基于系统调用的系统异常检测的可用数据集总结
Posted xlwang1995
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于系统调用的系统异常检测的可用数据集总结相关的知识,希望对你有一定的参考价值。
因为我主要研究的是通过监控系统调用进而判断系统是否异常,所以最近在整理关于系统异常检测可用的数据集。目前搜集到的数据集主要有UNM,ADFA等。
(一)UNM Dataset
- UNM数据集是新墨西哥大学为了研究入侵免疫系统而采集的数据集。该网站的主页是这样的:
下载的地址是:https://www.cs.unm.edu/~immsec/systemcalls.htm
UNM数据集主要包含在活跃进程下系统调用的若干数据集。 这些进程主要包括守护进程以及那些不是守护进程的应用进程(这些应用程序在大小和复杂程度上分布广泛),还包括了不同种类的入侵(缓冲区溢出,符号链接攻击,木马程序),其中也包括了特权程序,因为这些程序也是可以引起潜在的严重威胁。
正常数据有”静态“和”动态“之分。静态追踪通过运行准备好的脚本,进而在成品环境下收集数据。选择程序选项完全是为了执行程序,而不是为了满足任何实际用户的要求。实时正常数据是在计算机系统成品正常使用期间收集的程序的跟踪。
在某些情况下,我们从多个位置和/或多个版本的程序中获取同一程序的数据。每一个都是不同的数据集;来自一个集合的正常跟踪可能与来自另一个集合的正常跟踪大不相同。在一个位置或程序的某个版本收集的入侵不应该与来自不同集合的正常数据进行比较。
每个跟踪是单个进程从执行开始到结束发出的系统调用的列表。由于程序复杂性的差异以及一些跟踪是守护进程而另一些不是,所以跟踪长度差异很大。
下面是每个程序数据集描述的链接。每个跟踪文件(*.int)列出一对数字,每行一对。一对中的第一个数字是执行进程的PID,第二个数字是表示系统调用的系统调用号。注意,在一个文件中可能有多个进程,它们可能是交错的。
系统调用号和实际系统调用名称之间的映射在文件中系统内核文件中给出。由于使用了各种跟踪包和不同型号的操作系统,所以并非所有程序都使用相同的映射文件。单独的程序页指示哪种映射是适当的。每个映射文件只是一个系统调用名称列表,其中每个名称的行号表示用于该系统调用的编号。行号从0开始。
我们使用了一种叫做“序列时延嵌入”(stide)的方法来建模数据。在训练阶段,stide构建一个数据库,其中包含跟踪中出现的所有预定固定长度的惟一的、连续的系统调用序列。在测试期间,stide将新跟踪中的序列与数据库中的序列进行比较,并报告一个异常度量,指出新跟踪与常规训练数据的差异有多大。
- DRAFT: User Documentation for the STIDE software package
目前该方法已被新墨西哥大学的学生Steve Hofmeyr开发成一款软件。他是新墨西哥大学计算机科学系的一名研究生,是将免疫学的思想应用于计算机安全问题研究项目的一部分。特别是,STIDE是通过识别入侵时可能创建的异常的系统调用序列来帮助检测入侵的。在这种情况下,被考虑的时间序列由单个进程进行的系统调用组成。我们首先记录正常行为模型,然后使用STIDE将连续的系统调用流划分为给定长度的序列,并将他们存储在数据库中。随后,当我们想知道是否攻击了同一个程序的另一个实例时,我们记录进程生成的系统滴用,并将使用STIDE将系统调用的结果序列与正常序列的数据库进行比较。
实际上,因为可用系统调用追踪机制,对我们来说,更容易记录运行在同一时间的若干进程的系统调用。STIDE就是为了处理这种情况而设计的。它可以同时加工多个交织的时间序列,仅仅需要在输入流中每个元素之前都有一个标识符指定它来自哪个系列。在STIDE中,这个标识符是进程ID。
STIDE分析新数据与现有数据库一致性信息最简单的方法是报告异常序列的数量,即,表示输入中不存在于数据库中的序列的数量。
它还可以报告最小汉明距离(轻量级)。给定一个来自数据流的序列和一个来自数据库的序列,我们可以计算不同条目的数量得到两个序列之间的汉明距离。输入序列与数据库中所有序列之间的最小汉明距离就是输入序列的最小汉明距离。
最后一个选项是,他可以报告一个“本地帧数”。当一个过程被利用时,可能会有一个短时间内异常序列的百分比要高得多。虽然在长期运行过程中出现的10个异常可能不会引起关注,但在这30个序列中出现的10个异常可能会引起关注。因此,观察有多少异常是有用的。序列的数量被认为是“本地”的另一个称为大小的局部性帧。在这种模式下,STIDE报告它在任何局域框架中发现额罪大量的一异常。
输入数据由待分析的时间序列组成。它是从标准输入读取的。它应该是一系列正整数对,每行一对,其中第一个整数标识数据流,第二个整数是数据流的元素。数据流的末尾可以由文件的末尾指定,也可以由数字-1的出现指定为流标识符。在我们的工作中,流标识符是进程标识号(PID),数据流的元素是系统调用号。
(二)FADA Dataset
- ADFA-LD
主机配置信息:
- 操作系统:Ubuntu Linux version 11.04
- Apache 2.2.17
- php 5.3.5
- FTP、SSH、mysql14.14使用默认端口开启服务。
- TikiWiki 8.1(一个基于web的协同工具)
- 选择这个版本的原因是因为它有一个已知的远程php代码注入漏洞,从而可以让我们发起基于web的攻击。
这个配置合理概括了当前(ADFA数据集是2012年的一个数据集)市面上最常见的linux local服务器——提供文件共享、数据库服务、远程连接和web服务器的功能,同时也有一些小型的残余漏洞。 在制作这个数据集的时候,配置人员已经非常小心仔细地考虑了渗透测试人员和黑客通常采用的方法,并在目标系统的脆弱性与现实主义之间进行了微妙的权衡。
包含的攻击类型有:
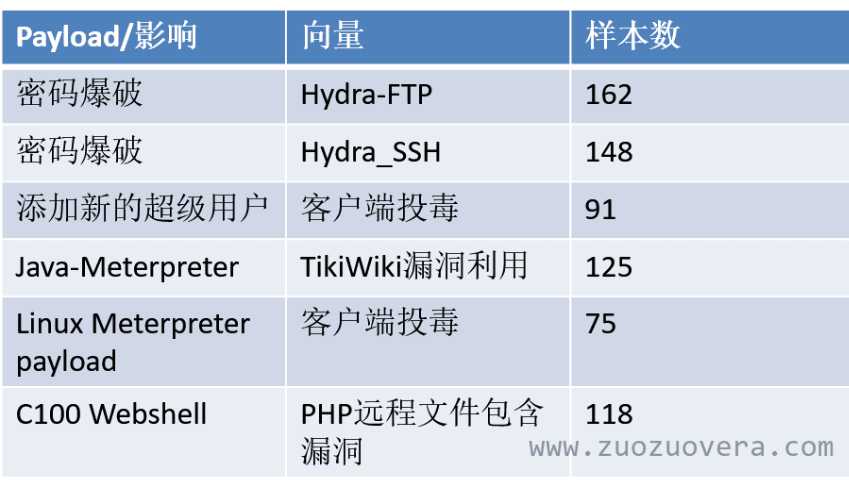
那么为什么设置这些攻击呢?
密码爆破(FTP AND SSH):前两个攻击类型代表了攻击方尝试在开放服务上暴力猜解密码的系统序列。因为FTP和SSH是常用的服务,如果暴露于外部来源,它们就会经常受到攻击。 因此,在这个数据集也包含了这样的攻击类型。
添加新的超级用户:在Linux系统中进行提权的常见方法之一。在该数据集中使用了客户端侧攻击来实现添加新用户的操作。攻击者通过使用Metasploit将一个payload编码为Linux可执行文件,然后在模拟社会工程攻击中将这个可执行文件上传到服务器。然后攻击者就可以使用诸如包含在本地文件和模拟社会工程等技术来远程或本地触发这个注入。
Java-Meterpreter:Meterpreter是免费的Metasploit框架所独有的自定义的有效载荷。Metasploit是最受欢迎的开源黑客工具包,被安全界的人士广泛使用。Meterpreter是增强的功能命令shell,极大地促进了目标系统的远程妥协。TiKiWiKi漏洞用于上传Java Meterpreter有效载荷的副本,该副本在执行时启动了与攻击者计算机的反向TCP连接。一旦shel建立,攻击者就可以在主机上执行各种操作。类似地,使用社会工程等操作上传有效载荷的linux可执行版本,也可以进行各种操作,这代表了Java版本的不同攻击。
C100 WebShell:使用基于PHP的远程文件包含漏洞来上传C100 WebShell,后者用于进一步破坏主机系统并升级权限。C100 WebShell是复杂的PHP代码。通过web浏览器为攻击者提供了非法的GUI界面,从而允许操作底层的操作系统。
这种攻击的集合代表了中级技能水平的黑客可能采用的攻击方式。它利用所有可用的攻击途径,从低级密码猜测到社会社会工程和基于web的攻击到远程攻击,这是代表性的做法, 为IDS评估提供了现代化的攻击手段。
参考文献:
[1] https://baijiahao.baidu.com/s?id=1595426742680707340&wfr=spider&for=pc
[2] https://www.researchgate.net/post/What_are_anomaly_detection_benchmark_datasets
[3] https://www.cs.unm.edu/~immsec/systemcalls.htm
[4] https://www.zuozuovera.cn/archives/918/
以上是关于基于系统调用的系统异常检测的可用数据集总结的主要内容,如果未能解决你的问题,请参考以下文章