JDK1.8 ConcurrentHashMap源码阅读
Posted cjsblog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK1.8 ConcurrentHashMap源码阅读相关的知识,希望对你有一定的参考价值。
1. 带着问题去阅读
为什么说ConcurrentHashMap是线程安全的?或者说 ConcurrentHashMap是如何防止并发的?
2. 字段和常量
首先,来看一下ConcurrentHashMap中的一些字段和常量,这些在接下来的操作中会用得到
2.1. 常量

从中,我们可以获得以下信息:
- 数组的默认容量是16,最大容量是1<<30
- 当添加元素的时候,将列表转成树的阈值是8。也就是说,相同位置上多个元素是以链表的形式存储的,而当链表的长度(元素的个数)超过8时,将其转为树
- 在对数组扩容的时候,当树中元素个数小于或等于6时,将树转成链表
2.2. 字段

从这些字段中,我们可以获得以下信息:
- 底层是一个数组,且数组的类型是Node,延迟初始化,更重要的是它被 volatile 修饰
- sizeCtl是用于数组初始化和扩容的,当它是负数的时候,表示数组正在进行初始化或扩容,-1表示正在初始化,同时应该注意到它也被 volatile 修饰
2.3. 内部类
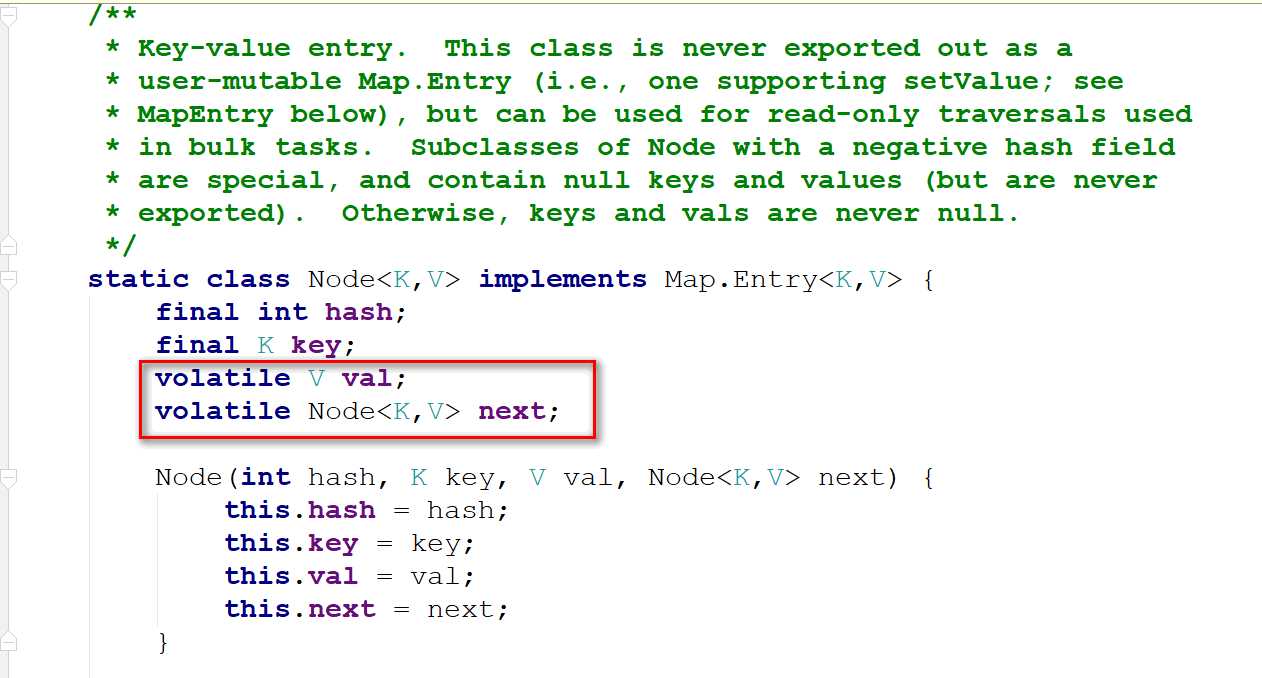
对比1.7里面的HashMap不难发现:
- Node继承自Map.Entry
- 其 value 和 next 都用 volatile 修饰

可以看到,TreeNode继承自Node,主要用于树形结构中。也就是说,TreeNode表示树中的结点。
还有一个TreeBin也是继承自Node
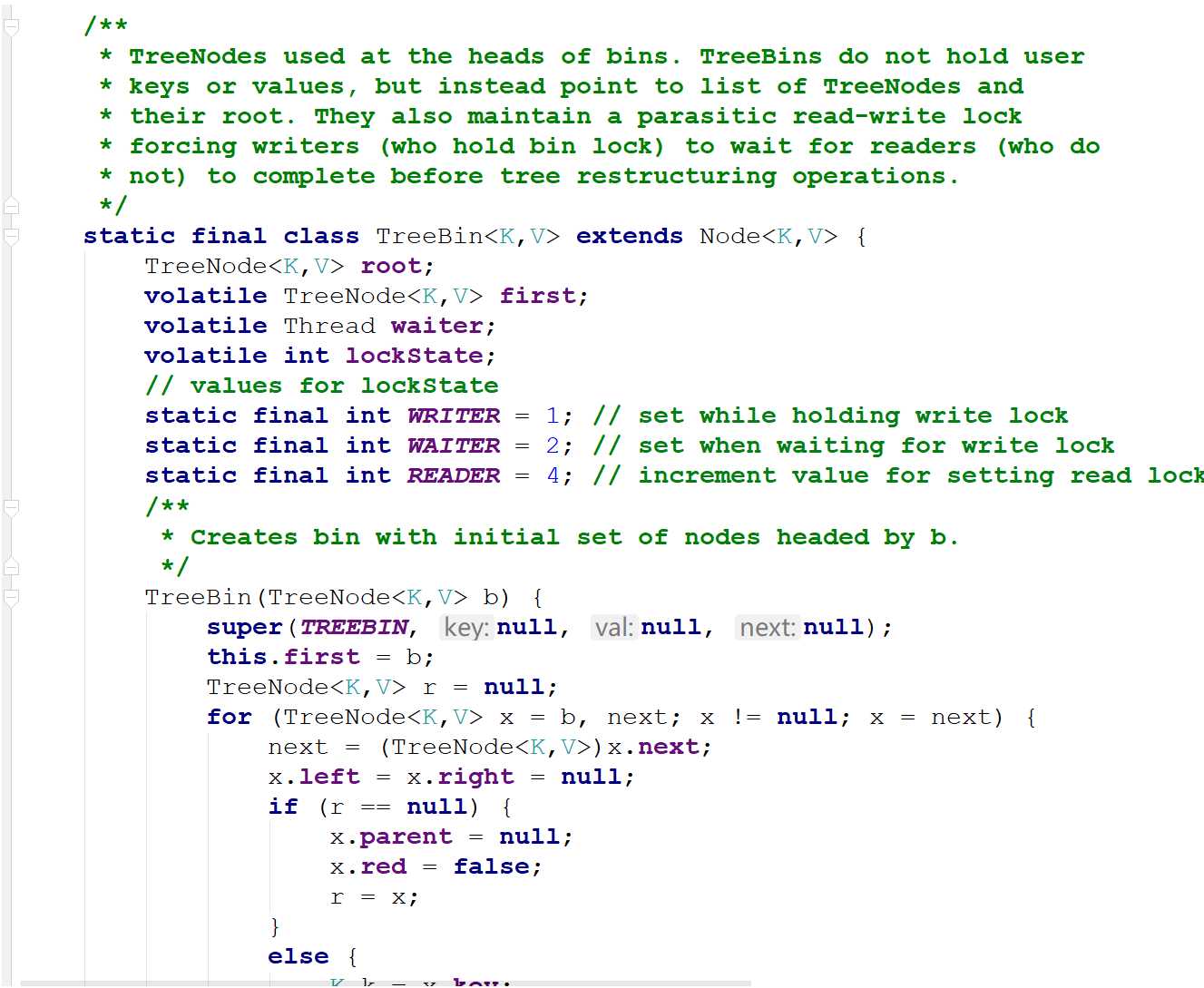
TreeBin表示整个树,TreeNode表示树中的结点
正常情况下,数组中某个位置的元素应该是Node,而Node是一个链表,它后面可能跟了多个Node。
但是,某个位置的节点个数超过阈值(默认8)时,将这个链表转成红黑树,那么此后数组中这个位置的元素就是TreeBin
也就是说,Node表示链表中的节点,TreeNode表示树中的节点,TreeBin表示树
3. 操作
3.1. put

这里,再多看一眼,刚才的putTreeVal()方法

总的来说,是先插入,后调整
大致流程是这样的:
- 如果数组为空,则先初始化数组
- 根据key计算哈希值,进而计算应该在数组的什么位置
- 取出该位置上的元素,如果为空,则直接构造一个Node,并将元素放置于此
- 如果该位置上的元素不为空,则进一步判断是链表还是树(PS:Node还是TreeBin)
- 如果是Node,则遍历链表,如果发现有key相同的元素,则用新值替换旧值,否则构造Node,并将其插入到链表尾部
- 如果是TreeBin,则遍历树,若发现相同key的节点,则用新值替换旧值,否则构造TreeNode,并将其插入到树中
- 插入完成以后,最后再看一下要不要转成树型结构
- 如果旧值不为空,则返回旧值
3.2. resize
在上一步的put操作中,如果数组正在扩容,则帮助扩容

下面看一下扩容

我以前在理解上一直有一个误区,以前我一直以为在数组相同位置上的元素的哈希值都相同,今天我恍然大悟,原来不是这样的,这些元素之所以会在同一个位置是因为通过key的哈希值再结合数组长度计算得出该元素应该在这个位置上,而不同的哈希值可能经过计算也在同一个位置,所以,相同位置的元素的hash值不一定相同,或者说,链表上的元素的hash并不一定都相同,只是恰巧它们在数组的位置相同而已。
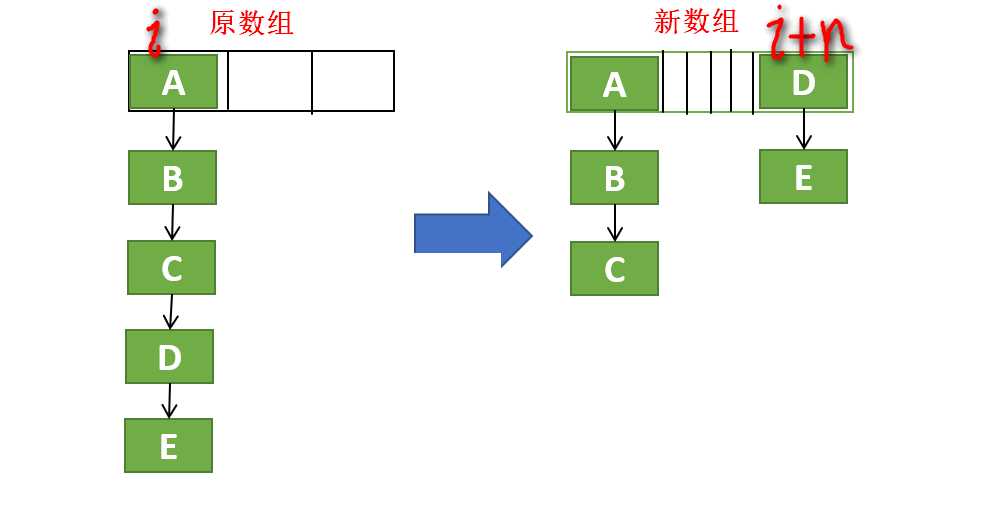
扩容是这样的:
- 新数组的长度是原来的2倍
- 根据不同位置的元素的结构有不同的方式
- 不管原来是链表结构还是树型结构,扩容以后都变成两部分,一部分是hash&n为0的,另一部分是hash&n不为0的,其中n为原数组的长度
- 对于那些hash&n==0的结点,它们在新数组中的位置保持不变,也就是说它们原先在旧数组中是什么位置,现在在新数组中还是什么位置
- 对于那些hash&n != 0的节点,它们在新数组中的位置相比于之前在旧数组中的位置是向后移动了n
- 每个位置在迁移的时候都加锁了
- 扩容后,原来在旧数组中在相同位置的结点在新数组中未必还在相同的位置
- 扩容后,链表没有倒置
- 由于迁移到新数组中时,会将原先一棵树分成两部分(跟链表一样),所以分出来的树中如果结点数小于或等于6,则转成链表
下面是一个示意图,不必拘泥细节,重在意思
3.3. get和remove
删除和获取相对比较简单,不再赘述
至此,可以回答开头我们提出的问题了
sychronized + volatile + CAS
插入、删除、扩容的时候都对数组中相应位置的元素加锁了,加锁用的是synchronized
table数组、Node中的val和next、以及一些控制字段都加了volatile
在更新一些关键变量的时候用到了sun.misc.Unsafe中的一些方法

以上是关于JDK1.8 ConcurrentHashMap源码阅读的主要内容,如果未能解决你的问题,请参考以下文章