k-means聚类
Posted hapyygril
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k-means聚类相关的知识,希望对你有一定的参考价值。
算法:
(1) 随机选择k个初始中心点。
(2) 计算每个数据点到中心点的距离,数据点距离哪个中心点最近就划分到哪一类中。
(3) 把中心点转移到得到的cluster内部的数据点的平均位置。
(4) 重复以上步骤,直到每一类中心在每次迭代后变化不大为止。
k值确定:拐点图:组内误差平方和,SSE(sum of squared error)
SSE= 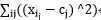
#初始点选择
(1)首先随机选择一个点作为第一个初始类簇中心点。
(2)选择距离该点最远的那个点作为第二个初始类簇中心点
(3)再选择距离前两个点的最近距离最大的点作为第三个初始类簇的中心点。
(4) 以此类推,直至选出K个初始类簇中心点。
#结果评估:平均Silhouette值为:当 大于0.5 时,表明聚类合适
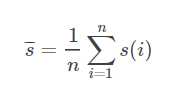
s ( i ) =( b( i )- a ( i ) ) / max ( a ( i ) , b ( i ) )
a(i);对象i到同一簇内其他对象的距离平均值 --凝聚度
b(i) : 计算对象i到其他簇B(j)内所有对象的距离平均 --分散度
遍历其他簇B,计算出最近距离
以上是关于k-means聚类的主要内容,如果未能解决你的问题,请参考以下文章