Semantic SegmentationSegmentation综述
Posted kk17
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Semantic SegmentationSegmentation综述相关的知识,希望对你有一定的参考价值。
部分转自:https://zhuanlan.zhihu.com/p/37618829
一.语义分割基本介绍
1.1 概念
语义分割(semantic segmentation) : 就是按照“语义”给图像上目标类别中的每一点打一个标签,使得不同种类的东西在图像上被区分开来。可以理解成像素级别的分类任务。
输入: (HW3)就是正常的图片
输出: ( HWclass )可以看为图片上每个点的one-hot表示,每一个channel对应一个class,对每一个pixel位置,都有class数目 个channel,每个channel的值对应那个像素属于该class的预测概率。
 figure1
figure1
1.3评价准则
1.像素精度(pixel accuracy ):每一类像素正确分类的个数/ 每一类像素的实际个数。
2.均像素精度(mean pixel accuracy ):每一类像素的精度的平均值。
2.平均交并比(Mean Intersection over Union):求出每一类的IOU取平均值。IOU指的是两块区域相交的部分/两个部分的并集,如figure2中 绿色部分/总面积。
4.权频交并比(Frequency Weight Intersection over Union):每一类出现的频率作为权重
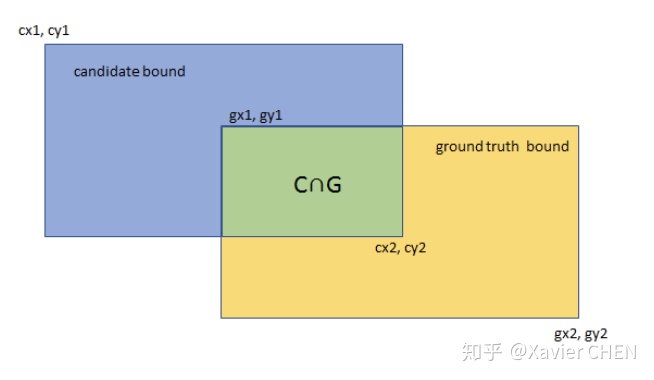 figure2
figure2
二.从FCN 到Deeplab V3+ :语义分割的原理和常用技巧
2.1 FCN
FCN是语义分割的开山之作,主要特色有两点:
1.全连接层换成卷积层
2.不同尺度的信息融合FCN-8S,16s,32s
2.1.1 全连接层换成卷积层
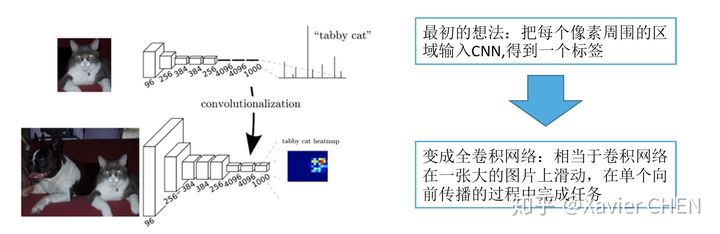 figure3
figure3
以Alexnet的拓扑结构为例
原本的结构:224大小的图片经过一系列卷积,得到大小为1/32 = 7的feature map,经过三层全连接层,得到基于FC的分布式表示。
我们把三层全连接层全都换成卷积层,卷积核的大小和个数如下图中间行所示,我们去掉了全连接层,但是得到了另外一种基于不同channel的分布式表示:Heatmap
举一个例子,我们有一个大小为384的图片,经过替换了FC的Alexnet,得到的是6*6*1000的Heatmap,相当于原来的Alexnet 以stride = 32在输入图片上滑动,经过上采样之后,就可以得到粗略的分割结果。
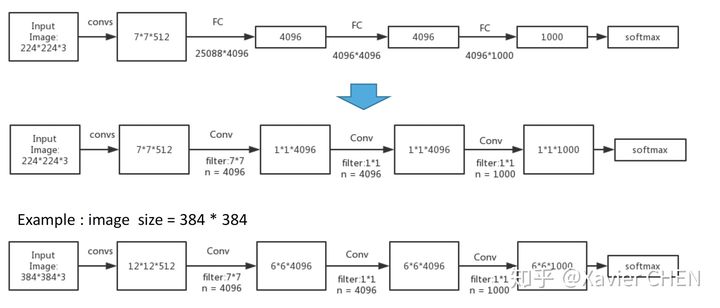 figure4
figure4
2.1.2 不同尺度的信息融合
就像刚刚举的Alexnet的例子,对于任何的分类神经网络我们都可以用卷积层替换FC层,只是换了一种信息的分布式表示。如果我们直接把Heatmap上采样,就得到FCN-32s。如下图
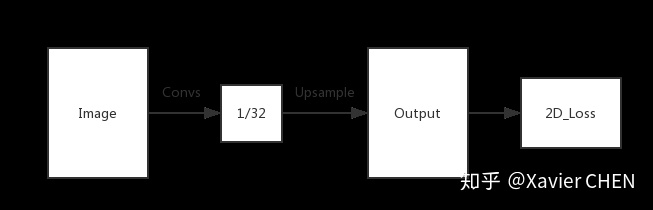 figure5
figure5
但是我们知道,随着一次次的池化,虽然感受野不断增大,语义信息不断增强。但是池化造成了像素位置信息的丢失:直观举例,1/32大小的Heatmap上采样到原图之后,在Heatmap上如果偏移一个像素,在原图就偏移32个像素,这是不能容忍的。
见figure6,前面的层虽然语义信息较少,但是位置信息较多,作者就把1/8 1/16 1/32的三个层的输出融合起来了。先把1/32的输出上采样到1/16,和Pool4的输出做elementwose addition , 结果再上采样到1/8,和Pool3的输出各个元素相加。得到1/8的结果,上采样8倍,求Loss。
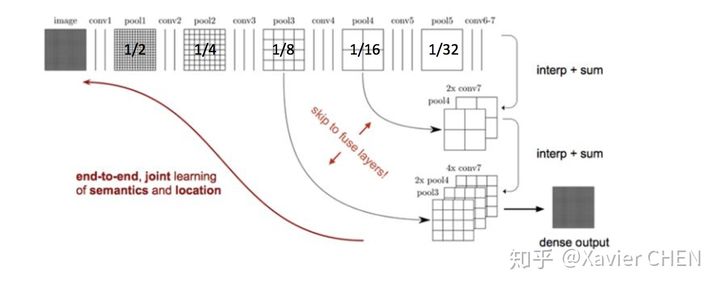 figure6
figure6
2.2 U-net
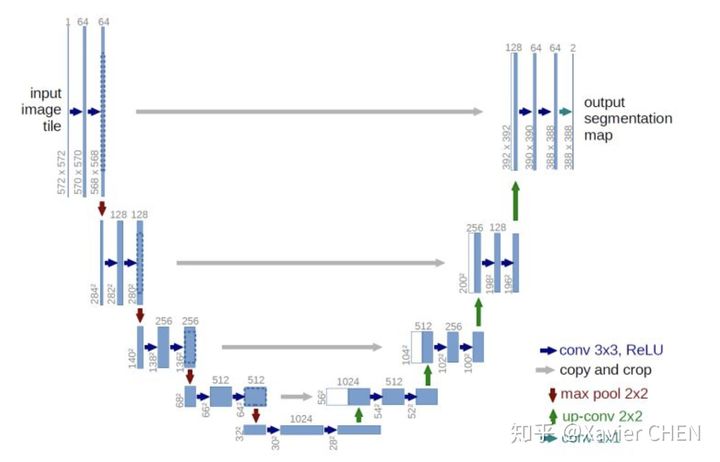 figure7
figure7
U-net用于解决小样本的简单问题分割,比如医疗影片的分割。它遵循的基本原理与FCN一样:
1.Encoder-Decoder结构:前半部分为多层卷积池化,不断扩大感受野,用于提取特征。后半部分上采样回复图片尺寸。
2.更丰富的信息融合:如灰色剪头,更多的前后层之间的信息融合。这里是把前面层的输出和后面层concat(串联)到一起,区别于FCN的逐元素加和。不同Feature map串联到一起后,后面接卷积层,可以让卷积核在channel上自己做出选择。注意的是,在串联之前,需要把前层的feature map crop到和后层一样的大小。
2.3 SegNet
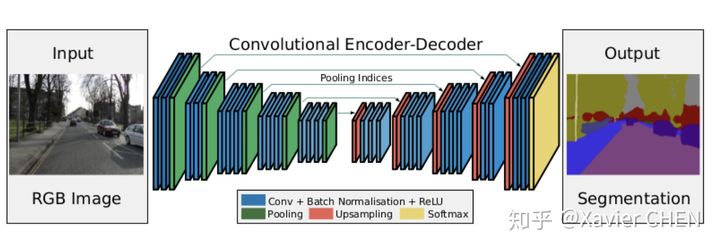 figure 8
figure 8
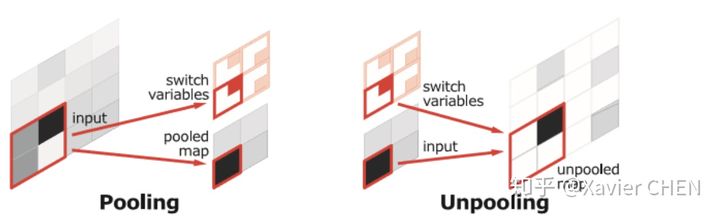
在结构上看,SegNet和U-net其实大同小异,都是编码-解码结果。区别在意,SegNet没有直接融合不同尺度的层的信息,为了解决为止信息丢失的问题,SegNet使用了带有坐标(index)的池化。如下图所示,在Max pooling时,选择最大像素的同时,记录下该像素在Feature map的位置(左图)。在反池化的时候,根据记录的坐标,把最大值复原到原来对应的位置,其他的位置补零(右图)。后面的卷积可以把0的元素给填上。这样一来,就解决了由于多次池化造成的位置信息的丢失。
同时采用了大量的激活层,实验得出激活层越多效果越好
2.4 Deeplab V1
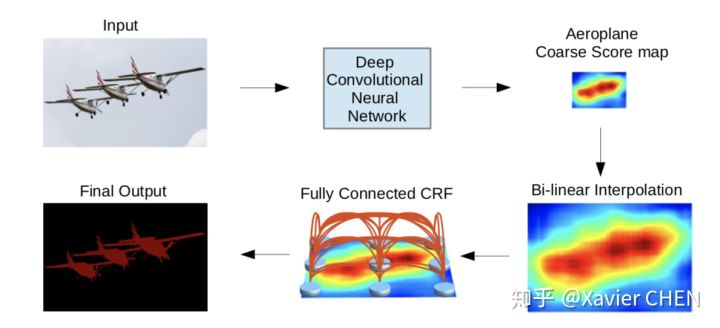 figure10
figure10
这篇论文不同于之前的思路,他的特色有两点:
1.由于Pooling-Upsample会丢失位置信息而且多层上下采样开销较大,把控制感受野大小的方法化成:带孔卷积(Atrous conv)
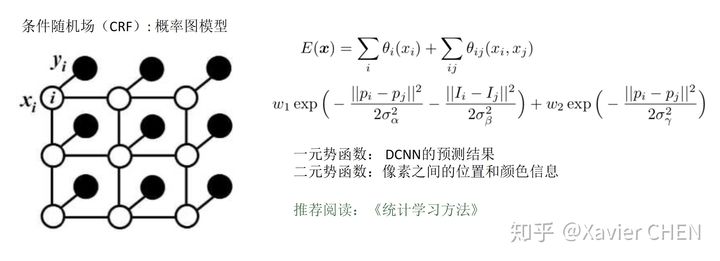
2.加入CRF(条件随机场),利用像素之间的关连信息:相邻的像素,或者颜色相近的像素有更大的可能属于同一个class。
2.4.1 Atrous Conv
如右下图片所示,一个扩张率为2的带孔卷积接在一个扩张率为1的正常卷积后面,可以达到大小为7的感受野,但是输出的大小并没有减小,参数量也没有增大。
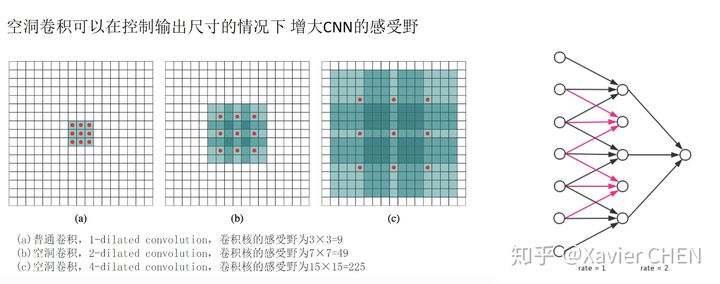 figure 11
figure 11
2.4.2 条件随机场CRF
2.5 PSPnet
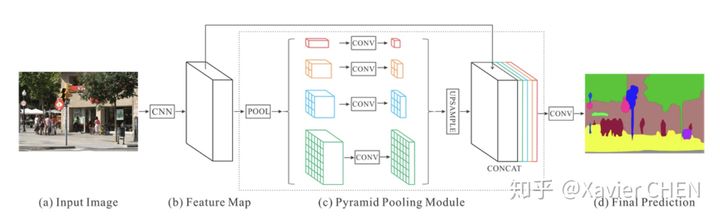 figure12
figure12
原理都大同小异,前面的不同level的信息融合都是融合浅层和后层的Feature Map,因为后层的感受野大,语义特征强,浅层的感受野小,局部特征明显且位置信息丰富。
PSPnet则使用了空间金字塔池化,得到一组感受野大小不同的feature map,将这些感受野不同的map concat到一起,完成多层次的语义特征融合。
2.6 Deeplab V2
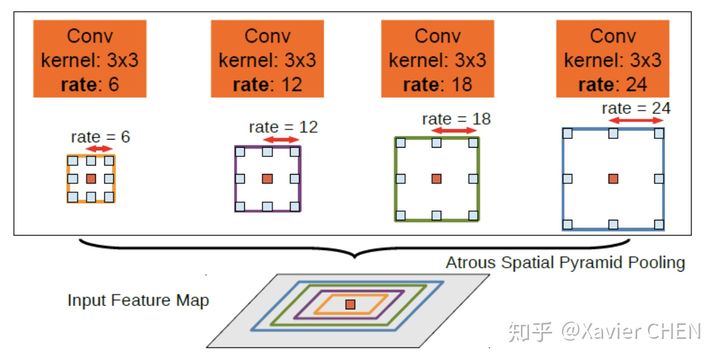 figure 13
figure 13
Deeplab v2在v1的基础上做出了改进,引入了ASPP(Atrous Spatial Pyramid Pooling)的结构,如上图所示。我们注意到,Deeplab v1使用带孔卷积扩大感受野之后,没有融合不同层之间的信息。
ASPP层就是为了融合不同级别的语义信息:选择不同扩张率的带孔卷积去处理Feature Map,由于感受野不同,得到的信息的Level也就不同,ASPP层把这些不同层级的feature map concat到一起,进行信息融合。
方法
i.稠密特征提取的空洞卷积和感受野的扩充
问题:传统DCNN但对于连续的最大池化和降采样导致最后的特征图分辨率严重下降,一般使用FCN,但会带来增加内存和计算时间的问题
解决方法:提出Atrous convolution
Atrous Convolution解释:
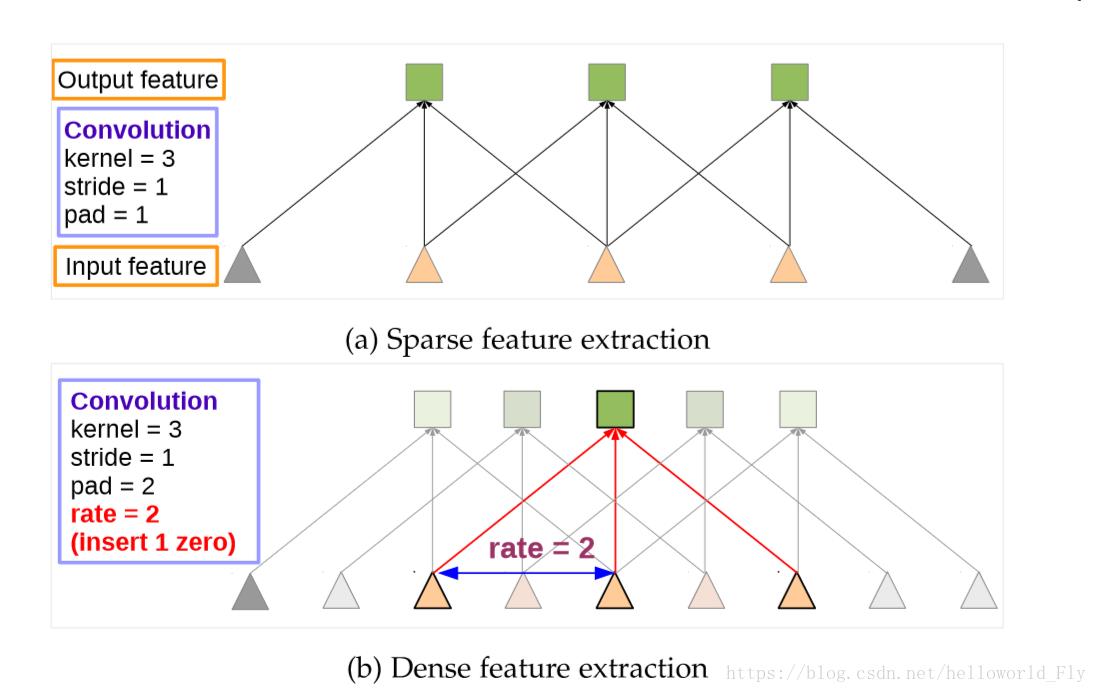
来源于信号处理,对于输入信号,使用长度为K的滤波器加入r采样率进行采样:
对于CNN中如果进行降采样后会出现特征图分辨率降低,而如果改用Atrous,可有效增加特征图分辨率。在最后的特征聚合层,用Atrous代替全连接层。
起初尝试在所有池化层均加入Atrous,增加效果,但计算量太大;改为factor 4和8,保证计算量和准确度。
方法:a.插入空值,保证计算参数不变;b.提取不同尺度的像素信息,插入对应空值,提高感受野的同时能捕捉不同尺度信息。
问题:(rate如何计算?为何Atrous有效?具体如何实现?)
ii.多尺度空间金字塔池化
ASPP从何而来?为何有效?
借鉴SPP网络,多尺度重采样可有效增强特征图效果。
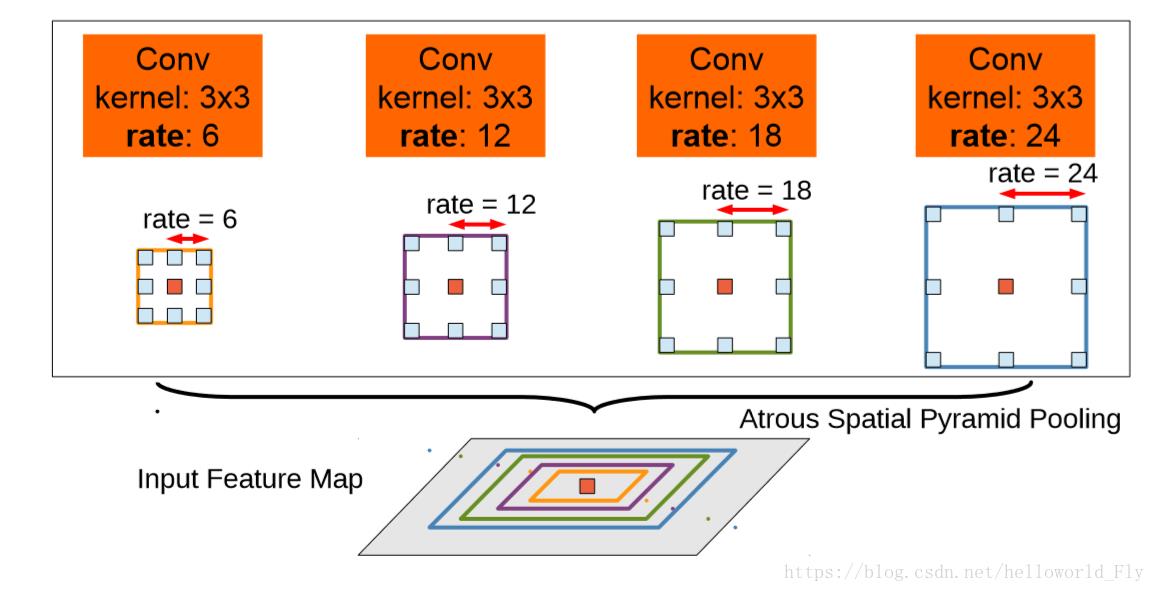
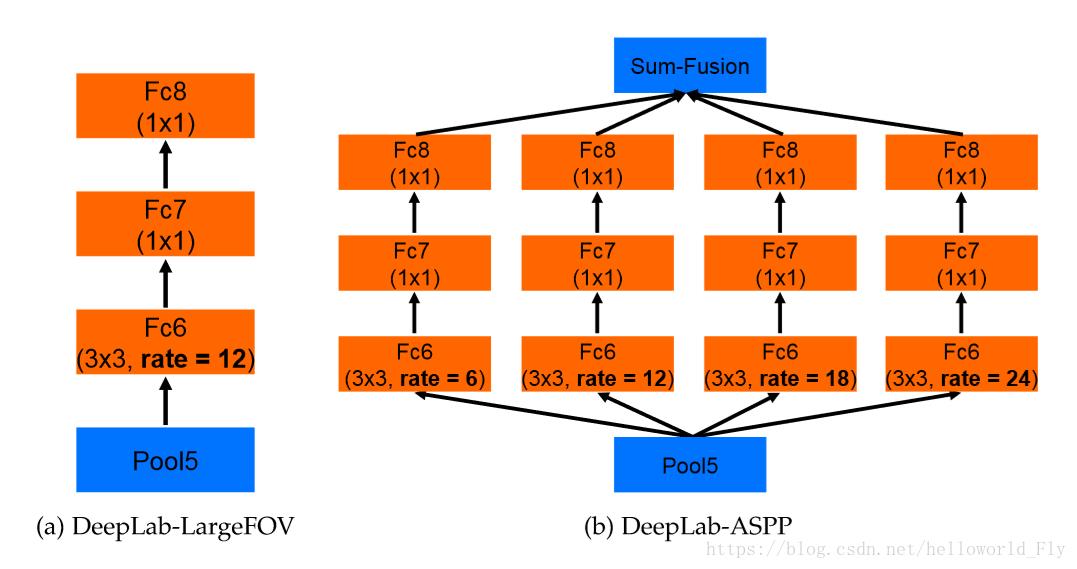
2.7 Deeplab v3
Deeplab v3在原有基础上的改动是:
1.改进了ASPP模块
2.引入Resnet Block
3.丢弃CRF
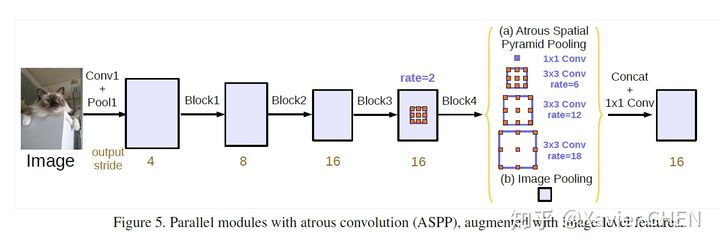 figure14
figure14
- 本文重新讨论了空洞卷积的使用,这让我们在级联模块和空间金字塔池化的框架下,能够获取更大的感受野从而获取多尺度信息。
- 改进了ASPP模块:由不同采样率的空洞卷积和BN层组成,我们尝试以级联或并行的方式布局模块。
- 讨论了一个重要问题:使用大采样率的的空洞卷积,因为图像边界响应无法捕捉远距离信息,会退化为1×1的卷积, 我们建议将图像级特征融合到ASPP模块中。
- 阐述了训练细节并分享了训练经验,论文提出的”DeepLabv3”改进了以前的工作,获得了很好的结果
新的ASPP模块:
1.加入了Batch Norm
2.加入特征的全局平均池化(在扩张率很大的情况下,有效权重会变小)。如图14中的(b)Image Pooling就是全局平均池化,它的加入是对全局特征的强调、加强。
在旧的ASPP模块中:我们以为在扩张率足够大的时候,感受野足够大,所以获得的特征倾向于全局特征。但实际上,扩张率过大的情况下,Atrous conv出现了“权值退化”的问题,感受野过大,都已近扩展到了图像外面,大多数的权重都和图像外围的zero padding进行了点乘,这样并没有获取图像中的信息。有效的权值个数很少,往往就是1。于是我们加了全局平均池化,强行利用全局信息。
2.8 Deeplab v3+
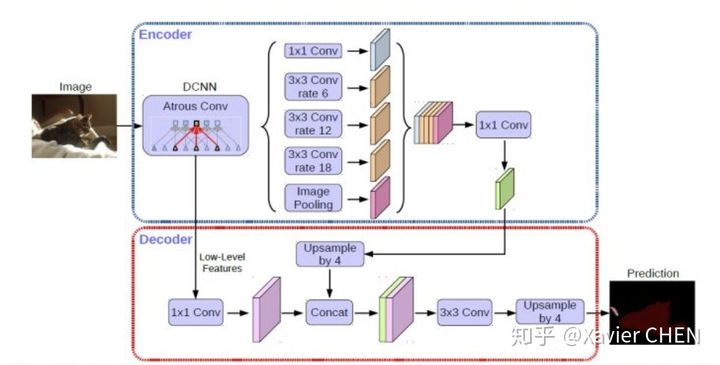
可以看成是把Deeplab v3作为编码器(上半部分)。后面再进行解码,并且在解码的过程中在此运用了不同层级特征的融合。
此外,在encoder部分加入了Xception的结构减少了参数量,提高运行速递。关于Xception如何减少参数量,提高速度。建议阅读论文 : Mobilenet
https://arxiv.org/pdf/1704.04861.pdfarxiv.org
2.9 套路总结
看完这么多论文,会发现他们的方法都差不多,总结为一下几点。在自己设计语义分割模型的时候,遵循一下规则,都是可以涨点的。但是要结合自己的项目要求,选择合适的方法。
1.全卷积网络,滑窗的形式
2.感受野的控制: Pooling+Upsample => Atrous convolution
3.不同Level的特征融合: 统一尺寸之后Add / Concat+Conv, SPP, ASPP…
4.考虑相邻像素之间的关系:CRF
6.在条件允许的情况下,图像越大越好。
5.分割某一个特定的类别,可以考虑使用先验知识+ 对结果进行图像形态学处理
6.此外还有一些其他的研究思路:实时语义分割,视频语义分割
以上是关于Semantic SegmentationSegmentation综述的主要内容,如果未能解决你的问题,请参考以下文章