架构师之路再刷一下思路记录-3
Posted it-worker365
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构师之路再刷一下思路记录-3相关的知识,希望对你有一定的参考价值。
数据库架构设计 - 高可用,度性能,一致性,扩展性 - 数据冗余带来一致性问题
单库->分片(路由,范围,哈希,路由服务)->分片+分组
冗余读库,写库单点
冗余写库-双写可能冲突,两个写库不同的初始值相同的补偿来避免,业务层自己生成唯一ID避免冲突
双主当主从用,两个主只有一个主提供服务(读+写),两一个座位影子服务保证高可用
提升度性能,写库不建立索引,线上读库建立uid索引,线下读库简历time索引,增加读库,增加缓存
业务部直接面向db和cache,服务层屏蔽了底层负责性,不管如何,一致性都是问题
解决一致性问题,1. 中间件,某一个Key有写操作,在不一致窗口内,中间件会将这个key的读操作也路由到主库上 2. 强制读主
如果写操作:淘汰cache,写库;读操作室读cache,读库,放回cache,则可能从库读到旧数据如cache导致不一致
解决
缓存双淘汰,淘汰cache,写数据库,在主从同步延迟窗口时间后,再次发起一个异步淘汰cache的请求
更简单就是cache设超时,这个没啥好说的吧
=======================================================================================
冗余表数据一致性
因为数据库水平切分,不是分区键的查询可能扫描多库,为提升性能,所以需要冗余
Order(oid, info_detail)
T(buyer_id, seller_id, oid)
如果用buyer_id来分库,seller_id的查询就需要扫描多库。
如果用seller_id来分库,buyer_id的查询就需要扫描多库。
T1(buyer_id, seller_id, oid)
T2(seller_id, buyer_id, oid)
同一个数据,冗余两份,一份以buyer_id来分库,满足买家的查询需求;
一份以seller_id来分库,满足卖家的查询需求。
服务层同步写冗余数据
服务层异步写,数据的双写并不再由服务来完成,服务器异步发出一个消息,通过消息总线发给一个专门的数据复制服务来写入冗余数据
线下异步写,数据的双写不再由服务层来完成,而是由线下的另一个服务或者任务来完成,比如通过binlog,最终一致性
根据业务影响的大小,谁小谁先执行
用户下单时,如果“先插入buyer表T1,再插入seller冗余表T2”,当第一步成功、第二步失败时,出现的业务影响是“买家能看到自己的订单,卖家看不到推送的订单”
相反,如果“先插入seller表T2,再插入buyer冗余表T1”,当第一步成功、第二步失败时,出现的业务影响是“卖家能看到推送的订单,卖家看不到自己的订单”
由于这个生成订单的动作是买家发起的,买家如果看不到订单,会觉得非常奇怪,并且无法支付以推动订单状态的流转,此时即使卖家看到有人下单也是没有意义的。
因此,在此例中,应该先插入buyer表T1,再插入seller表T2。
如何保证数据的一致性?
线下启动一个离线扫描工具,不停的对比正表和反表,发现数据不一致,就进行补偿修复
线下扫描增量数据,减小不一致时间窗口
实时线上消息对检测,写入T1发msg1,写入T2发msg2,这时实时订阅服务不停的收消息,假设在一小段时间内没有收到正确的消息对,则发现不一致,进行补偿
=======================================================================================
缓存架构设计
读多写少加缓存优化性能,减少db查询。读取(读取缓存,命中返回,没命中查db再写入缓存)
所以当数据出现变化的时,就会出现不一致的问题,先更新缓存还是淘汰,先操作数据库还是先操作缓存等等问题
更新缓存:数据不但写入数据库,还会写入缓存。缓存不会增加一次未命中,命中率高
淘汰缓存,数据只写入数据库,不写入缓存,会将缓存数据淘汰 - 优选
如果更新缓存的代价很小,则更新缓存,如果代价大则淘汰缓存。因为有的缓存是计算出来的,而不仅仅是更新一个简单的值
当写操作发生时,先写库再淘汰缓存,还是先淘汰缓存,再写库? 如果出现不一致,谁先做对业务影响小谁先执行
结论,先淘汰缓存,再写数据库
缓存架构优化(业务同时关注db和缓存,加入服务层屏蔽数据库和缓存的细节,非主流方案是异步缓存更新,业务线所有的写操作走db,读操作走缓存,由一个异步工具(binlog读取同步)做数据之间的数据同步)
=======================================================================================
缓存与数据库的一致性
先操作缓存,在写库之前,如果读请求发生,可能导致旧数据入缓存,引发数据不一致
如何能做到先发的请求一定先执行? 串行化思路,任务队列其实已经做了任务串行化的工作,多节点部署,多请求队列,多数据库连接
任务队列不能保证串行化,单任务多数据库连接不能保证串行化,多服务单数据库连接不能保证串行化,单服务单数据库连接可能保证串行化,但吞吐量极低,不可行
***结论,不需要全局串行化,只需要让同一个数据的访问能串行化就行,让同一个数据的访问通过同一条db连接执行(连接池选特定的)***
怎么解决全局问题?对服务连接池也改下,加入特定参数
=======================================================================================
主从DB与Cache一致性
单库,服务层的并发读写,缓存与db交差进行,A写操作,淘汰缓存-停,B读操作,缓存未命中,读db加入缓存,A继续写库,后发起的请求B再先发起的请求A中间完成了,可能读到旧数据入缓存
主从同步,读写分离的情况下,同步延迟,读从库读到旧数据
解决,用一个异步的timer或者消息总线异步,写请求发个消息,消费者收到消息之后,异步在1S后淘汰缓存,即使在1S内有脏数据入缓存也会被再次淘汰
还可以无侵入业务系统,新增一个线下读Binlog的异步淘汰模块,读取binlog中的数据,异步淘汰缓存
=======================================================================================
DB主从一致性架构优化
读多写少,一主多从,读写分离,冗余多个读库,写入完成后,主从同步有一个时间差
解决方案: 半同步复制,写请求在主从同步完成之后才返回成功;强制读主库;
数据库中间件,通常情况下,写请求路由到主库,读请求路由到从库,记录所有路由到写库的Key,在经验时间窗内,如果有读请求访问中间件,将请求路由到主库
由于中间件方案成本较高,可以在cache里
=======================================================================================
多库多事物
一般 start transaction do 1 2 3 4 5 commit; 但互联网数据量大高并发,所以每个操作可能在不同的库不同的实例上,无法保证数据一致性
补偿事物:在业务端实施业务逆向操作事物,来保证数据的一致性
事物拆分分析与后置提交优化:想到两阶段提交,先预留资源,协商,最后提交,减少不一致的可能性,原理都是非常类似的
trx1.exec();
trx1.commit();
trx2.exec();
trx2.commit();
优化为:
trx1.exec();
trx2.exec();
trx1.commit();
trx2.commit();
这个小小的改动(改动成本极低),不能彻底解决多库分布式事务数据一致性问题,但能大大降低数据不一致的概率,带来的副作用是数据库连接占用时间会增长,吞吐量会降低。对于一致性与吞吐量的折衷,还需要业务架构师谨慎权衡折衷。
=======================================================================================
mysql并行复制: ( 主从复制 -> 从库使用单线程重放relaylog)
想要多线程并行,但。。。如何分割relaylog才能让并行操作可以保证一致性
1. 相同库上的写操作,使用相同的线程来重复日志,不同库上的写操作可以用多个线程并发重放日志; 如果是单库单表就没戏了- 作者非常支持多库方式构建db架构,可以降低主从同步的延迟
2. 单库情况下,数据的修改和事物的执行在主库也是并行操作的,利用这个,可以将主库上同事并行执行的事物分组,回放时并行执行
3. 新版Mysql将组提交信息存放在GTID中,使用mysqlbinlog工具可以看到组提交内部信息;具有相同的last_committed说明他们在一个组,可以并发回放执行
作者给出了版本对比
mysql5.5 -> 不支持并行复制,对大伙的启示:升级mysql吧
mysql5.6 -> 按照库并行复制,对大伙的启示:使用“多库”架构吧
mysql5.7 -> 按照GTID并行复制
=======================================================================================
Mysql分区表 VS 分库分表
文章看下来就是分区表灵活度不如分库分表,运用不到分区键会很惨,不如分库分表灵活
=======================================================================================
快速回复删掉的数据库
一般数据库架构: 主从结构、主主结构;
全量备份,增量备份: 打包,scp等; 发生问题逐层找回
延迟从库,每隔1小时同步一次主库,同步完之后立即断开
双份1小时延迟从库
可以在从库进行一些允许延时的业务,从而让资源得到充分利用
=======================================================================================
表格属性增加技巧
增加列的问题, alter table add 列锁表时间太长;新表加触发器耗性能不一定装得下,而且可能经常扩展变更
方案
触发器方案
(1)先创建一个扩充字段后的新表user_new(uid, name, passwd, age, sex)
(2)在原表user上创建三个触发器,对原表user进行的所有insert/delete/update操作,都会对新表user_new进行相同的操作
(3)分批将原表user中的数据insert到新表user_new,直至数据迁移完成
(4)删掉触发器,把原表移走(默认是drop掉)
(5)把新表user_new重命名(rename)成原表user
版本号+通用列; 动态扩展,新旧同事存在,但无法建立索引,ext中key冗余
user(uid, name, version, ext)
(1)uid和name有查询需求,必须设计为单独的列并建立索引
(2)version是版本号字段,它对ext进行了版本解释
(3)ext采用可扩展的字符串协议载体,承载被查询的属性
扩展行;也可以动态扩展,新旧同时存在,迁移方便,各个属性都能查;一条记录会变很多行,行数会增加很多
user(uid, key, value)
很早以前有个公司还真用的就是这种;
=======================================================================================
数据库垂直拆分、水平拆分 - 降低数据库大小,提升性能
垂直拆分:将一个属性较多,一行数据较大的表,将属性拆分到不同的表中,以降低单库的大小; - 结构不一样,属性有主键交集
垂直切分的依据:长度较短、访问频率较高的属性放在主表,长度长访问频率低的表放在扩展表,经常一起访问的属性放在一个起
因为row buffer,小而访问频率高的容易加载到Buffer,缓存更多数据,提高命中率
高并发需要主表和扩展表数据,通过服务层访问,不建议join,会消耗过多性能增加复杂度。建议两次查询
水平拆分:以某字段按规则将一个库表上的数据拆分到多个库表上,降低单库表大小 - 结构一样数据不一样
切分规则关系到负载、扩容等因素,切分后按照切分键查询Ok,但如果不按照切分键就麻烦了
针对用户侧的非uid需求,采用建立非Uid属性到uid属性的映射关系架构 - 建立一个索引表记录从查询属性到uid的映射 -> 将映射关系放入缓存 ->可否直接计算映射
计算优化 - 感觉这个还挺有意思的,记录下来
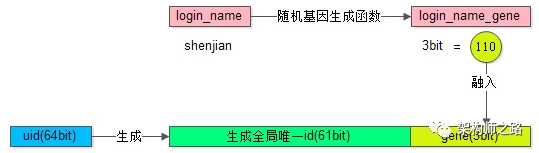
假设分8库,采用uid%8路由,潜台词是,uid的最后3个bit决定这条数据落在哪个库上,这3个bit就是所谓的“基因”。
解决方案:
?在用户注册时,设计函数login_name生成3bit基因,login_name_gene=f(login_name),如上图粉色部分
?同时,生成61bit的全局唯一id,作为用户的标识,如上图绿色部分
?接着把3bit的login_name_gene也作为uid的一部分,如上图屎黄色部分
?生成64bit的uid,由id和login_name_gene拼装而成,并按照uid分库插入数据
?用login_name来访问时,先通过函数由login_name再次复原3bit基因,login_name_gene=f(login_name),通过login_name_gene%8直接定位到库
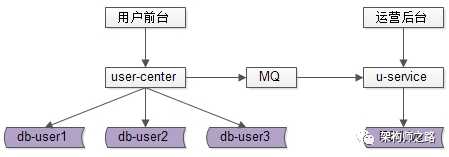
针对运营侧,采用前台与后台分离的架构设计方案,容忍延迟的批量处理任务,可以参考下图,通过MQ或线下异步同步数据处理
=======================================================================================
平滑扩容
双主同步,keepalived,虚拟IP
=======================================================================================
跨库分页,跨多个水平切分数据库,且分库依据与排序依据为不同属性,并需要进行分页查询
单库比如 select * from t_msg order by time offset 200 limit 100
分库时,取3页数据,每个都取3页,再在内存中排序,这种增加了网络传输消耗,服务层二次排序消耗CPU,随着页码增大性能几句下降
从业务上规避,禁止跳页查询,就像我们刷网页,拉下来一点刷出来一点;
这种方式将查询order by time offset 100 limit 100,改写成order by time where time>$time_max limit 100,以后每次查询可以利用前次的时间作为条件,减少后面每次查询的网络传输量
如果业务上可以接受损失精度,可以一些统计类属性可以假定每个库差不多,所以统计db0间接可以假定db1.。。也差不多
二次查询法:???还是没理解透
将select * from T order by time offset 1000 limit 5
改写为select * from T order by time offset 500 limit 5
并投递给所有的分库,注意,这个offset的500,来自于全局offset的总偏移量1000,除以水平切分数据库个数2。
找到返回数据的最小值,二次查询
(1)将order by time offset X limit Y,改写成order by time offset X/N limit Y
(2)找到最小值time_min
(3)between二次查询,order by time between $time_min and $time_i_max
(4)设置虚拟time_min,找到time_min在各个分库的offset,从而得到time_min在全局的offset
(5)得到了time_min在全局的offset,自然得到了全局的offset X limit Y
以上是关于架构师之路再刷一下思路记录-3的主要内容,如果未能解决你的问题,请参考以下文章