网络爬虫之动态内容爬取
Posted xiaobingqianrui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络爬虫之动态内容爬取相关的知识,希望对你有一定的参考价值。
根据联合国网站可访问性审计报告,73%的主流网站都在其重要功能中依赖javascript。和单页面应用的简单表单事件不通,使用JavaScript时,不再是加载后立即下载所有页面内容。这样会造成许多网页在浏览其中展示的内容不会出现在html源码中,针对于这种依赖于JavaScript的动态网站,我们需要采取相应方法,比如JavaScript逆向工程、渲染JavaScript等方法。
1. 动态网页示例
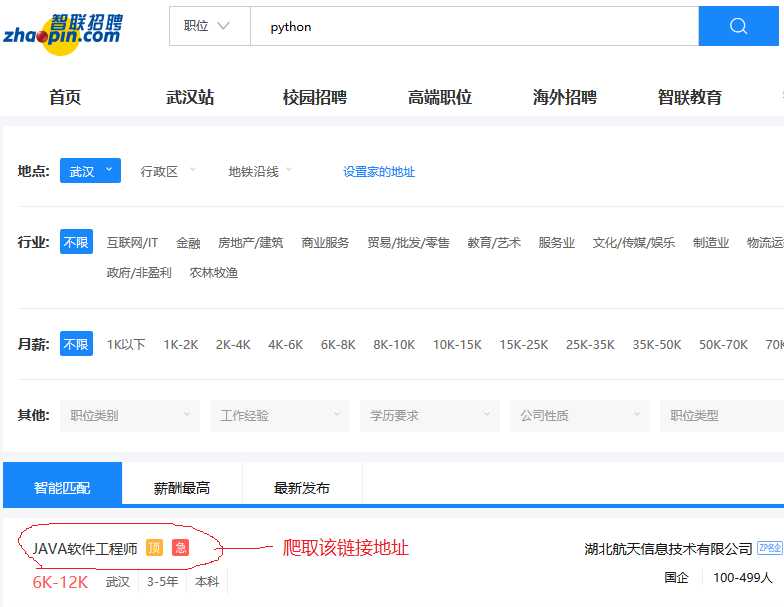
如上图,打开智联招聘主页,输入python,搜索会出现上面的页面,现在我们爬取上图红色标记出的链接地址
首先分析网页,获取该位置的div元素信息,我这里使用的是firefox浏览器,按F12

看上图,红色标记就是我们要获取的链接地址,现在用代码获取该处链接试试看
import requests from bs4 import BeautifulSoup as bs url = ‘https://sou.zhaopin.com/?jl=736&kw=python&kt=3‘ reponse = requests.get(url) soup = bs(reponse.text,"lxml") print(soup.select(‘span[title="JAVA软件工程师"]‘)) print(soup.select(‘a[class~="contentpile__content__wrapper__item__info"]‘))
输出结果为:[ ] [ ]
表示这个示例爬虫失败了,检查源码也会发现我们抓取的元素实际是空的,而firefox显示给我们的却是网页当前的状态,也就是使用JavaScript动态加载玩搜索结果后的网页。
2. 对动态网页进行逆向工程
在firefox中按F12单击控制台,打开XHR

依次点开,并查看响应出内容
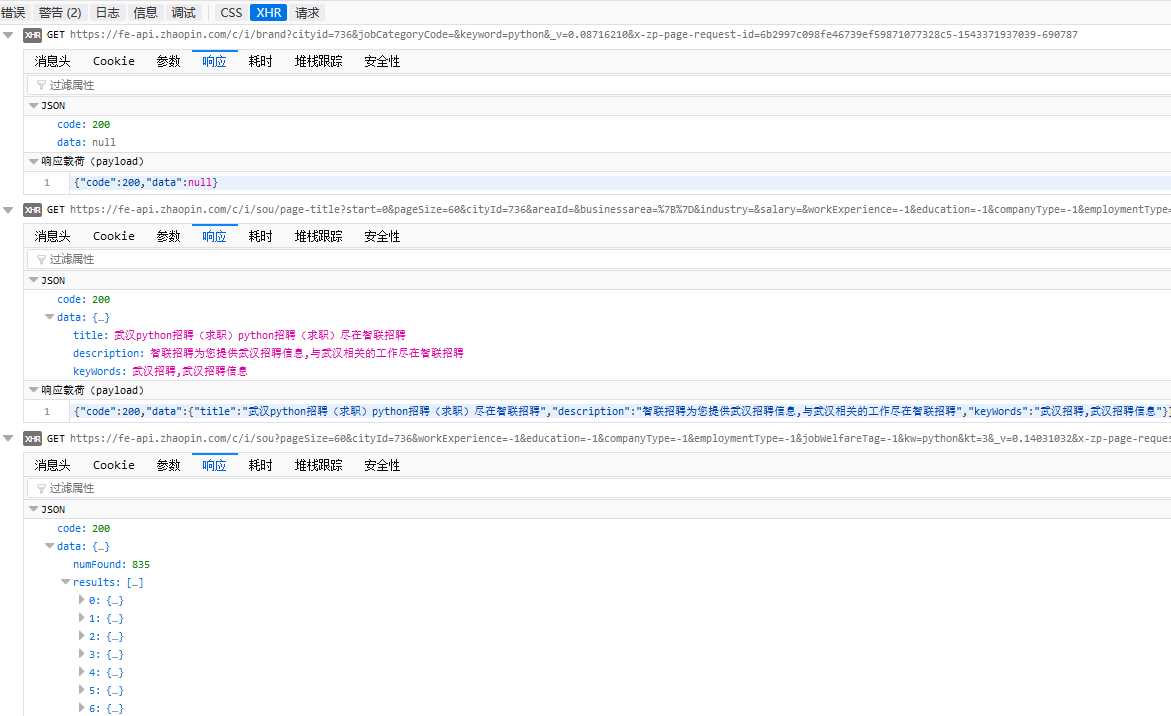
会发现最后一行有我们要的内容,继续点开results的索引0
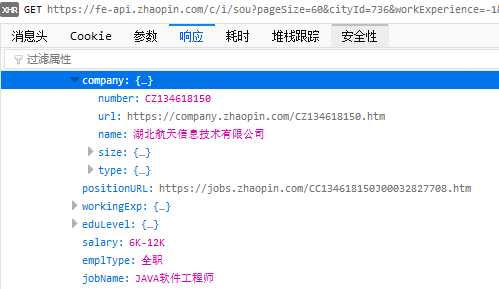
很好,这就是我们要找的信息
接下来我们就可以对第三行的网址进行爬虫处理并获取我们的想要的json信息。
3. 代码实现
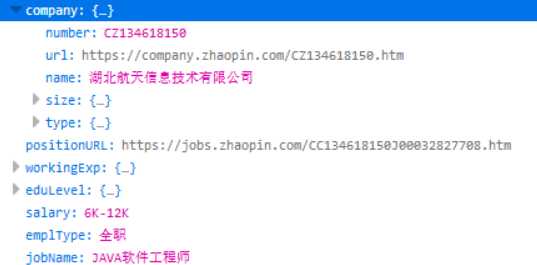
下面的代码演示爬取python搜索的第一页,并获取下图的链接
import requests import urllib import http import json def format_url(url, start=0,pagesize=60,cityid=736,workEXperience=-1, education=-1,companyType=-1,employmentType=-1,jobWelfareTag=-1, kw="python",kt=3): url = url.format(start,pagesize,cityid,workEXperience,education,companyType, employmentType,jobWelfareTag,kw,kt) return url; def ParseUrlToHtml(url,headers): cjar = http.cookiejar.CookieJar() opener = urllib.request.build_opener(urllib.request.HTTPSHandler, urllib.request.HTTPCookieProcessor(cjar)) headers_list = [] for key,value in headers.items(): headers_list.append(key) headers_list.append(value) opener.add_headers = [headers_list] html = None try: urllib.request.install_opener(opener) request = urllib.request.Request(url) reponse = opener.open(request) html = reponse.read().decode(‘utf-8‘) except urllib.error.URLError as e: if hasattr(e, ‘code‘): print ("HTTPErro:", e.code) elif hasattr(e, ‘reason‘): print ("URLErro:", e.reason) return opener,reponse,html if __name__ == "__main__": url = ‘https://fe-api.zhaopin.com/c/i/sou?start={}&pageSize={}&cityId={}‘ ‘&workExperience={}&education={}&companyType={}&employmentType={}‘ ‘&jobWelfareTag={}&kw={}&kt={}&_v=0.11773497‘ ‘&x-zp-page-request-id=080667c3cd2a48d79b31528c16a7b0e4-1543371722658-50400‘ headers = {"Connection":"keep-alive", "Accept":"application/json, text/plain, */*", ‘User-Agent‘: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:63.0) Gecko/20100101 Firefox/63.0‘} opener,reponse,html = ParseUrlToHtml(format_url(url), headers) if reponse.code == 200: try: ajax = json.loads(html) except ValueError as e: print(e) ajax = None else: ‘‘‘print(ajax) with open("zlzp.txt", "w") as pf: pf.write(json.dumps(ajax,indent=4))‘‘‘ results = ajax["data"]["results"] for result in results: if result["jobName"] == "JAVA软件工程师" and result["company"]["name"] == "湖北航天信息技术有限公司": print(result["positionURL"])
输出:
以上是关于网络爬虫之动态内容爬取的主要内容,如果未能解决你的问题,请参考以下文章