你真的了解 Unicode 和 UTF-8 吗?
Posted reycg-blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你真的了解 Unicode 和 UTF-8 吗?相关的知识,希望对你有一定的参考价值。
目录
引言
一直以来总是对 unicode, UTF-8 等编码知识懵懵懂懂的,尤其是在做项目过程中只要涉及到几个编码之间的转换,都得到网上搜索一番,根据别人的经验照葫芦画瓢,才能解决问题,但是私底下却完全不懂在做什么。
我再也不愿意重复这种状态了,于是就花了一个上午的时间,将这些知识整理了一遍。如果您觉得我的总结有疑问或者错误的地方,欢迎讨论交流,批评指正。
正题之前,先引入我总结的 Unicode 思维导图来预热下:
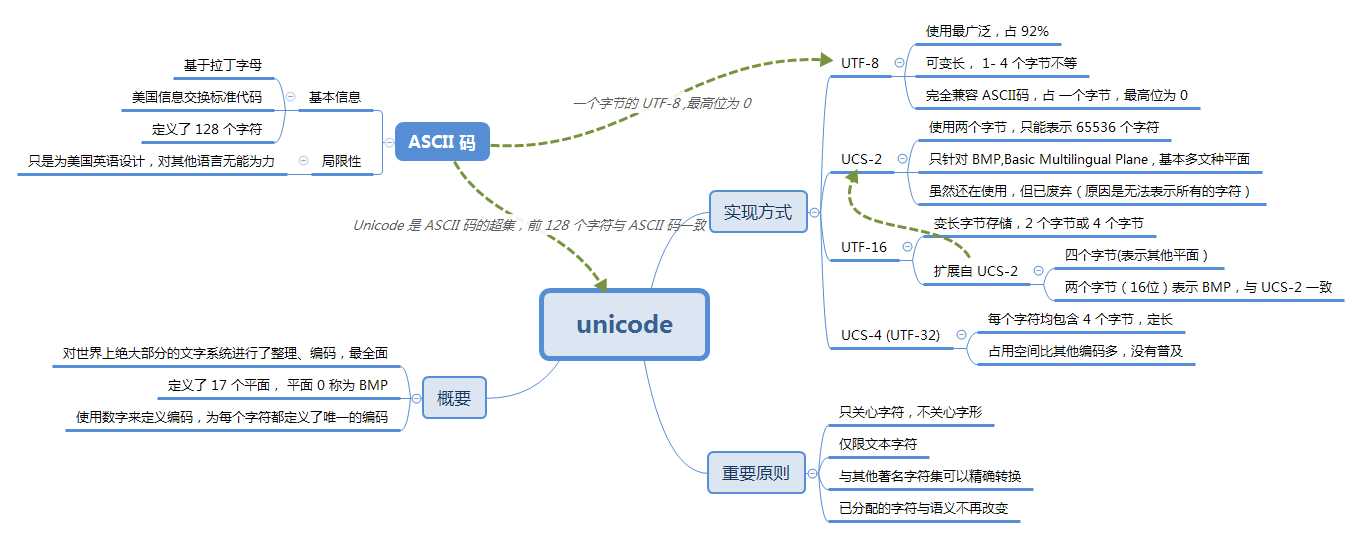
要了解 Unicode, 先要从 ASCII 码说起。
ASCII 码
什么是 ASCII 码?
ASCII 码(American Standard Code for Information Interchange)称为美国标准信息交换码。它是基于拉丁字母的一套电脑编码系统。它定义了一个用于代表常见字符的字典。
ASCII 码都包含哪些字符?
包括 "A-Z"(大小写都包含),数据"0-9" 以及一些常见的符号,要完整查看整个 ASCII 码对应关系,可参考这里
ASCII 码的局限在哪里?
ASCII 当初只是为美国英语而设计的,只能显示 128 个编码,对其他的语言无能为力。要想显示其他语言的编码,还是要使用 unicode。
Unicode
什么是 Unicode ?
为了将全世界的文字都统一的记录下来,并将每个字符都用唯一的数字记录下来,于是就产生了Unicode。
Unicode 也称为 UCS(Universal Coded Character Set:国际编码字符集合) 是一个字符集合,对世界上大部分的文字系统进行了整理,编码,使电脑可以用更为简单的方式来呈现和处理文字。最新的版本 Unicode 11.0 已经包含了 137439 个字符。
Unicode 的数量之多,如果完全涵盖它, 需要用 4 个字节来表示,但是计算机存储过程中却不是必须都用 4 个字节来完成。对于有些字符,尤其是编码在前面的字符我们也可以通过 1 个或 两个字节来节省空间。这就涉及到了 unicode 的实现方式。
Unicode 的实现方式有几种?
Unicode 只是一个字符集合,每个字符用一个数字来表示,但是这些数字在计算机内采用什么方式来存储,是全部都是 4 个字节,还是 1 到 4 个字节不等,这就涉及到了字符编码的概念。
我们说 Unicode 有几种实现方式,也就是在问 Unicode 有几种编码方式?
Unicode 常用的编码方式有 UTF-8, UCS-2, UTF-16 三种,另外还有一种 UTF-32 虽然不太常用也需要提一下。
Unicode 的体系结构是什么样的?
Unicode 既然能够存储那么多的字符,肯定是有它的存储规则的,如果使用 16 进制存储,它的存储范围是多少到多少,是否都是直筒式的,从低到高排就可以了?也就是说 Unicode 的体系结构是怎么样的。
Unicode 当前定义其字符的存储范围是: 0hex 到 10FFFFhex ,共分为 17 个区段,可以存储 1,114,112 个字符,这对当前 (137439) 来说远远足够了。
其中区段为 0hex 到 FFFFhex 称为 基本多文种平面 BMP (Basic Multilingual Plane),在这个平面中的字符表现形式是 U+ 后面跟 16 进制数。例如 X 字符的 unicode 是 U+0058。
而超出 BMP 范围的,也就是 10000hex–10FFFFhex 这 16 个区段,需要用到 5 到 6 位来表示,如 U+E0001 和 U+10FFFD。
UTF-8 编码
UTF-8 是使用互联网上使用最广泛的 unicode 编码方式,目前已经占有整个互联网 92% 的份额。这里再强调下 UTF-8 只是 Unicode 的一种实现方式,UTF-8 是编码方式,而 Unicode 是字符集合
它是可变长的编码方式,长度从 1 个字节到 4 个字节不等。
它能够完全兼容 ASCII 码,我们知道 ASCII 码 是由 128 个字符组成的,而 Unicode 中的前 128 个字符和 ASCII 码都是一一对应的。
UCS-2 编码
UCS-2 只使用了两个字节(16 bit) 来表示字符,也就是说只能表示 65536 个字符,它只能表示 BMP 中的字符。
当前的 unicode 字符数量已远远超过了 UCS-2 的数量,因此 UCS-2 虽然还在被好多软件使用,但它已经过期了。
正因为 UCS-2 编码依然被许多软件使用,为了能够表示出 BMP 以外的平面内的字符,就产生了一种新的编码 UTF-16 编码。
UTF-16 编码
UTF-16 就是为了解决 UCS-2 编码的问题而生的,它扩展自 UCS-2
- 基本多文种平面中,与 UCS-2 编码完全一致,使用两个字节表示
U+010000到U+10FFFF范围 使用 4 个字节表示
UTF-16 编码的市场份额和 UTF-8 比很小, 在web 页面中只占 0.01% 。而且主要在 windows 系统中使用, Unix/Linux 以及 MacOS 中很少使用。
UTF-32 编码
UTF-32 对 Unicode 中的每个字符都用 4 个字节来表示,占用的空间比其他编码要多的多,也正是这个原因,人们才用的很少。
小结
前面讲了那么多,再贴下 unicode 思维导图,来总结下
参考文档
以上是关于你真的了解 Unicode 和 UTF-8 吗?的主要内容,如果未能解决你的问题,请参考以下文章