处进行拦截。下图是原理图。
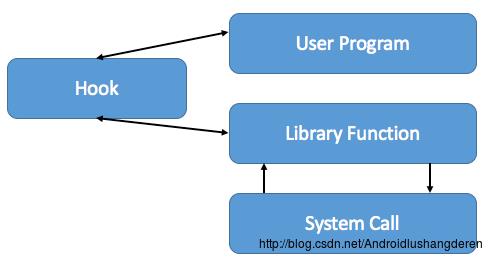
钩子拦截示意图
HDFS内部的几种错误注入方法
HDFS作为一个底层的存储系统,它的错误注入更多地偏向于是文件、数据块的错误注入。但是笔者认为错误注入的原理和技巧还是可以通用的。
结合应用程序规则的错误注入
首先笔者先来介绍一种比较简单的错误引入的方法。在HDFS内部,当DataNode内部的DiskChecker线程发现文件不能被执行,或突然丢失了,则会认为此文件所在的盘就为坏盘了。所以根据这个原则,我们可以得到下面2类错误注入的方法。
第一类,改变文件的属性,比如说变为只读。代码如下:
...
// fail the volume
// delete/make non-writable one of the directories (failed volume)
data_fail = new File(dataDir, "data3");
failedDir = MiniDFSCluster.getFinalizedDir(data_fail,
cluster.getNamesystem().getBlockPoolId());
if (failedDir.exists() &&
//!FileUtil.fullyDelete(failedDir)
!deteteBlocks(failedDir)
) {
throw new IOException("Could not delete hdfs directory '" + failedDir + "'");
}
// 设置文件目录为只读模式
data_fail.setReadOnly();
failedDir.setReadOnly();
System.out.println("Deleteing " + failedDir.getPath() + "; exist=" + failedDir.exists());
// access all the blocks on the "failed" DataNode,
// we need to make sure that the "failed" volume is being accessed -
// and that will cause failure, blocks removal, "emergency" block report
// 触发一次文件文件访问操作
triggerFailure(filename, filesize);
...
设置为只读方式,在随后的读块操作中,将会发现这个错误。
第二类,重命名原始文件,使系统认为原始文件发生丢失。重命名的好处是还可以再立刻恢复回去,而不是真的删除掉了。操作代码如下:
public static void injectDataDirFailure(File... dirs) throws IOException {
for (File dir : dirs) {
File renamedTo = new File(dir.getPath() + DIR_FAILURE_SUFFIX);
if (renamedTo.exists()) {
throw new IOException(String.format(
"Can not inject failure to dir: %s because %s exists.",
dir, renamedTo));
}
// 重命名文件操作
if (!dir.renameTo(renamedTo)) {
throw new IOException(String.format("Failed to rename %s to %s.",
dir, renamedTo));
}
if (!dir.createNewFile()) {
throw new IOException(String.format(
"Failed to create file %s to inject disk failure.", dir));
}
}
}以上2种是结合应用程序本身的特点而构造的错误注入的方法,这个可能还不算特别通用,如果是一些非存储类的分布式程序,可能就不适用了。
钩子方法的引入
这里我们提到了“钩子方法”,这个方法更形象的比喻可以说是开发者在应用程序中植入的一个错误发生器,在我们想要发生错误的时候,它能在特定的位置产生错误,而在正常的情况下时,它就只是一个空方法,什么事情都不干。
而这个“错误发生器”长什么样呢?笔者以DataNode的错误发生器为例:
/**
* Used for injecting faults in DFSClient and DFSOutputStream tests.
* Calls into this are a no-op in production code.
*/
@VisibleForTesting
@InterfaceAudience.Private
public class DataNodeFaultInjector {
// 单例模式
public static DataNodeFaultInjector instance = new DataNodeFaultInjector();
public static DataNodeFaultInjector get() {
return instance;
}
public static void set(DataNodeFaultInjector injector) {
instance = injector;
}
...然后下面是许多钩子方法,不同的方法到时会放到真正的处理方法中。
public class DataNodeFaultInjector {
...
// 下面是钩子方法,一般不执行具体逻辑
public void getHdfsBlocksMetadata() {}
public void writeBlockAfterFlush() throws IOException {}
public void sendShortCircuitShmResponse() throws IOException {}
public boolean dropHeartbeatPacket() {
return false;
}
...接着这些钩子方法会被放到对应的方法中,以writeBlockAfterFlush方法为例,此方法在DataXceiver的writeBlock方法中被调用:
@Override
public void writeBlock(final ExtendedBlock block,
final StorageType storageType,
final Token<BlockTokenIdentifier> blockToken,
final String clientname,
final DatanodeInfo[] targets,
final StorageType[] targetStorageTypes,
final DatanodeInfo srcDataNode,
final BlockConstructionStage stage,
final int pipelineSize,
final long minBytesRcvd,
final long maxBytesRcvd,
final long latestGenerationStamp,
DataChecksum requestedChecksum,
CachingStrategy cachingStrategy,
boolean allowLazyPersist,
final boolean pinning,
final boolean[] targetPinnings) throws IOException {
previousOpClientName = clientname;
...
try {
DataNodeFaultInjector.get().failMirrorConnection();
int timeoutValue = dnConf.socketTimeout +
(HdfsConstants.READ_TIMEOUT_EXTENSION * targets.length);
int writeTimeout = dnConf.socketWriteTimeout +
(HdfsConstants.WRITE_TIMEOUT_EXTENSION * targets.length);
NetUtils.connect(mirrorSock, mirrorTarget, timeoutValue);
mirrorSock.setTcpNoDelay(dnConf.getDataTransferServerTcpNoDelay());
mirrorSock.setSoTimeout(timeoutValue);
mirrorSock.setKeepAlive(true);
if (dnConf.getTransferSocketSendBufferSize() > 0) {
mirrorSock.setSendBufferSize(
dnConf.getTransferSocketSendBufferSize());
}
...
mirrorOut.flush();
// 此处调用钩子方法
DataNodeFaultInjector.get().writeBlockAfterFlush();
...
} catch (IOException e) {
//...
}
}因为在钩子方法所属区域内的代码块操作在真实环境中是很有可能抛出IO异常的,所以加在此处来模拟异常的发生。但是前面我们也说了,这个错误注入器内的方法实际上是空方法啊,异常怎么可能会抛出呢?所以这里需要矫正一个观点:错误注入器本身不负责注入错误,而是由外界来触发的。这里我们要用到mock方法。Mock操作可以在不更改原始代码的同时,覆盖原始方法操作。所以这里我们会用mock操作来覆盖这些钩子方法。下面是mock方法的构造过程。
public void testTimeoutMetric() throws Exception {
final Configuration conf = new HdfsConfiguration();
final Path path = new Path("/test");
final MiniDFSCluster cluster =
new MiniDFSCluster.Builder(conf).numDataNodes(2).build();
final List<FSDataOutputStream> streams = Lists.newArrayList();
try {
final FSDataOutputStream out =
cluster.getFileSystem().create(path, (short) 2);
// 构造错误注入器
final DataNodeFaultInjector injector = Mockito.mock
(DataNodeFaultInjector.class);
// 覆盖注入器的writeBlockAfterFlush方法,使之执行时抛出异常
Mockito.doThrow(new IOException("mock IOException")).
when(injector).
writeBlockAfterFlush();
// 将mock出的注入器赋给原始注入器
DataNodeFaultInjector.instance = injector;
streams.add(out);
out.writeBytes("old gs data\\n");
out.hflush();
/* Test the metric. */
final MetricsRecordBuilder dnMetrics =
getMetrics(cluster.getDataNodes().get(0).getMetrics().name());
// 检测异常
assertCounter("DatanodeNetworkErrors", 1L, dnMetrics);
...通过这样一番处理,程序在运行writeBlockAfterFlush时就不是一个空逻辑了,而是会抛出一个IO异常。而此时,原主逻辑代码却什么都没动。这种方式的错误注入在Hadoop代码内部的很多地方都存在,是一种比较通用的错误注入模式。Mock方式的错误注入原理刚好对照了上文提到的错误注入原理。
模拟对象的构造
模拟对象的构造已经不属于错误注入技术的范畴之内了,但是笔者觉得顺便讲讲也无妨。在部分测试场景中,测试人员无需完全模拟真实生产上的场景,因为有时这会带来大量时间、资源上的浪费。比如说我们对HDFS Balancer工具进行了更改,新增了一些功能参数。那么我们真的需要在测试程序中模拟造大量的block块,对其进行balance测试吗?答案显然不是的。这个时候其实我们只需要一个逻辑上的迁移,换句话说,我只需要构造一定的有效block块信息,至于block是否真的有数据即可,真实数据其实可以为0。所以这需要我们重新实现一个虚拟的数据集合。在HDFS内部,就有这么一个类,它完全实现了FsDatasetSpi接口。最为不同的是,他的输入输出流方法中,对于数据块的读写,只涉及数据大小值的改变,而无真实数据的写入写出操作。这个类叫做SimulatedFSDataset。
下面是此类内部会用到的输出流对象:
static private class SimulatedOutputStream extends OutputStream {
long length = 0;
/**
* constructor for Simulated Output Steram
*/
SimulatedOutputStream() {
}
/**
*
* @return the length of the data created so far.
*/
long getLength() {
return length;
}
/**
*/
void setLength(long length) {
this.length = length;
}
// 下面写出操作不涉及真实数据的写出
@Override
public void write(int arg0) throws IOException {
length++;
}
@Override
public void write(byte[] b) throws IOException {
length += b.length;
}
@Override
public void write(byte[] b,
int off,
int len) throws IOException {
length += len;
}
}通过这个例子,笔者想说的是,测试也是一门技术活,越是在复杂的运行环境中,高质量的测试就显得越为重要。完全生搬硬套式的测试方法可能能解决一时所需,但解决不了根本问题。测试与开放同样重要,在想好开发一个新功能的同时,也请想好如何进行测试的方法。
参考文献
[1].Quality Assurance at Cloudera: Highly-Controlled Disk Injection, http://blog.cloudera.com/blog/2016/08/quality-assurance-at-cloudera-highly-controlled-disk-injection/
以上是关于聊聊错误注入技巧的主要内容,如果未能解决你的问题,请参考以下文章