数据分箱
Posted christina-notebook
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分箱相关的知识,希望对你有一定的参考价值。
一、定义
数据分箱就是将连续变量离散化。
二、意义
? 离散特征可变性强,易于模型的快速迭代;
? 稀疏向量运算速度快,方便存储;
? 变量离散化后对异常数据有很强的鲁棒性;
? 特征离散以后,模型会更加稳定;
? 将逻辑回归模型转换成评分卡形式的时候,分箱也是必须的。
三、分类
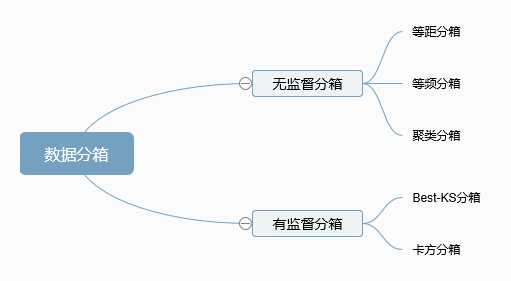
四、卡方分箱
(1)主要思想
? 自底向上数据离散;
? 相邻区间具有类似的类分布,则这两个区间可以合并;
? 否则,这两个区间应当分开。
(2)具体步骤
? 设定一个卡方阈值或分箱个数
? 对实例排序,每个实例属于一个区间
? 计算每一对相邻区间的卡方值
? 将卡方值最小的两个区间合并
(3)分箱个数
限制最终的分箱个数结果,合并区间,直到分箱个数达到限制条件为止。
(4)卡方阈值
如果分箱的各区间最小卡方值小于卡方阈值,则继续合并,直到最小卡方值超过设定阈值为止。
卡方阈值的确定:
? 根据显著性水平和自由度得到卡方值;
? 自由度比类别数量小1。例如:有3类,自由度为2,则90%置信度(10%显著性水平)下,卡方的值为4.6。
五、分箱评估
评估方法:
? WOE(weight of evidence),证据权重。WOE是对原始自变量的一种有监督的编码形式。
? IV(information value),信息价值。IV是衡量特征区分度的一种指标。
(1)WOE:
要对一个变量进行WOE编码,首先把这个变量进行分箱处理,分箱后,对于第i组,WOE的计算公式如下:
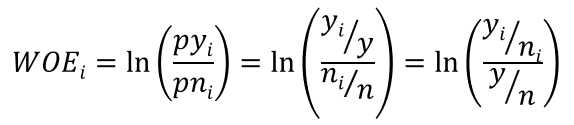
其中,pyi是第i组中响应客户占所有样本中所有响应客户的比例,pni是第i组中未响应客户占样本中所有未响应客户的比例。
当前这个组中响应的客户和未响应客户的比值,和所有样本中这个比值的差异。这个差异是用这两个比值的比值,再取对数来表示的。
(2)IV值
对于第i组,IV的计算公式如下:
![]()
由每个分组的IV值就可以得到整个变量的IV值,即将各个分组IV值相加:
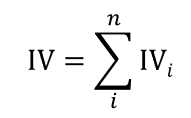
(3)变量IV——预测能力对应表
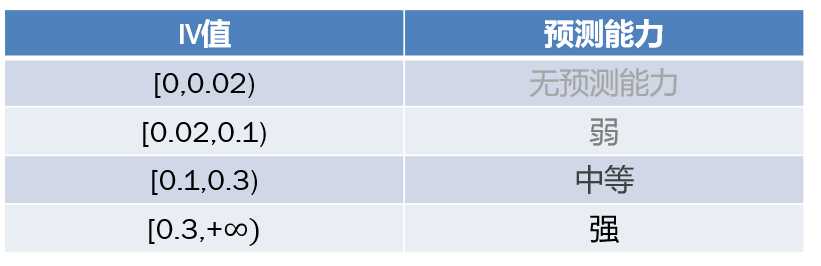
(4)为什么使用IV值进行判断,而不直接使用WOE值进行判断呢?
原因:
? IV值是非负的,衡量一个变量的预测能力比较合适;
? IV值体现出当前分组中个体的数量占整体数量的比例,对变量预测能力的影响。
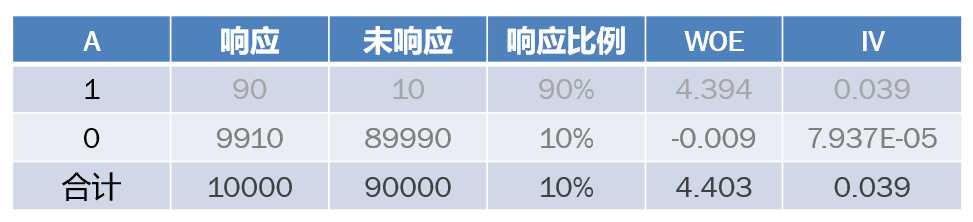
(5)注意事项
? 检查最大箱,如果最大箱里面数据数量占总数据的90%以上,那么弃用这个变量;
? 当有两个变量相关性高并且只能保留一个时,选择IV值高的或者分箱均衡的变量;
? 如果遇到响应比例为0或者100%时:将这个分组做成一个规则,作为模型的前置条件或者补充条件;重新对变量进行分组;人工调整。
六、R实现分箱
R中的woeBinning和smbinning包可以实现?自动分箱。
下面介绍woeBinning包。
woeBinning函数
woe.binning对数值变量或者因子变量生成一个受监督的细分和粗分类。
woe.tree.binning对数值变量和因子变量生成监督树状分割。
woe.binning.plot对woe.binning或者woe.tree.binning的分箱解决方案进行数据可视化。
woe.binning.table对woe.binning或woe.tree.binning的分箱解决方案的结果进行表格化保存。
woe.binning.deploy将把woe.binning或woe.tree.binning生成并保存的分箱解决方案部署和应用到(新)数据中。
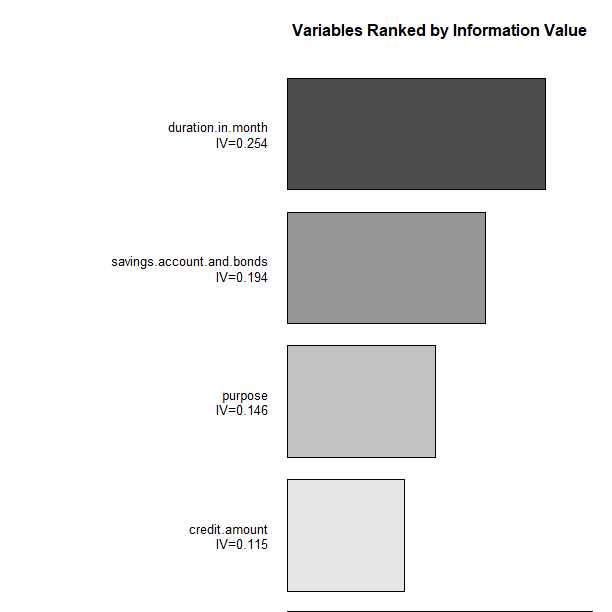
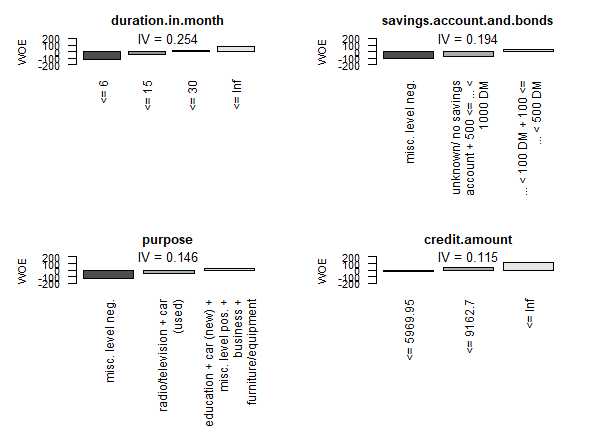
> library(woeBinning) > library(dplyr) > # 使用包自带的数据集germancredit > data( "germancredit") > # 数据集检视 > print(dim(germancredit))#21维,1000条数据 [1] 1000 21 > # 数据集部分变量数据获取 > # 定性变量和定量变量 > df <- germancredit[, c( ‘creditability‘, ‘credit.amount‘, ‘duration.in.month‘, ‘savings.account.and.bonds‘, ‘purpose‘)] > print(head(df)) creditability credit.amount duration.in.month savings.account.and.bonds purpose 1 good 1169 6 unknown/ no savings account radio/television 2 bad 5951 48 ... < 100 DM radio/television 3 good 2096 12 ... < 100 DM education 4 good 7882 42 ... < 100 DM furniture/equipment 5 bad 4870 24 ... < 100 DM car (new) 6 good 9055 36 unknown/ no savings account education > # 自动分箱操作 > binning <- woe.binning(df, ‘creditability‘, df) > # 自动分箱后结果可视化 > woe.binning.plot(binning) > # 分箱解决方案表格化存储 > tabulate.binning <- woe.binning.table(binning)
> tabulate.binning
$`WOE Table for duration.in.month`
Final.Bin Total.Count Total.Distr. bad.Count good.Count bad.Distr. good.Distr. good.Rate WOE IV
1 <= 6 82 8.2% 9 73 3.0% 10.4% 89.0% -124.6 0.093
2 <= 15 349 34.9% 80 269 26.7% 38.4% 77.1% -36.5 0.043
3 <= 30 396 39.6% 128 268 42.7% 38.3% 67.7% 10.8 0.005
4 <= Inf 173 17.3% 83 90 27.7% 12.9% 52.0% 76.6 0.113
6 Total 1000 100.0% 300 700 100.0% 100.0% 70.0% NA 0.254
$`WOE Table for savings.account.and.bonds`
Final.Bin Total.Count Total.Distr. bad.Count good.Count bad.Distr. good.Distr. good.Rate
1 misc. level neg. 48 4.8% 6 42 2.0% 6.0% 87.5%
2 unknown/ no savings account + 500 <= ... < 1000 DM 246 24.6% 43 203 14.3% 29.0% 82.5%
3 ... < 100 DM + 100 <= ... < 500 DM 706 70.6% 251 455 83.7% 65.0% 64.4%
4 Total 1000 100.0% 300 700 100.0% 100.0% 70.0%
WOE IV
1 -109.9 0.044
2 -70.5 0.103
3 25.2 0.047
4 NA 0.194
$`WOE Table for purpose`
Final.Bin Total.Count Total.Distr. bad.Count good.Count bad.Distr.
1 misc. level neg. 9 0.9% 1 8 0.3%
2 radio/television + car (used) 383 38.3% 79 304 26.3%
3 education + car (new) + misc. level pos. + business + furniture/equipment 608 60.8% 220 388 73.3%
4 Total 1000 100.0% 300 700 100.0%
good.Distr. good.Rate WOE IV
1 1.1% 88.9% -123.2 0.010
2 43.4% 79.4% -50.0 0.086
3 55.4% 63.8% 28.0 0.050
4 100.0% 70.0% NA 0.146
$`WOE Table for credit.amount`
Final.Bin Total.Count Total.Distr. bad.Count good.Count bad.Distr. good.Distr. good.Rate WOE IV
1 <= 5969.95 850 85.0% 231 619 77.0% 88.4% 72.8% -13.8 0.016
2 <= 9162.7 100 10.0% 40 60 13.3% 8.6% 60.0% 44.2 0.021
3 <= Inf 50 5.0% 29 21 9.7% 3.0% 42.0% 117.0 0.078
5 Total 1000 100.0% 300 700 100.0% 100.0% 70.0% NA 0.115
> # 分箱解决方案部署和应用到新的数据集(IV值大于0.1的)
> df.with.binned.vars.added <- woe.binning.deploy(df,binning, add.woe.or.dum.var = ‘woe‘,min.iv.total = 0.1)
> View(df.with.binned.vars.added)
> woe.df <- df.with.binned.vars.added %>% dplyr::select(contains( "woe."))
> View(head(woe.df))
>
结果:
以上是关于数据分箱的主要内容,如果未能解决你的问题,请参考以下文章