汇编语言之实验五
Posted bowentianxia
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了汇编语言之实验五相关的知识,希望对你有一定的参考价值。
(1)将下面的程序编译连接,用Debug加载、跟踪,然后回答问题。
assume cs:code,ds:data,ss:stack
data segment
dw 0123h,0456h,0789h,0abch,0defh,0fedh,0cbah,0987h
data ends
stack segment
dw 0,0,0,0,0,0,0,0
stack ends
code segment
start: mov ax,stack
mov ss,ax
mov sp,16
mov ax,data
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
end start
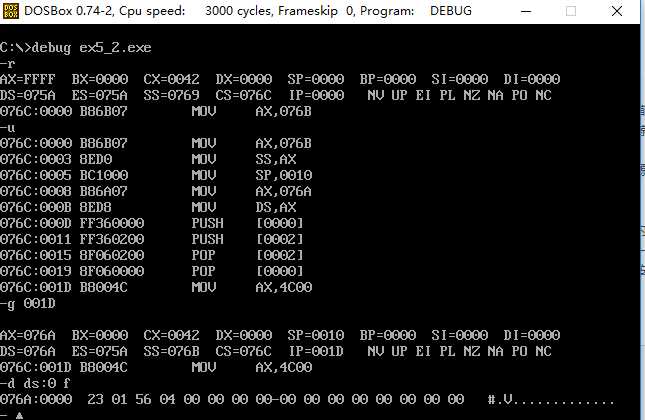
①CPU执行程序,程序返回前,data段中的数据 不变 。
②CPU执行程序,程序返回前,CS=076C,SS=076B,DS=076A 。
③设程序加载后,CODE段的段地址为X,则DATA段的段地址为 X-2 ,STACK段的段地址为 X-1 。
对程序进行编译连接
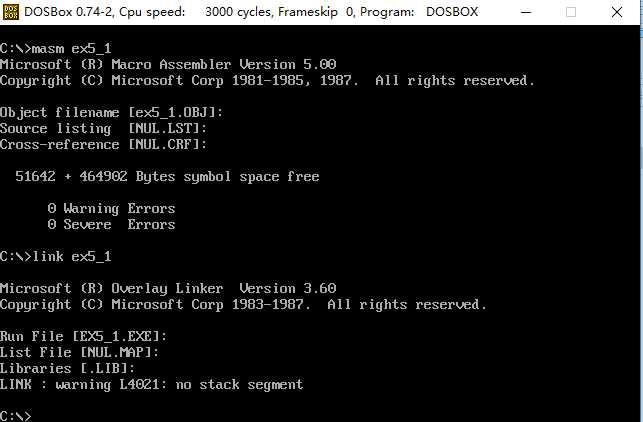
使用r命令查看各寄存器值,并使用u命令进行反汇编。
要求CPU执行程序,程序返回前。通过反汇编,得知应该执行到001D处
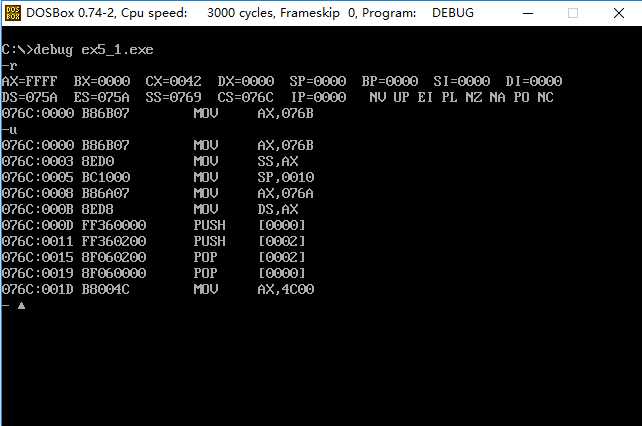
通过g命令执行程序到001D处,通过d命令查看data段中的数据
*1 对比程序执行后data段的数据和执行前的数据,发现数据不变。
因为先执行出栈操作两次,再执行入栈操作两次,两次的顺序相反,正好将先出栈的数据后进栈,后出栈的数据先进栈。所以data中的数据没有发生变化。
*2 通过执行后的结果可知cs=076C,ss=076B,ds=076A
*3 通过第二小问的结构可推断出 DATA段的段地址为 X-2 ,STACK段的段地址为 X-1 。
(2)将下面的程序编译连接,用Debug加载、跟踪,然后回答问题。
assume cs:code,ds:data,ss:stack
data segment
dw 0123h,0456h
data ends
stack segment
dw 0,0
stack ends
code segment
start: mov ax,stack
mov ss,ax
mov sp,16
mov ax,data
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
end start
①CPU执行程序,程序返回前,data段中的数据 不变 。
②CPU执行程序,程序返回前,CS= 076CH ,SS= 076BH ,DS= 076AH 。
③设程序加载后,CODE段的段地址为X,则DATA段的段地址为 X-2 ,STACK段的段地址为 X-1 。
④对于如下定义的段:
name segment
……
name ends
如果段中的数据占N个字节,则程序加载后,该段实际占有的空间为 ((N+15)/16)*16 。
编译连接运行,进入debug调试,反汇编,查看data段中数据
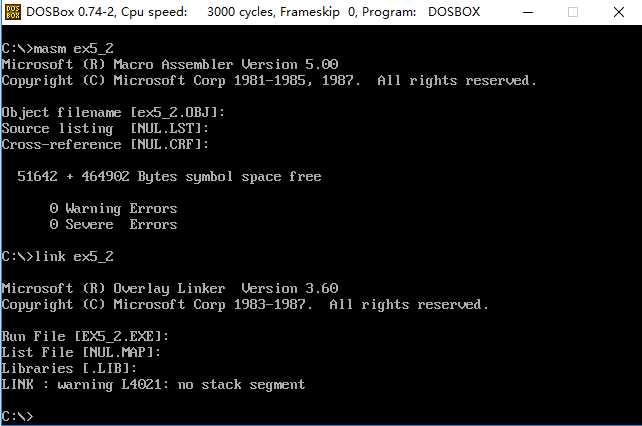
*1 对比程序执行后data段的数据和执行前的数据,发现数据不变。
因为先执行出栈操作两次,再执行入栈操作两次,两次的顺序相反,正好将先出栈的数据后进栈,后出栈的数据先进栈。所以data中的数据没有发生变化。
*2 通过执行后的结果可知cs=076C,ss=076B,ds=076A
*3 通过第二小问的结构可推断出 DATA段的段地址为 X-2 ,STACK段的段地址为 X-1 。
*4 N分为被16整除和不被16整除。
当N被16整除时: 占有的空间为(N/16)*16
当N不被16整除时: 占有的空间为(N/16+1)*16,N/16得出的是可以整除的部分,还有一个余数,余数肯定小于16,加上一个16。
程序加载后分配空间是以16个字节为单位的,也就是说如果不足16个字节的也分配16个字节。
两种情况总结成一个通用的公式:((N+15)/16)*16
这篇文章讲这个还挺详细的,可以参考参考 https://blog.csdn.net/friendbkf/article/details/48212887
(3)将下面的程序编译连接,用Debug加载、跟踪,然后回答问题。
assume cs:code,ds:data,ss:stack
code segment
start: mov ax,stack
mov ss,ax
mov sp,16
mov ax,data
mov ds,ax
push ds:[0]
push ds:[2]
pop ds:[2]
pop ds:[0]
mov ax,4c00h
int 21h
code ends
data segment
dw 0123h,0456h
data ends
stack segment
dw 0,0
stack ends
end start
①CPU执行程序,程序返回前,data段中的数据 不变 。
②CPU执行程序,程序返回前,CS= 076AH ,SS= 076EH ,DS= 076DH 。
③设程序加载后,CODE段的段地址为X,则DATA段的段地址为 X+3 ,STACK段的段地址为 X+4 。
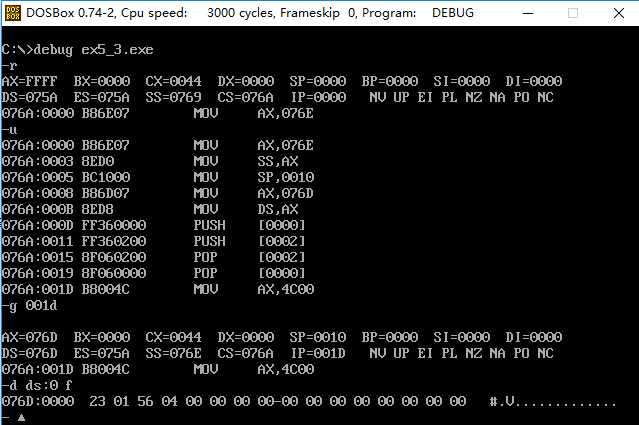
*1 对比程序执行后data段的数据和执行前的数据,发现数据不变。
因为先执行出栈操作两次,再执行入栈操作两次,两次的顺序相反,正好将先出栈的数据后进栈,后出栈的数据先进栈。所以data中的数据没有发生变化。
*2 通过执行后的结果可知cs=076A,ss=076E,ds=076D
*3 通过第二小问的结构可推断出 DATA段的段地址为 X+3 ,STACK段的段地址为 X+4 。
(4)如果将(1)、(2)、(3)题中的最后一条伪指令“end start”改为“end”(也就是说,不指明程序的入口),则哪个程序仍然可以正确执行?请说明原因。
答:第三条程序仍然可以正确执行,如果不指明入口位置,则程序从所分配的空间开始执行,前2个是数据段,只有从第3条开始是指令代码。
(1)(2)题是将数据段写在前面,但是(3)题是将数据段写在后面,将指令代码写在前面。所以,第三条程序仍然可以正确执行。
(5)程序如下,编写code段中代码,将a段和b段中的数据依次相加,将结果存到C段中。
assume cs:code
a segment
db 1,2,3,4,5,6,7,8
a ends
b segment
db 1,2,3,4,5,6,7,8
b ends
c segment ; 在集成软件环境中,请将此处的段名称由c→改为c1或其它名称
db 8 dup(0)
c ends ; 改的时候要成对一起修改
code segment
start:
;?
code ends
end start
编写后的代码:
assume cs:code
a segment
db 1,2,3,4,5,6,7,8
a ends
b segment
db 1,2,3,4,5,6,7,8
b ends
c segment
db 0,0,0,0,0,0,0,0
c ends
code segment
start:
mov ax,a
mov ds,ax
mov ax,b
mov es,ax
mov ax,c
mov ss,ax
mov bx,0
mov cx,8
s: mov ax,[bx]
mov ss:[bx],ax
mov ax,es:[bx]
add ss:[bx],ax
inc bx
loop s
mov ax,4c00h
int 21h
code ends
end start
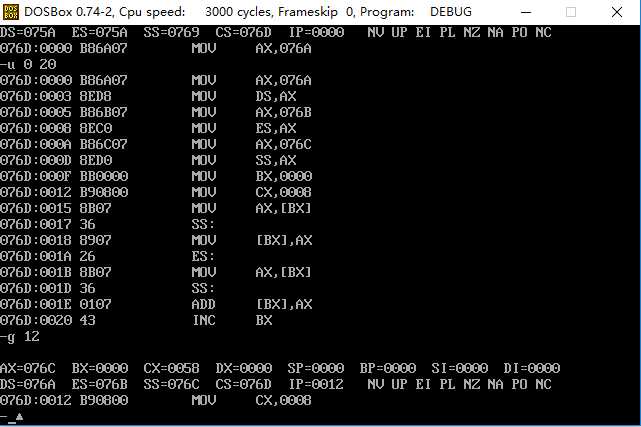
反汇编可知先执行到哪里,
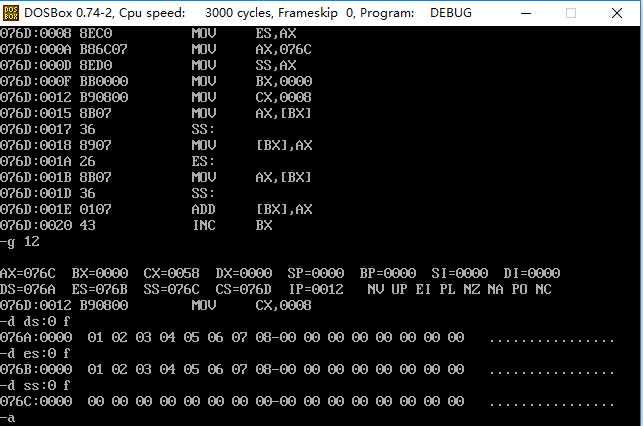
执行复制前,查看a,b,c段的值
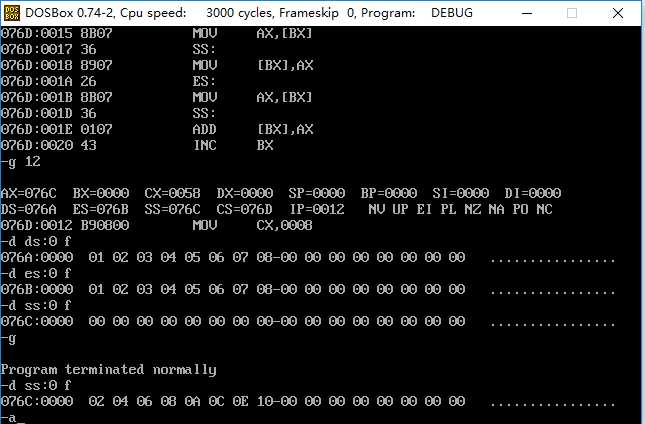
执行所有的代码后查看c段的值
(6)程序如下,编写code段中代码,用PUSH指令将A段中的前8个字型数据,逆序存储到B段中。
assume cs:code
a segment
dw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0eh,0fh,0ffh
a ends
b segment
dw 8 dup(0)
b ends
code segment
start:
;?
code ends
end start
编写源代码:
assume cs:code
a segment
dw 1,2,3,4,5,6,7,8,9,0ah,0bh,0ch,0dh,0eh,0fh,0ffh
a ends
b segment
dw 0,0,0,0,0,0,0,0
b ends
code segment
start:
mov ax,a
mov ds,ax
mov ax,b
mov ss,ax
mov sp,10h
mov bx,0
mov cx,8
s:
push ds:[bx]
add bx,2
loop s
mov ax,4c00h
int 21h
code ends
end start
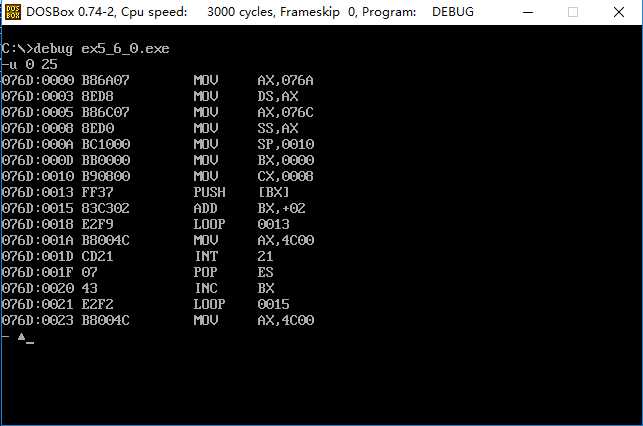
通过u得知执行位置,查看b段的值;
全部执行后,再查看b段的值
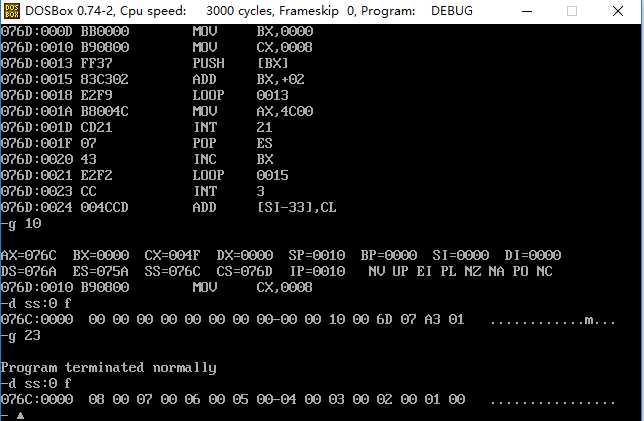
发现 b 的 8 个字单元为 a 段前 8 个字节的逆序
总结:这次实验做的不顺利,尤其是第5,6个实验,使用d命令查看段的值时,出现了问题,好在最后解决了。
以上是关于汇编语言之实验五的主要内容,如果未能解决你的问题,请参考以下文章