google transformer
Posted callyblog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了google transformer相关的知识,希望对你有一定的参考价值。
参考博客路径:https://zhuanlan.zhihu.com/p/47812375
模型结构(transformer没有用到rnn的任何东西)
模型结构如下图:
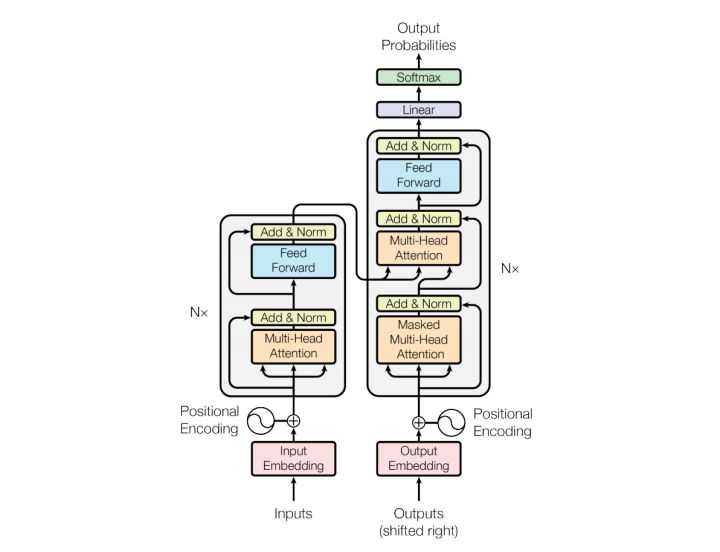
和大多数seq2seq模型一样,transformer的结构也是由encoder和decoder组成。
Encoder
Encoder由N=6个相同的layer组成,layer指的就是上图左侧的单元,最左边有个“Nx”,这里是x6个,相当于上一个layers的输出作为下一个layers的输入,重复6次,第一Layers的输入为词向量。每个Layer由两个sub-layer组成,分别是multi-head self-attention mechanism和fully connected feed-forward network。其中每个sub-layer都加了residual connection和normalisation,因此可以将sub-layer的输出表示为:

Multi-head self-attention(多个self attention拿来收集特征,self attention是拿当前词来与序列中的词来进行attention,查看关联程度,multi head的作用是多个self attention)
熟悉attention原理的童鞋都知道,attention可由以下形式表示:
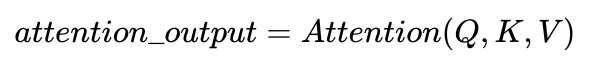
multi-head attention则是通过h个不同的线性变换对Q,K,V进行投影,最后将不同的attention结果拼接起来:
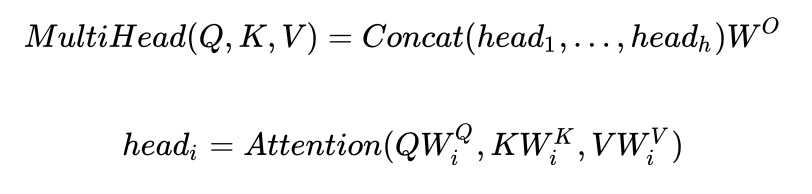
self-attention则是取Q,K,V相同。
另外,文章中attention的计算采用了scaled dot-product(将求出来的attention除以某一个值,防止其变得很大,我的理解是相当于归一化的作用),即:
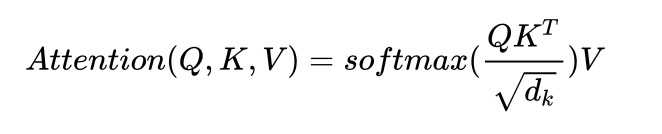
Position-wise feed-forward networks
第二个sub-layer是个全连接层。
Attention
我在以前的文章中讲过,Attention 如果用一句话来描述,那就是 encoder 层的输出经过加权平均后再输入到 decoder 层中。它主要应用在 seq2seq 模型中,这个加权可以用矩阵来表示,也叫 Attention 矩阵。它表示对于某个时刻的输出 y,它在输入 x 上各个部分的注意力。这个注意力就是我们刚才说到的加权。
Attention 又分为很多种,其中两种比较典型的有加性 Attention 和乘性 Attention。加性 Attention 对于输入的隐状态 和输出的隐状态
直接做 concat 操作,得到
,乘性 Attention 则是对输入和输出做 dot 操作。
在 Google 这篇论文中,使用对 Attention 模型是乘性 Attention。
我在之前讲 ESIM 模型的文章里面写过一个 soft-align-attention,大家可以参考体会一下。
Self-Attention
上面我们说attention机制的时候,都会说到两个隐状态,分别是 和
。前者是输入序列第 i个位置产生的隐状态,后者是输出序列在第 t 个位置产生的隐状态。所谓 self-attention实际上就是,输出序列就是输入序列。因而自己计算自己的attention 得分。
Context-Attention
context-attention 是 encoder 和 decoder 之间的 attention,是两个不同序列之间的attention,与来源于自身的 self-attention 相区别。
不管是哪种 attention,我们在计算 attention 权重的时候,可以选择很多方式,常用的方法有
- additive attention
- local-base
- general
- dot-product
- scaled dot-product
Transformer模型采用的是最后一种:scaled dot-product attention。
Scaled Dot-Product Attention
那么什么是 scaled dot-product attention 呢?
通过 query 和 key 的相似性程度来确定 value 的权重分布。论文中的公式长下面这个样子:
scaled dot-product attention 和 dot-product attention 唯一的区别就是,scaled dot-product attention 有一个缩放因子, 叫 。
表示 Key 的维度,默认用 64。
论文里对于 的作用这么来解释:对于
很大的时候,点积得到的结果维度很大,使得结果处于softmax函数梯度很小的区域。这时候除以一个缩放因子,可以一定程度上减缓这种情况。
现在来说下 K、Q、V 分别代表什么:
- 在 encoder 的 self-attention 中,Q、K、V 都来自同一个地方,它们是上一层 encoder 的输出。对于第一层 encoder,它们就是 word embedding 和 positional encoding 相加得到的输入。
- 在 decoder 的 self-attention 中,Q、K、V 也是自于同一个地方,它们是上一层 decoder 的输出。对于第一层 decoder,同样也是 word embedding 和 positional encoding 相加得到的输入。但是对于 decoder,我们不希望它能获得下一个 time step (即将来的信息,不想让他看到它要预测的信息),因此我们需要进行 sequence masking。
- 在 encoder-decoder attention 中,Q 来自于 decoder 的上一层的输出,K 和 V 来自于 encoder 的输出,K 和 V 是一样的。
- Q、K、V 的维度都是一样的,分别用
、
和
来表示
Decoder
和 encoder 类似,decoder 也是由6个相同的层组成,每一个层包括以下3个部分:
- 第一个部分是 multi-head self-attention
- 第二部分是 multi-head context-attention
- 第三部分是一个 position-wise feed-forward network
和 encoder 一样,上面三个部分的每一个部分,每一个都有一个残差连接,每一个后接一个 Layer Normalization。
decoder 和 encoder 不同的地方在 multi-head context-attention mechanism
multi-head self-attention(寻找词之间的关系,第一个时刻的word embedding应该是随机初始化的或者是encoder的最后一个时刻的输出,这里没看懂)
跟seq2seq中的decoder一样,拿上一时刻的输出与前面已经输出的词计算multi-head self attention,产生的attention加权和就是这个时刻的输出。但加入了Mask操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的。
multi-head context-attention
拿这一时刻的 multi-head self-attention 与encoder每个序列的向量的输出进行一个attention,然后进行加权求和,类似于seq2seq attention,最后再拼接起来。multit
position-wise feed-forward network
全连接层
Mask
mask 表示掩码,它对某些值进行掩盖,使其在参数更新时不产生效果。Transformer 模型里面涉及两种 mask,分别是 padding mask 和 sequence mask。
其中,padding mask 在所有的 scaled dot-product attention 里面都需要用到,而 sequence mask 只有在 decoder 的 self-attention 里面用到。
Padding Mask
什么是 padding mask 呢?因为每个批次输入序列长度是不一样的也就是说,我们要对输入序列进行对齐。具体来说,就是给在较短的序列后面填充 0。因为这些填充的位置,其实是没什么意义的,所以我们的attention机制不应该把注意力放在这些位置上,所以我们需要进行一些处理。
具体的做法是,把这些位置的值加上一个非常大的负数(负无穷),这样的话,经过 softmax,这些位置的概率就会接近0!
而我们的 padding mask 实际上是一个张量,每个值都是一个Boolean,值为 false 的地方就是我们要进行处理的地方。
Sequence mask
文章前面也提到,sequence mask 是为了使得 decoder 不能看见未来的信息。也就是对于一个序列,在 time_step 为 t 的时刻,我们的解码输出应该只能依赖于 t 时刻之前的输出,而不能依赖 t 之后的输出。因此我们需要想一个办法,把 t 之后的信息给隐藏起来。
那么具体怎么做呢?也很简单:产生一个上三角矩阵,上三角的值全为1,下三角的值权威0,对角线也是0。把这个矩阵作用在每一个序列上,就可以达到我们的目的啦。
Positional Embedding
现在的 Transformer 架构还没有提取序列顺序的信息,这个信息对于序列而言非常重要,如果缺失了这个信息,可能我们的结果就是:所有词语都对了,但是无法组成有意义的语句。
为了解决这个问题。论文使用了 Positional Embedding:对序列中的词语出现的位置进行编码。
在实现的时候使用正余弦函数。公式如下:
其中,pos 是指词语在序列中的位置。可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。
从编码公式中可以看出,给定词语的 pos,我们可以把它编码成一个 的向量。也就是说,位置编码的每一个维度对应正弦曲线,波长构成了从
到
的等比数列。
上面的位置编码是绝对位置编码。但是词语的相对位置也非常重要。这就是论文为什么要使用三角函数的原因!
正弦函数能够表达相对位置信息,主要数学依据是以下两个公式:
上面的公式说明,对于词汇之间的位置偏移 k, 可以表示成
和
组合的形式,相当于有了可以表达相对位置的能力。
以上是关于google transformer的主要内容,如果未能解决你的问题,请参考以下文章