微服务化之无状态化与容器化
Posted gzxbkk
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了微服务化之无状态化与容器化相关的知识,希望对你有一定的参考价值。
一、为什么要做无状态化和容器化
很多应用拆分成微服务,是为了承载高并发,往往一个进程扛不住这么大的量,因而需要拆分成多组进程,每组进程承载特定的工作,根据并发的压力用多个副本公共承担流量。
将一个进程变成多组进程,每组进程多个副本,需要程序的修改支撑这种分布式的架构,如果架构不支持,仅仅在资源层创建多个副本是解决不了问题的。
很多人说,支撑双十一是靠堆机器,谁不会?真正经历过的会觉得,能够靠堆机器堆出来的,都不是问题,怕的是机器堆上去了,因为架构的问题,并发量仍然上不去。
阻碍单体架构变为分布式架构的关键点就在于状态的处理。如果状态全部保存在本地,无论是本地的内存,还是本地的硬盘,都会给架构的横向扩展带来瓶颈。
状态分为分发,处理,存储几个过程,如果对于一个用户的所有的信息都保存在一个进程中,则从分发阶段,就必须将这个用户分发到这个进程,否则无法对这个用户进行处理,然而当一个进程压力很大的时候,根本无法扩容,新启动的进程根本无法处理那些保存在原来进程的用户的数据,不能分担压力。
所以要讲整个架构分成两个部分,无状态部分和有状态部分,而业务逻辑的部分往往作为无状态的部分,而将状态保存在有状态的中间件中,如缓存,数据库,对象存储,大数据平台,消息队列等。
这样无状态的部分可以很容易的横向扩展,在用户分发的时候,可以很容易分发到新的进程进行处理,而状态保存到后端。而后端的中间件是有状态的,这些中间件设计之初,就考虑了扩容的时候,状态的迁移,复制,同步等机制,不用业务层关心。
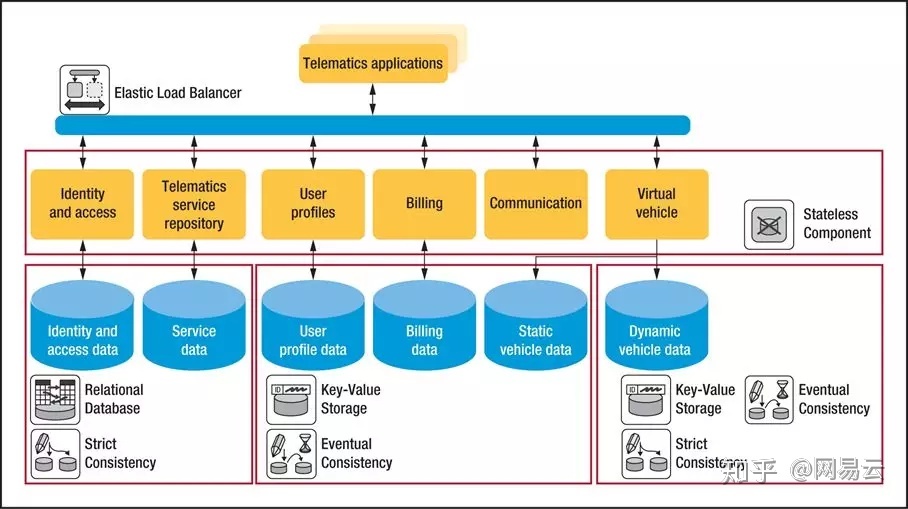
如图所示,将架构分为两层,无状态和有状态。
容器和微服务是双胞胎,因为微服务会将单体应用拆分成很多小的应用,因而运维和持续集成会工作量变大,而容器技术能很好的解决这个问题。然而在微服务化之前,建议先进行容器化,在容器化之前,建议先无状态化,当整个流程容器化了,以后的微服务拆分才会水到渠成。
二、无状态化的几个要点
前面说对于任何状态,需要考虑它的分发,处理,存储。
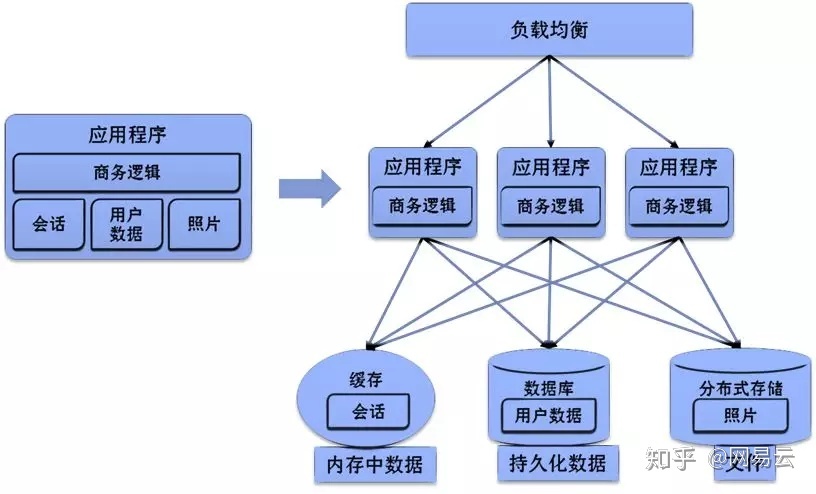
对于数据的存储,主要包含几类数据:
- 会话数据等,主要保存在内存中。
- 结构化数据,主要是业务逻辑相关
- 文件图片数据,比较大,往往通过CDN下发
- 非结构化数据,例如文本,评论等
如果这些数据都保存在本地,和业务逻辑耦合在一起,就需要在数据分发的时候,将同一个用户分到同一个进程,这样就会影响架构的横向扩展。
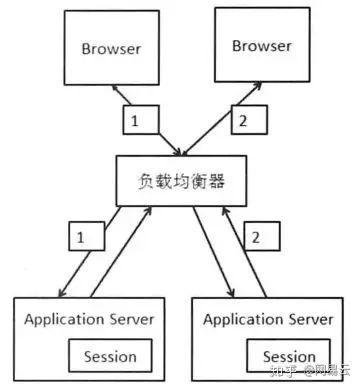
对于保存在内存里的数据,例如Session,可以放在外部统一的缓存中。
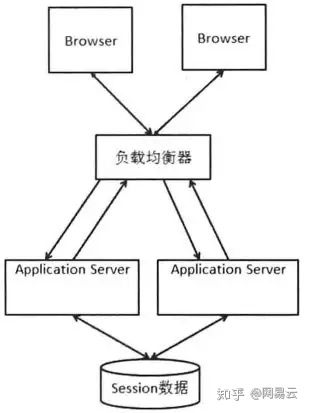
对于业务相关的数据,则应该保存在统一的数据库中,如果性能扛不住,可以进行读写分离,如文章微服务化的数据库设计与读写分离
如果性能还是抗住不,则可以使用分布式数据库。
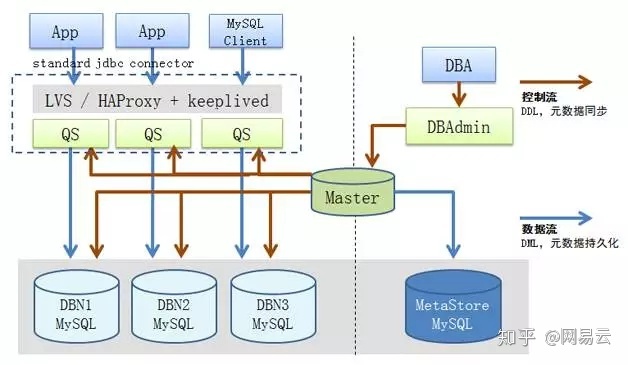
对于文件,照片之类的数据,应该存放在统一的对象存储里面,通过CDN进行预加载,如文章微服务的接入层设计与动静资源隔离
对于非结构化数据,可以存在在统一的搜索引擎里面,例如ElasticSearch。
如果所有的数据都放在外部的统一存储上,则应用就成了仅仅包含业务逻辑的无状态应用,可以进行平滑的横向扩展。
而所有的外部统一存储,无论是缓存,数据库,对象存储,搜索引擎,都有自身的分布式横向扩展机制。
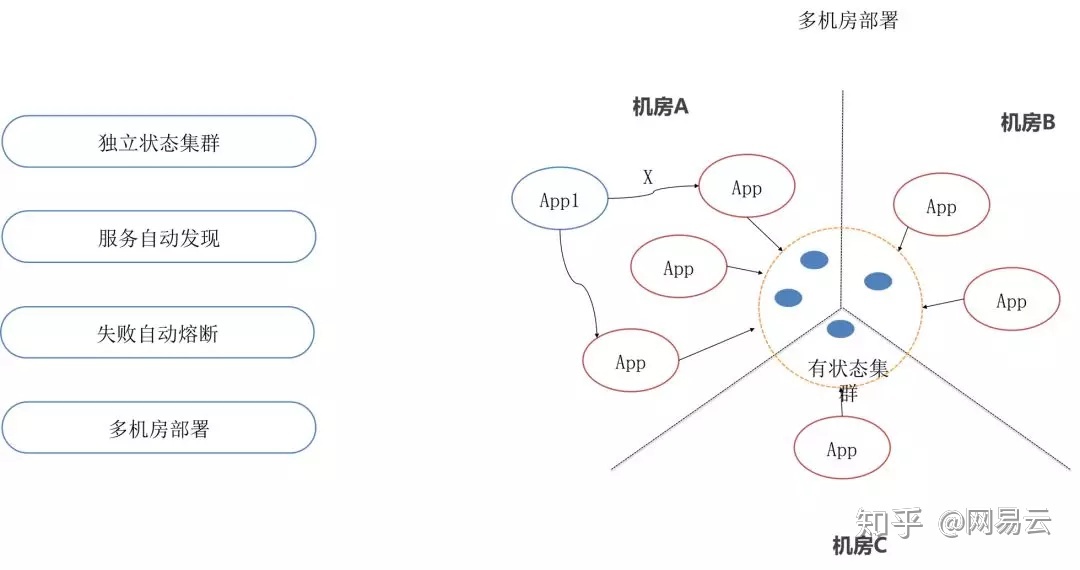
在实行了无状态化之后,就可以将有状态的集群集中到一起,进行跨机房的部署,实现跨机房的高可用性。而无状态的部分可以通过Dubbo自动发现,当进程挂掉的时候,自动重启,自动修复,也可以进行多机房的部署。
三、幂等的接口设计
但是还有一个遗留的问题,就是已经分发,正在处理,但是尚未存储的数据,肯定会在内存中有一些,在进程重启的时候,数据还是会丢一些的,那这部分数据怎么办呢?
这部分就需要通过重试进行解决,当本次调用过程中失败之后,前序的进程会进行重试,例如Dubbo就有重试机制。既然重试,就需要接口是幂等的,也即同一次交易,调用两次转账1元,不能最终转走2元。
接口分为查询,插入,更新,删除等操作。
对于查询接口来讲,本身就是幂等的,不用做特殊的判断。
对于插入接口来讲,如果每一个数据都有唯一的主键,也能保证插入的唯一性,一旦不唯一,则会报错。
对于更新操作来讲,则比较复杂,分几种情况。
一种情况是同一个接口,前后调用多次的幂等性。另一种情况是同一个接口,并发环境下调用多次的正确性。
为了保持幂等性,往往要有一个幂等表,通过传入幂等参数匹配幂等表中ID的方式,保证每个操作只被执行一次,而且在实行最终一致性的时候,可以通过不断重试,保证最终接口调用的成功。
对于并发条件下,谁先调用,谁后调用,需要通过分布式锁如Redis,Zookeeper等来实现同一个时刻只有一个请求被执行,如何保证多次执行结果仍然一致呢?则往往需要通过状态机,每个状态只流转一次。还有就是乐观锁,也即分布式的CAS操作,将状态的判断、更新整合在一条语句中,可以保证状态流转的原子性。乐观锁并不保证更新一定成功,需要有对应的机制来应对更新失败。
四、容器的技术原理
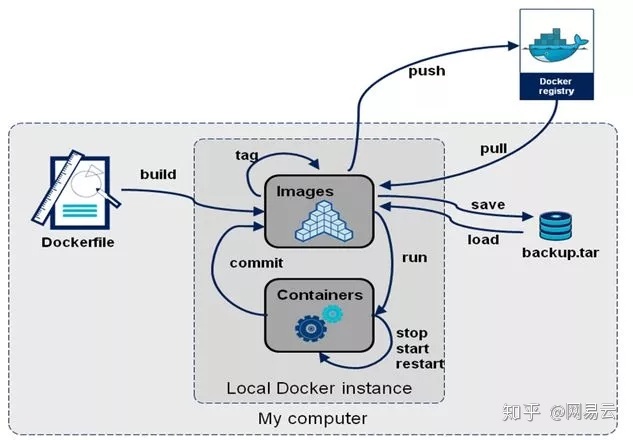
无状态化之后,实行容器化就十分顺畅了,容器的不可改变基础设施,以及容器基于容器平台的挂掉自动重启,自动修复,都因为无状态顺畅无比。
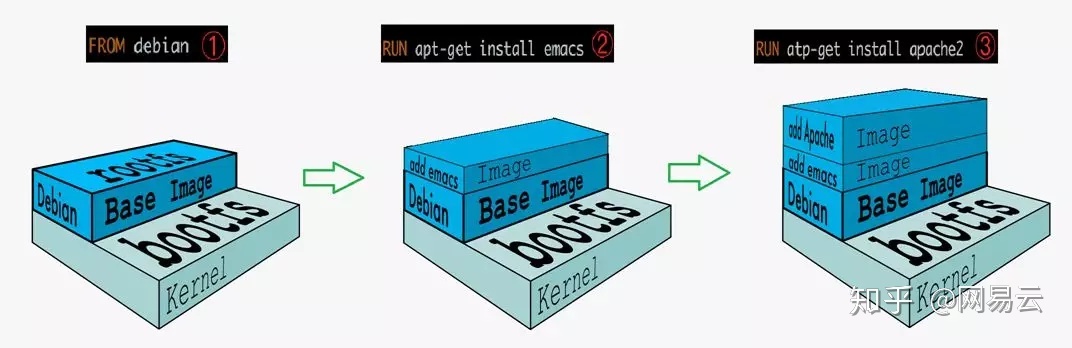
关键技术一:Dockerfile
例如下面的Dockerfile。
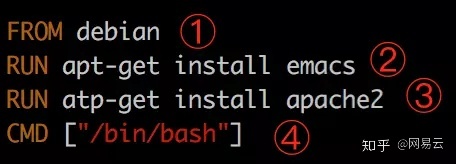
为什么一定要用Dockerfile,而不建议通过保存镜像的方式来生成镜像呢?
这样才能实现环境配置和环境部署代码化 ,将Dockerfile维护在Git里面,有版本控制,并且通过自动化的build的过程来生成镜像,而镜像中就是环境的配置和环境的部署,要修改环境应先通过Git上面修改Dockerfile的方式进行,这就是IaC。
关键技术二:容器镜像
通过Dockerfile可以生成容器镜像,容器的镜像是分层保存,对于Dockerfile中的每一个语句,生成一层容器镜像,如此叠加,每一层都有UUID。
容器镜像可以打一个版本号,放入统一的镜像仓库。
关键技术三:容器运行时
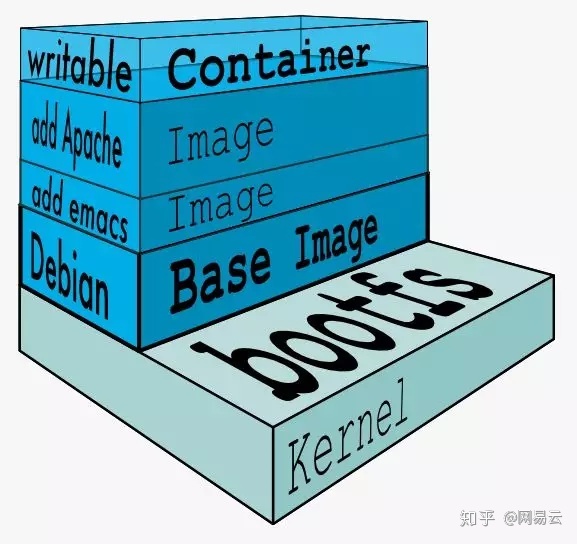
容器运行时,是将容器镜像之上加一层可写入层,为容器运行时所看到的文件系统。
容器运行时使用了两种隔离的技术。
一种是看起来是隔离的技术,称为namespace,也即每个namespace中的应用看到的是不同的IP地址、用户空间、程号等。
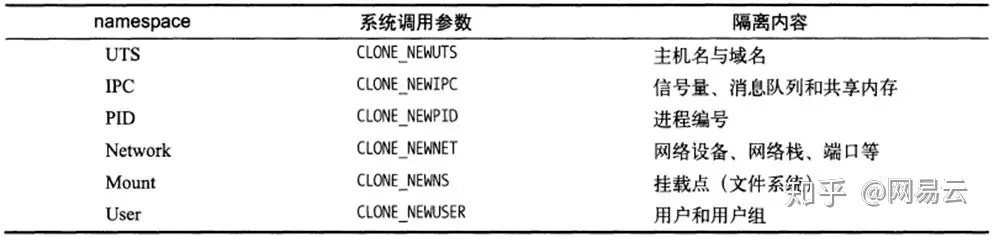
另一种是用起来是隔离的技术,称为cgroup,也即明明整台机器有很多的CPU、内存,而一个应用只能用其中的一部分。
cgroup

五、容器化的本质和容器化最佳实践
很多人会将容器当成虚拟机来用,这是非常不正确的,而且容器所做的事情虚拟机都能做到。
如果部署的是一个传统的应用,这个应用启动速度慢,进程数量少,基本不更新,那么虚拟机完全能够满足需求。
- 应用启动慢:应用启动15分钟,容器本身秒级,虚拟机很多平台能优化到十几秒,两者几乎看不出差别
- 内存占用大:动不动32G,64G内存,一台机器跑不了几个。
- 基本不更新:半年更新一次,虚拟机镜像照样能够升级和回滚
- 应用有状态:停机会丢数据,如果不知道丢了啥,就算秒级启动有啥用,照样恢复不了,而且还有可能因为丢数据,在没有修复的情况下,盲目重启带来数据混乱。
- 进程数量少:两三个进程相互配置一下,不用服务发现,配置不麻烦
如果是一个传统应用,根本没有必要花费精去容器化,因为白花了力气,享受不到好处。

什么情况下,才应该考虑做一些改变呢?
传统业务突然被互联网业务冲击了,应用老是变,三天两头要更新,而且流量增大了,原来支付系统是取钱刷卡的,现在要互联网支付了,流量扩大了N倍。
没办法,一个字:拆
拆开了,每个子模块独自变化,少相互影响。
拆开了,原来一个进程扛流量,现在多个进程一起扛。
所以称为微服务。
微服务场景下,进程多,更新快,于是出现100个进程,每天一个镜像。
容器乐了,每个容器镜像小,没啥问题,虚拟机哭了,因为虚拟机每个镜像太大了。
所以微服务场景下,可以开始考虑用容器了。
虚拟机怒了,老子不用容器了,微服务拆分之后,用Ansible自动部署是一样的。
这样说从技术角度来讲没有任何问题。
然而问题是从组织角度出现的。
一般的公司,开发会比运维多的多,开发写完代码就不用管了,环境的部署完全是运维负责,运维为了自动化,写Ansible脚本来解决问题。
然而这么多进程,又拆又合并的,更新这么快,配置总是变,Ansible脚本也要常改,每天都上线,不得累死运维。
所以这如此大的工作量情况下,运维很容易出错,哪怕通过自动化脚本。
这个时候,容器就可以作为一个非常好的工具运用起来。
除了容器从技术角度,能够使得大部分的内部配置可以放在镜像里面之外,更重要的是从流程角度,将环境配置这件事情,往前推了,推到了开发这里,要求开发完毕之后,就需要考虑环境部署的问题,而不能当甩手掌柜。
这样做的好处就是,虽然进程多,配置变化多,更新频繁,但是对于某个模块的开发团队来讲,这个量是很小的,因为5-10个人专门维护这个模块的配置和更新,不容易出错。
如果这些工作量全交给少数的运维团队,不但信息传递会使得环境配置不一致,部署量会大非常多。
容器是一个非常好的工具,就是让每个开发仅仅多做5%的工作,就能够节约运维200%的工作,并且不容易出错。
然而本来原来运维该做的事情开发做了,开发的老大愿意么?开发的老大会投诉运维的老大么?
这就不是技术问题了,其实这就是DevOps,DevOps不是不区分开发和运维,而是公司从组织到流程,能够打通,看如何合作,边界如何划分,对系统的稳定性更有好处。
所以微服务,DevOps,容器是相辅相成,不可分割的。
不是微服务,根本不需要容器,虚拟机就能搞定,不需要DevOps,一年部署一次,开发和运维沟通再慢都能搞定。
所以,容器的本质是基于镜像的跨环境迁移。
镜像是容器的根本性发明,是封装和运行的标准,其他什么namespace,cgroup,早就有了。这是技术方面。
在流程方面,镜像是DevOps的良好工具。
容器是为了跨环境迁移的,第一种迁移的场景是开发,测试,生产环境之间的迁移。如果不需要迁移,或者迁移不频繁,虚拟机镜像也行,但是总是要迁移,带着几百G的虚拟机镜像,太大了。
第二种迁移的场景是跨云迁移,跨公有云,跨Region,跨两个OpenStack的虚拟机迁移都是非常麻烦,甚至不可能的,因为公有云不提供虚拟机镜像的下载和上传功能,而且虚拟机镜像太大了,一传传一天。
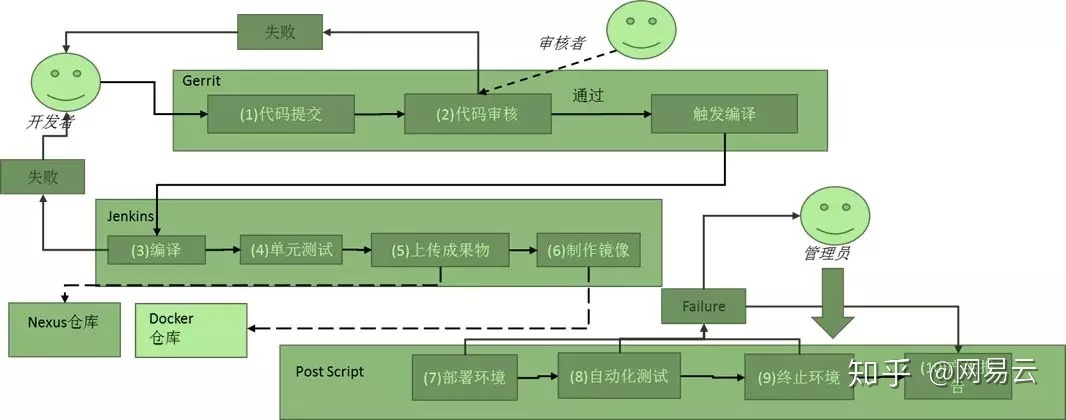
所以如图为将容器融入持续集成的过程中,形成DevOps的流程。
通过这一章,再加上第一章微服务化的基石——持续集成就构成了微服务,DevOps,容器化三位一体的统一。
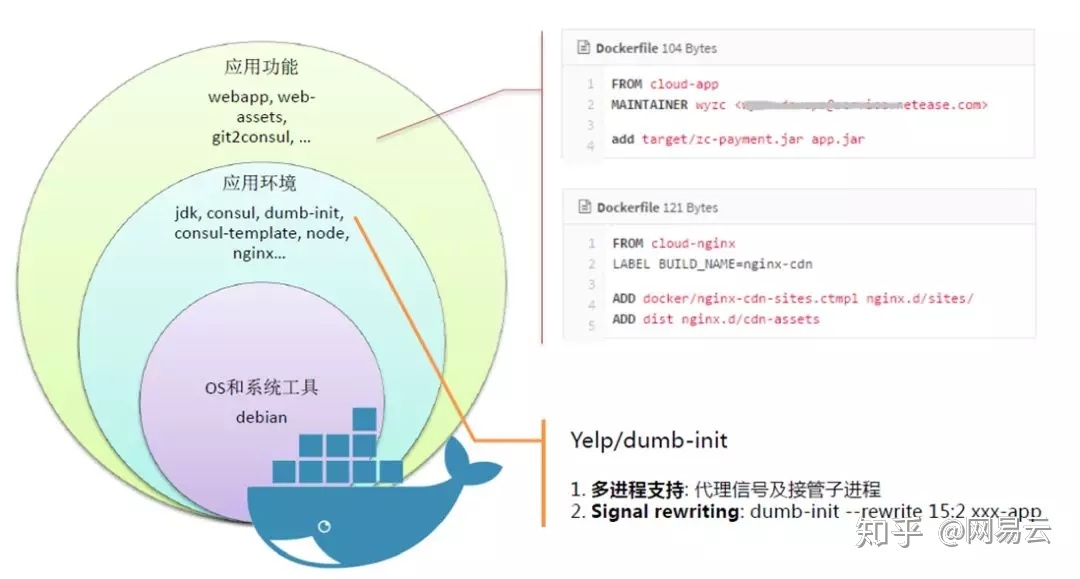
对于容器镜像,我们应该充分利用容器镜像分层的优势,将容器镜像分层构建,在最里面的OS和系统工具层,由运维来构建,中间层的JDK和运行环境,由核心开发人员构建,而最外层的Dockerfile就会非常简单,只要将jar或者war放到指定位置就可以了。
这样可以降低Dockerfile和容器化的门槛,促进DevOps的进度。
六、容器平台的最佳实践
容器化好了,应该交给容器平台进行管理,从而实现对于容器的自动化管理和编排。
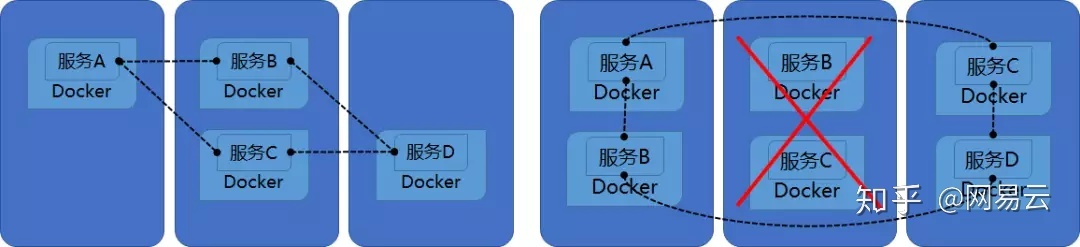
例如一个应用包含四个服务A,B,C,D,她们相互引用,相互依赖,如果使用了容器平台,则服务之间的服务发现就可以通过服务名进行了。例如A服务调用B服务,不需要知道B服务的IP地址,只需要在配置文件里面写入B服务服务名就可以了。如果中间的节点宕机了,容器平台会自动将上面的服务在另外的机器上启动起来。容器启动之后,容器的IP地址就变了,但是不用担心,容器平台会自动将服务名B和新的IP地址映射好,A服务并无感知。这个过程叫做自修复和自发现。如果服务B遭遇了性能瓶颈,三个B服务才能支撑一个A服务,也不需要特殊配置,只需要将服务B的数量设置为3,A还是只需要访问服务B,容器平台会自动选择其中一个进行访问,这个过程称为弹性扩展和负载均衡。
当容器平台规模不是很大的时候,Docker Swarm Mode还是比较好用的:
- 集群的维护不需要Zookeeper,不需要Etcd,自己内置
- 命令行和Docker一样的,用起来顺手
- 服务发现和DNS是内置的
- Docker Overlay网络是内置的
总之Docker帮你料理好了一切,你不用太关心细节,很容易就能够将集群运行起来。
而且可以通过docker命令,像在一台机器上使用容器一样使用集群上的容器,可以随时将容器当虚拟机来使用,这样对于中等规模集群,以及运维人员还是比较友好的。
当然内置的太多了也有缺点,就是不好定制化,不好Debug,不好干预。当你发现有一部分性能不行的时候,你需要改整个代码,全部重新编译,当社区更新了,合并分支是很头疼的事情。当出现了问题的时候,由于Manager大包大揽干了很多活,不知道哪一步出错了,反正就是没有返回,停在那里,如果重启整个Manager,影响面又很大。
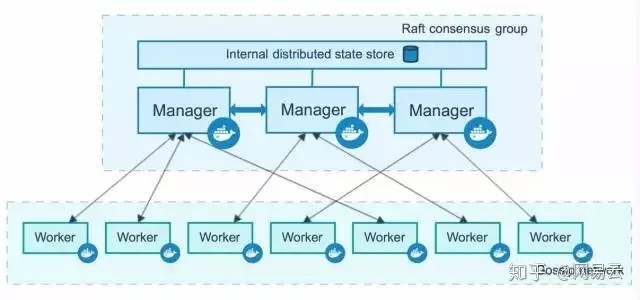
当规模比较大,应用比较复杂的时候,则推荐Kubernetes。
Kubernetes模块划分得更细,模块比较多,而且模块之间完全的松耦合,可以非常方便地进行定制化。
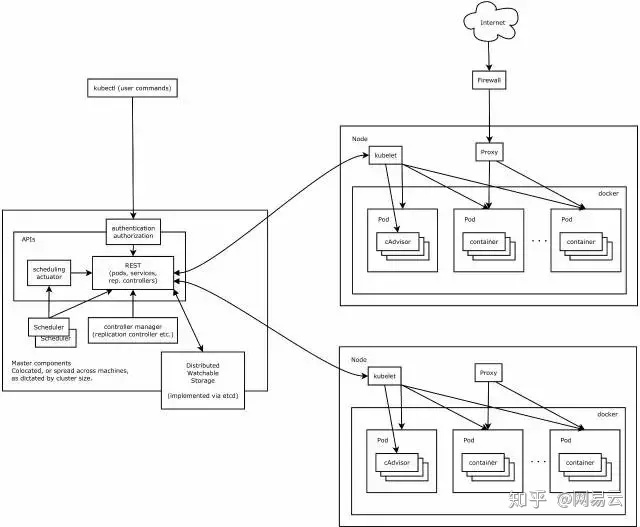
而且Kubernetes的数据结构的设计层次比较细,非常符合微服务的设计思想。例如从容器->Pods->Deployment->Service,本来简单运行一个容器,被封装为这么多的层次,每次层有自己的作用,每一层都可以拆分和组合,这样带来一个很大的缺点,就是学习门槛高,为了简单运行一个容器,需要先学习一大堆的概念和编排规则。
但是当需要部署的业务越来越复杂时,场景越来越多时,你会发现Kubernetes这种细粒度设计的优雅,使得你能够根据自己的需要灵活的组合,而不会因为某个组件被封装好了,从而导致很难定制。例如对于Service来讲,除了提供内部服务之间的发现和相互访问外,还灵活设计了headless service,这使得很多游戏需要有状态的保持长连接有了很好的方式,另外访问外部服务时,例如数据库、缓存、headless service相当于一个DNS,使得配置外部服务简单很多。很多配置复杂的大型应用,更复杂的不在于服务之间的相互配置,可以有Spring Cloud或者Dubbo去解决,复杂的反而是外部服务的配置,不同的环境依赖不同的外部应用,External Name这个提供和很好的机制。
包括统一的监控cadvisor,统一的配置confgMap,都是构建一个微服务所必须的。
然而Kubernetes当前也有一个瓶颈——集群规模还不是多么大,官方说法是几千个节点,所以超大规模的集群,还是需要有很强的IT能力进行定制化。但是对于中等规模的集群也足够了。
而且Kubernetes社区的热度,可以使得使用开源Kubernetes的公司能够很快地找到帮助,等待到新功能的开发和Bug的解决。
转自:https://blog.csdn.net/wangyiyungw/article/details/80321755
以上是关于微服务化之无状态化与容器化的主要内容,如果未能解决你的问题,请参考以下文章