用深度学习预测专业棋手走法
Posted yunqishequ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用深度学习预测专业棋手走法相关的知识,希望对你有一定的参考价值。

我不擅长国际象棋。
我父亲在我年幼的时候教过我,但我猜他是那些一直让他们的孩子获胜的爸爸之一。为了弥补世界上最受欢迎的游戏之一的技能的缺乏,我做了任何数据科学爱好者会做的事情:建立一个人工智能来击败我无法击败的人。遗憾的是,它不如AlphaZero(甚至普通玩家)好。但我想看看国际象棋引擎在没有强化学习的情况下如何做,以及学习如何将深度学习模型部署到网络上。
比赛在这里!
获取数据
FICS拥有一个包含3亿场比赛,个人走法,结果以及所涉玩家评级的数据库。我下载了所有在2012年的比赛,其中至少有一名玩家超过2000 ELO。这总计约97000场比赛,有730万个走子。胜利分配是:43000次白方胜利,40000次黑方胜利和14000次平局。
极小极大算法
了解如何做一个深度学习象棋AI,我必须首先了解传统象棋AI程序。来自于极小极大算法。Minimax是“最小化最大损失”的缩写,是博弈论中决定零和博弈应如何进行的概念。
Minimax通常用于两个玩家,其中一个玩家是最大化者,另一个玩家是最小化者。机器人或使用此算法获胜的人假设他们是最大化者,而对手是最小化者。该算法还要求有一个棋盘评估函数,来衡量谁赢谁输。该数字介于-∞和∞之间。最大化者希望最大化此值,而最小化者希望最小化此值。这意味着当你,最大化者,有两个走法可以选择的时候,你将选择一个给你更高评估的那个,而最小化者将做相反的选择。这个游戏假设两个玩家都发挥最佳状态并且没有人犯任何错误。
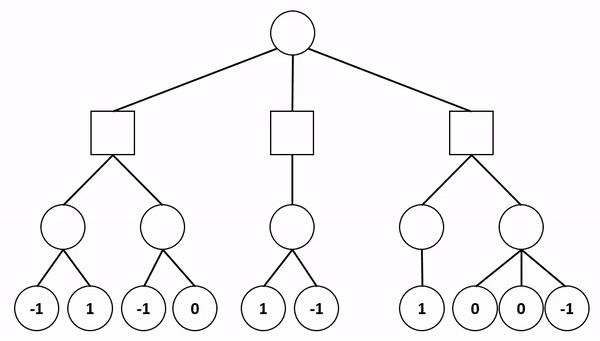
以上面的GIF为例。你,最大化者(圆圈)有三个你可以选择的走法(从顶部开始)。你直接选择的走法取决于你的对手(方块)在走子后将选择的走法。但是你的对手直接选择的走法取决于你走子后选择的走法,依此类推,直到游戏结束。玩到游戏结束会占用大量的计算资源和时间,所以在上面的例子中,选择一个深度,2。如果最小化者(最左边的方块)选择左移,你有1和-1可供选择。你选择1,因为它会给你最高分。如果最小化者选择正确的走法,则选择0,因为它更高。现在是最小化者的回合,他们选择0因为这更低。这个游戏继续进行,一直进行到所有的走子都完成或你的思维时间耗尽。对于我的国际象棋引擎来说,假设白方是最大化者,而黑方是最小化者。如果引擎是白方,则算法决定哪个分支将给出最高的最低分数,假设人们在每次走子时选择最低分数,反之亦然。为了获得更好的性能,该算法还可以与另一种算法结合使用:alpha-beta剪枝。 Alpha-beta剪枝截止系统适用于决定是否应该搜索下一个分支。
深度学习架构
我的研究始于Erik Bernhardsson关于国际象棋深度学习的优秀文章。他讲述了他如何采用传统方法制作AI下棋并将其转换为使用神经网络作为引擎。
第一步是将棋盘转换为输入层的数字形式。我借用了Erik Bernhardsson的编码策略,其中棋盘是一个热编码,每一个方块中都有一个棋子。这总计为768个元素数组(8 x 8 x 12,因为有12种棋子)。
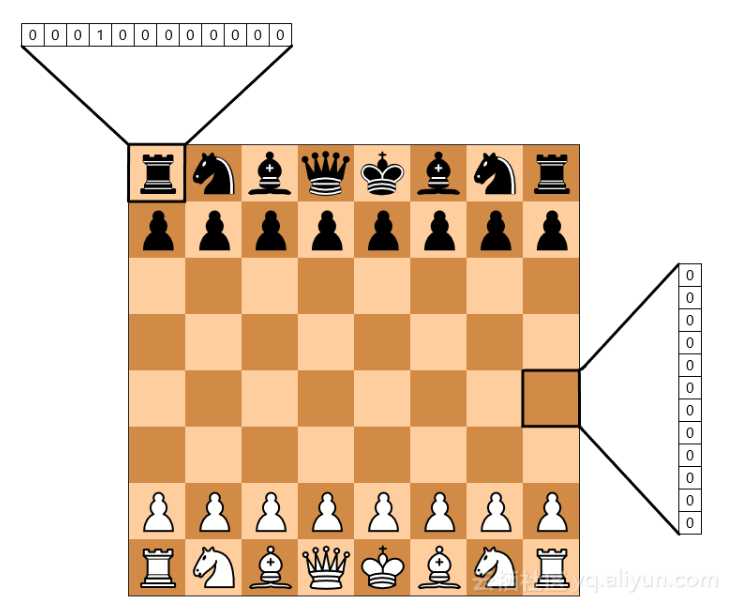
Bernhardsson选择将输出图层设为1表示白方胜利,-1表示黑方胜利,0表示平局。他认为游戏中的每个板位置都与结果有关。如果黑方赢了,每个棋的位置都被训练成“支持黑方”,如果白方赢了,则“支持白方棋”。这允许网络返回介于-1和1之间的值,这将告诉你该位置是否更有可能导致白赢或黑赢。
我想用稍微不同的评估函数来解决这个问题。网络是否能够看到不是白方还是黑方获胜,而是能够看到哪个走子将导致胜利?首先,我尝试将768元素的棋盘表示放入输出,其中一个位置是输入,下一个位置是输出。当然,这没有用,因为这把它变成了一个多分类问题。这导致引擎适当地选择合法走子时出现太多的错误,因为输出层中的所有768个元素可以是1或0。因此,我查阅了Barak Oshri和Nishith Khandwala的斯坦福大学论文《利用卷积神经网络预测国际象棋中的运动》,了解他们如何解决这个问题。他们训练了7个神经网络,其中1个网络是棋子选择器网络。这个网络决定哪一个方格最有可能被移动。其他六个网络专门针对每一个棋子类型,并决定将一个特定的棋子移动到哪里。如果棋子选择器选择了一个带有兵的方格,那么只有棋子神经网络会响应最有可能移动到的方格。
我从他们的想法中借鉴了两个卷积神经网络。第一个,从网络移动,将被训练成采用768元素数组表示并输出专业棋手移动的方格(在方块0和方块63之间)。 第二个网络:移动到网络,将做同样的事情,除了输出层将是专业棋手移动到的地方。我没有考虑谁赢了,因为我认为训练数据中的所有移动都是相对最优的,无论最终结果如何。
我选择的架构是两个128卷积层,带有2x2滤波器,后面是两个1024神经元完全连接层。我没有应用任何池,因为池提供位置不变性。图片左上角的猫就像图片右下角的猫一样。然而,对于国际象棋,,棋子国王的值是完全不同于车兵。隐藏图层的激活功能是RELU,而我将softmax应用到最后一层,因此我基本上得到一个概率分布,其中所有方格的概率总和加起来达到100%。
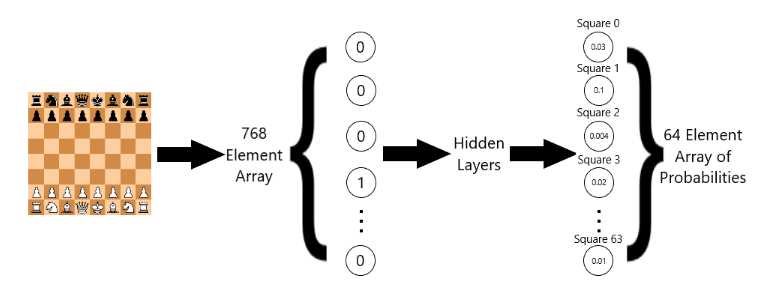
我的训练数据是训练集的600万个位置,其余130万个位置用于验证集。在训练结束时,我从网络上获得了34.8%的验证准确率,并且在转移到网络时获得了27.7%的验证准确率。这并不意味着70%的时间它没有学习合法的走子,这只意味着AI没有像验证数据中的专业玩家那样做出相同的举动。相比之下,Oshri和Khandwala的网络平均验证准确率为37%。
将深度学习与Minimax结合起来
因为现在这是一个分类问题,其中输出可以是64个类之一,这就留下了很大的错误空间。关于训练数据(来自高级别玩家的比赛)的一个警告是,优秀的棋手很少会玩到“将军”。他们知道什么时候输了,通常没有必要跟进整场比赛。这种缺乏平衡的数据使得网络在最终游戏结束时非常混乱。它会选择车来移动,并试图沿对角线移动。如果失败,网络甚至会试图指挥对手的棋子(厚颜无耻!)。
为了解决这个问题,我命令输出的概率。然后,我使用python-chess库获取给定位置的所有合法走子的列表,并选择具有最高结果概率的合法走子。最后,我应用了一个带有惩罚的预测分数方程式,用于选择较不可能的走子:400(选择的走子指数之和)。名单上的合法走子越远,其预测得分就越低。例如,如果从网络移动的第一个索引(索引0)与移动到网络的第一个索引相结合是合法的,那么预测分数是400(0 + 0),这是最高可能分数:400。
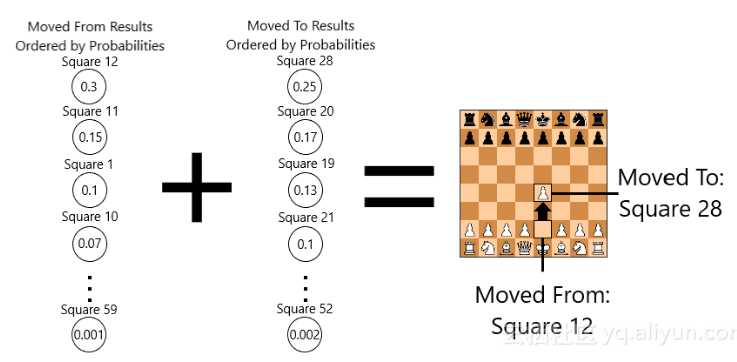
在与材料分数结合使用数字后,我选择了400作为最大预测分数。材料分数是一个数字,可以判断所做的走子是否会捕获一个棋子。根据捕获的棋子,走子的整体得分将得到提升。我选择的材料价值如下:
兵:10,马:500,象:500,车:900,后:5000,王:50000。
这特别有助于残局。在将杀走子将是第二个最可能的合法行动且预测得分较低的情况下,国王的物质价值将超过它。兵的分数如此之低,因为网络在早期比赛中考虑得足够充分,所以如果它是战略举措,它将会采用兵。
然后我将这些分数结合起来,以返回给定任何潜在走子的棋盘的评估。我通过深度为3的minimax算法(使用alpha-beta修剪)提供了这个,并得到了一个可以将杀的可运行国际象棋引擎!
使用Flask和Heroku进行部署
我在Youtube上使用了Bluefever Software的指南,展示了如何通过向flask服务器发出AJAX请求来制作javascript国际象棋UI并通过它来路由我的引擎。 我使用Heroku将python脚本部署到Web并将其连接到我的自定义域:Sayonb.com。
结论
虽然引擎的性能没有我希望的那么好,但是我学到了很多关于AI的基础知识,将机器学习模型部署到web上,以及为什么AlphaZero不使用卷积神经网络来玩游戏!
可以通过以下方式进行改进:
1.通过使用bigram模型LSTM将从网络移动和移动到网络中的时间序列组合在一起。 这可能有助于将移出和移动到决策中,因为每个目前都是独立接近的。
2.通过添加夺取的棋子的位置来改进棋子的赋值(夺取棋盘中心的兵比它在边缘时夺取更有利)。
3.在使用神经网络预测分数和子力分值之间切换,而不是在每个节点使用两者。这可以允许更高的极小极大算法搜索深度。
4.考虑边缘情况,例如:减少孤立自己的兵的可能性,增加马靠近棋盘中心的可能性。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
以上是关于用深度学习预测专业棋手走法的主要内容,如果未能解决你的问题,请参考以下文章