列表字典
Posted taotao0228
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了列表字典相关的知识,希望对你有一定的参考价值。
3.1.1定义一个list
定义一个列表:list=[‘李雷‘,‘韩梅梅‘,‘哈哈哈‘,100]
定义一个空list:list=[]
把李雷取出来,角标、下标、索引都是一个意思(list[0])
把100取出来有两种方法,一种是从左边数,一种是从右边数,需要注意的是,从左边数的话,从0开始计数;如果从右边数,那么从-1开始计数
print (list[3])
print(list[-1])
如果下标值不存在,报错是IndexError: list index out of range,下标越界
print(list[10])
3.1.2增删改查
在list末尾增加一个元素abc list.append(‘abc‘)
在指定位置增加元素,如果下标存在,那么在指定的下标位置添加元素;如果下标不存在,那么直接在list末尾增加
list.insert(4,‘yangyang‘)
list.insert(10,‘北京‘)
查list的长度 print(‘list的长度是‘,len(list)
list=[‘李雷‘, ‘韩梅梅‘, ‘哈哈哈‘, 100, ‘yangyang‘, ‘abc‘, ‘北京‘]
把韩梅梅改成拼音 list[1]=‘hanmeimei‘#先找到下标,赋值
不传下标,默认删除最后一个元素 list.pop()
传下标,删除指定元素 list.pop(0)
remove要传待删除的元素 list.remove(‘哈哈哈‘)
传入不存在的下标,报错,报IndexError: pop index out of range list.pop(20)
传入不存在的元素,报x not in list list.remove(‘不存在的元素‘)
删除指定的元素 del list[-1]
清空list list.clear()
根据下标来取值 print(list[3])
查询某个元素在list中出现的次数 res=list.count(‘哈哈哈‘)
list=[‘李雷‘, ‘韩梅梅‘, ‘李雷‘, 100, ‘yangyang‘, ‘abc‘, ‘北京‘]
如果元素出现多次,返回的是第一次的下标 index=list.index(‘李雷‘)
如果元素不存在,报错,报 ‘呵呵‘ is not in list index=list.index(‘呵呵‘)
反转list.reverse()
数字升序排列list.sort()
数字降序排列 list.sort(reverse=True)
把list2加入到一个list1中 list1.extend(list2)
布尔类型:True、False
判断李雷同学是否在列表中:
list=[‘李雷‘, ‘韩梅梅‘, ‘哈哈哈‘, 100, ‘yangyang‘, ‘abc‘, ‘北京‘]
if list.count(‘李雷‘)>0:
print(‘李雷同学存在‘)
if ‘李雷‘in list:
print(‘李雷同学存在‘)
判断李是否在列表中 此时会报错
3.1.3.循环
list=[‘李雷‘, ‘韩梅梅‘, ‘王子‘, ‘杨洋‘]
for s in list:
print(‘s的值是%s‘%s)
结论:如果直接循环一个list,那么每次取得是list里面的每一个元素
另一种复杂的方法不建议使用:
用while循环也麻烦,不推荐使用:
list=[‘李雷‘, ‘韩梅梅‘, ‘王子‘, ‘杨洋‘]
index=0
while index<len(list):
print(list[index])
index+=1
同时取到下标和值
方法一:
list=[‘李雷‘, ‘韩梅梅‘, ‘王子‘, ‘杨洋‘]
for i in range(len(list)):
print("下标是%s,值是%s"%(i,list[i]))
方法二:
for index,i in enumerate(list):
print(‘%s===>%s‘%(index,i))
|
英[??nju:m?re?t] |
美[??nu:m?re?t] |
此时打印出来的下标显示从0开始
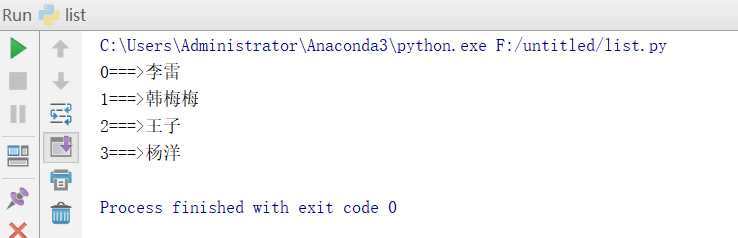
如果想打印出的下标不是从0 开始,这个只是展示的出来的是1,实际还是从0开始的
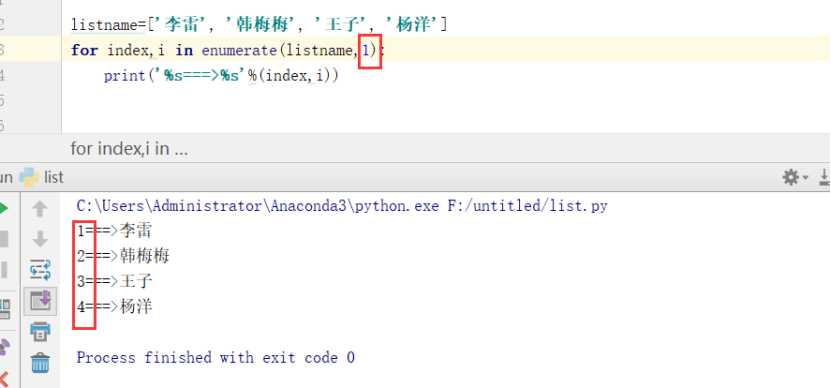
choice=[‘注册‘,‘登录‘,‘购物‘,‘退出‘]
print("输入编号进入对应的操作")
for index,c in enumerate(choice,1):
print("%s===>%s"%(index,c))
3.1.4多维数组,一般就到二维,三维使用不多
二维数组:
list1=[1,2,3,[‘a‘,‘b‘,‘c‘]]
list2=[1,2,3,[‘a‘,‘b‘,‘c‘],[‘嘿嘿‘,‘哈哈哈‘]]
三维数组:
list3=[1,2,3,[‘a‘,‘b‘,‘c‘,[‘嘿嘿‘,‘哈哈哈‘]]]
想把list2中的嘿嘿改成坏蛋
先找到[‘嘿嘿‘,‘哈哈哈‘],然后再找嘿嘿
想把呵呵呵,增加到list3娃娃的前面#一定注意中括号的个数
list3=[1,2,3,[‘a‘,‘b‘,‘c‘,[‘娃娃‘,‘哈哈哈‘]]]
list3[3][3].insert(0,‘呵呵呵‘)
print(list3)
3.1.5切片:list取值的一种方式,它指定范围取值,原则:顾头不顾尾
想取3到6
list=[1,2,3,4,5,6,7,8,9,10]
print(list[2:5])#顾下标2,不顾下标5
如果想取3到6,则print(list[2:6])
如果前面的下标没有写,代表从最前面开始取
如果后面的下标没有写,代表取到最后面
如果只写冒号,代表全部都取
如果步长是负数的时候,那么从右往左取值
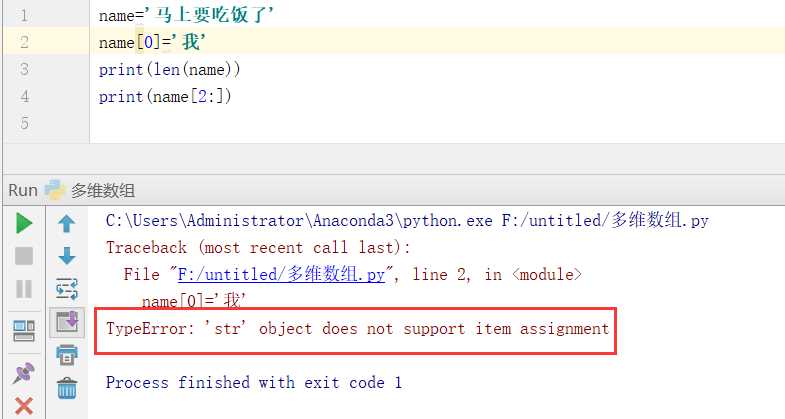
下标、索引、切片同样适用于字符串,字符串也是可以循环的
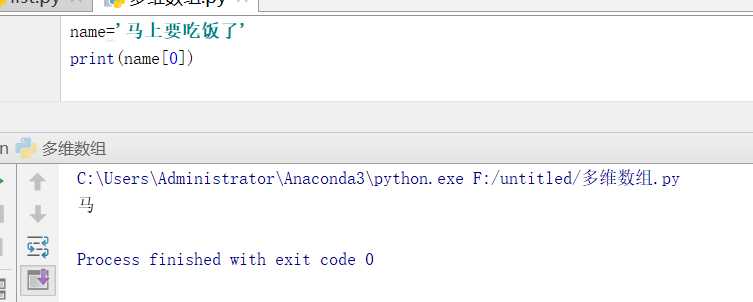
字符串一旦定义好,虽然通过下标可以取值,但是不能通过下标修改字符串的值,除非重新定义字符串
3.2字典
先用数组的形式来存储学生的信息:
stus=[‘李雷‘,‘韩梅梅‘,‘小花‘]
stu_info=[
[‘李雷‘,18,‘男‘,‘北京‘],
[‘韩梅梅‘,20,‘女‘,‘天津‘],
[‘小花‘,25,‘女‘,‘上海‘],
]
for stu in stu_info:
if stu[0]==‘李雷‘:
print(stu)
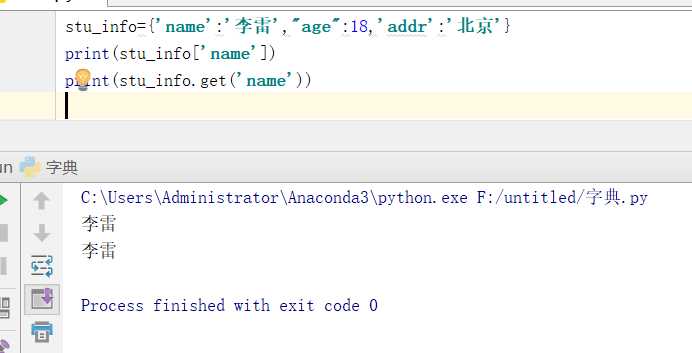
3.2.1定义一个空字典:
stu_info={}
stu_info=dict()
3.2.2字典增删改查
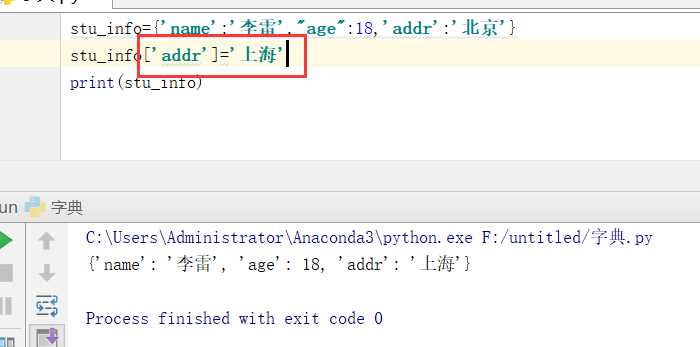
改:
新增:
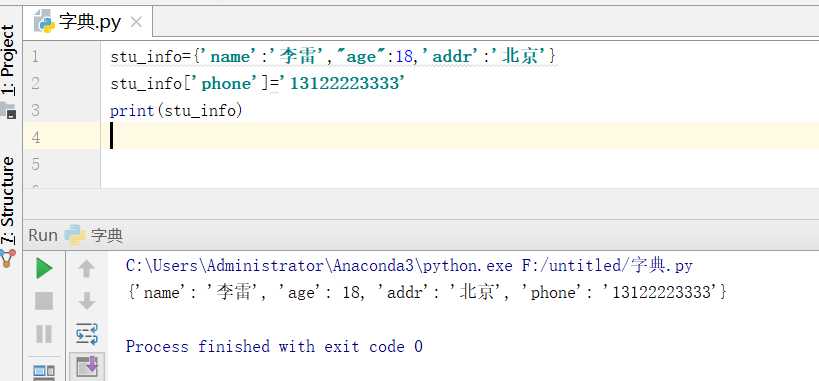
总结:key存在,修改value值;key不存在,新增key
setdefault:仅对不存在的key有效,如果key已经存在,使用setdefault,不会更改key的value值
删:
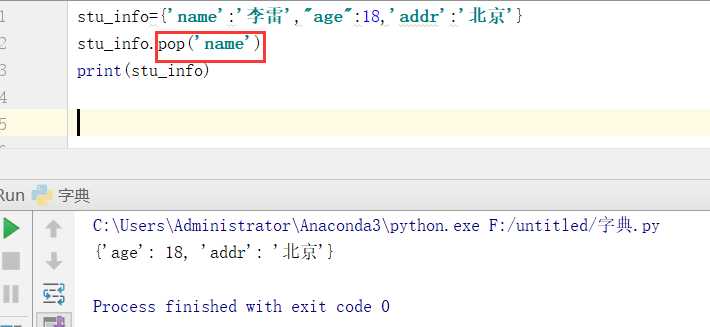
清空字典: stu_info.clear()
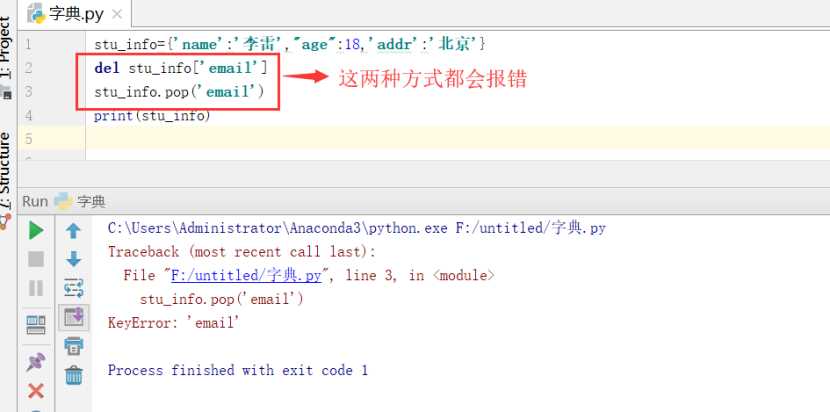
删除指定元素del stu_info[‘name‘]
从字典里面随机删除一个元素:stu_info.popitem()
把字典d2加到字典d1中
d1={‘b‘:1}
d2={‘a‘:‘y‘}
d1.update(d2)
print(d1)
打印字典中所有的key、value
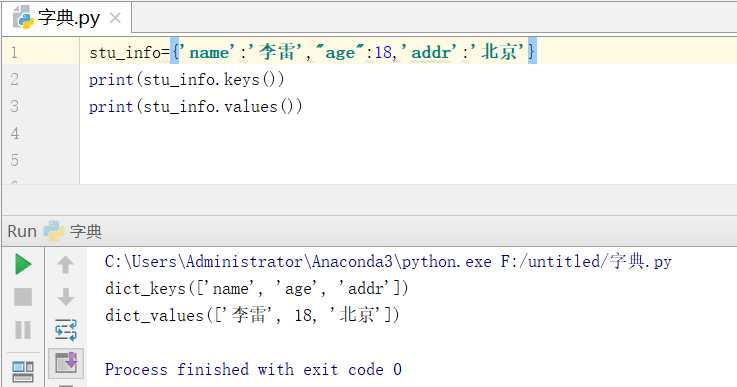
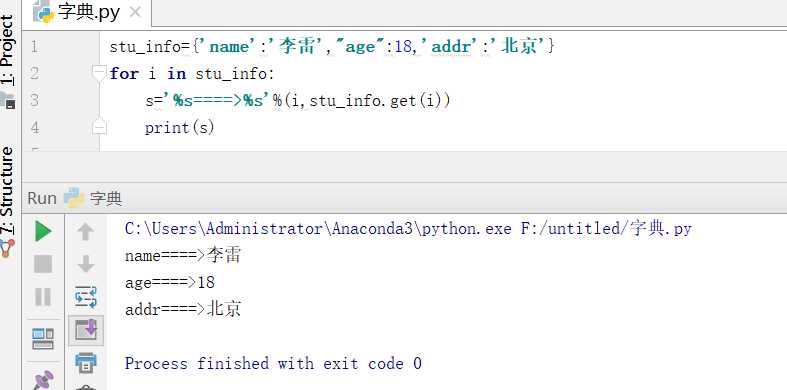
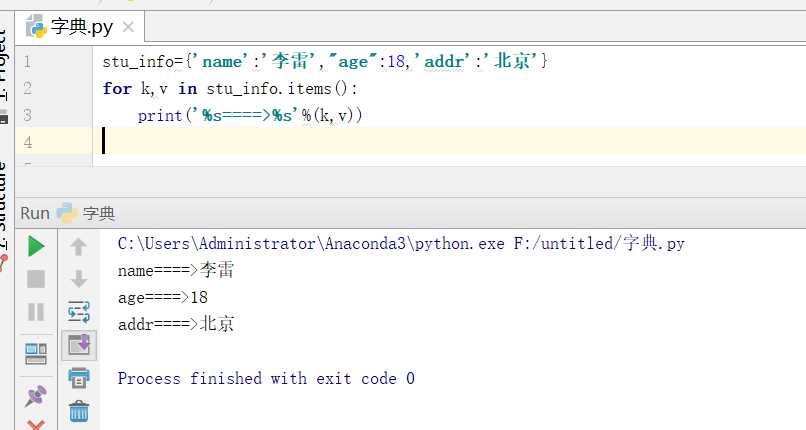
3.2.3字典循环
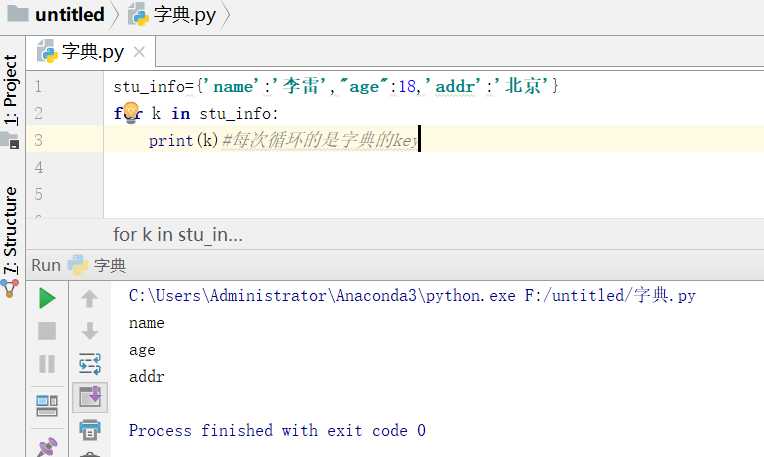
同时取到keyvalue的两种方法:方法一更快捷
方法一:
方法二:

以上是关于列表字典的主要内容,如果未能解决你的问题,请参考以下文章