train_test_split, 关于随机抽样和分层抽样
Posted fengff
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了train_test_split, 关于随机抽样和分层抽样相关的知识,希望对你有一定的参考价值。
https://zhuanlan.zhihu.com/p/49991313
在将样本数据分成训练集和测试集的时候,应当谨慎地考虑一下是采用纯随机抽样,还是分层抽样。
通常,数据集如果足够大,纯随机抽样的方式,将样本数据分成两个子集是没有太大的问题。
如果不是,纯随机抽样肯可能会导致抽样数据偏差,影响训练效果,降低预测模型预测的准确性。
设想调查公司需要做1000份抽样调查,调查的问题和性别可能有较大的相关性。如果想让调查结果代表全国男性和女性对这些问题的看法,假设全国人口男女比例大致为60:40,那么在1000份问卷也应当尽量保持男女比例达到同样的比例,即参加问卷调查的男女数差不多是600和400。
这个就是分层抽样。
如果参加问卷的男女数比例很不一样,比如女性占到了60%或更多,那么调查结伦就会出现重大偏差。
使用sklearn.model_selection.train_test_split,参数stratify即用来指定按照某一特征进行分层抽样,生成训练集和测试集。
看一下随机抽样和分层抽样时,按照某一特征的取值,在训练集的占比情况。
income_count = housing[‘income_cat‘].value_counts().sort_index()
print(‘
After categorized:
{}‘.format(income_count))
income_count.plot.bar()
plt.show()
print(‘Overall dataset, distribution of each category: (%)‘)
print(income_count/len(housing)*100)
# random split
train_set, test_set = train_test_split(housing, random_state=42)
train_set_income_count = train_set[‘income_cat‘].value_counts().sort_index()
print(‘
Random split train dataset, distribution: (%)‘)
print(train_set_income_count/len(train_set)*100)
# stratify split
train_set, test_set = train_test_split(housing,
stratify=housing[‘income_cat‘], random_state=42)
train_set_income_count = train_set[‘income_cat‘].value_counts().sort_index()
print(‘
Startify split train dataset, distribution: (%)‘)
print(train_set_income_count/len(train_set)*100)
得到结果如下:
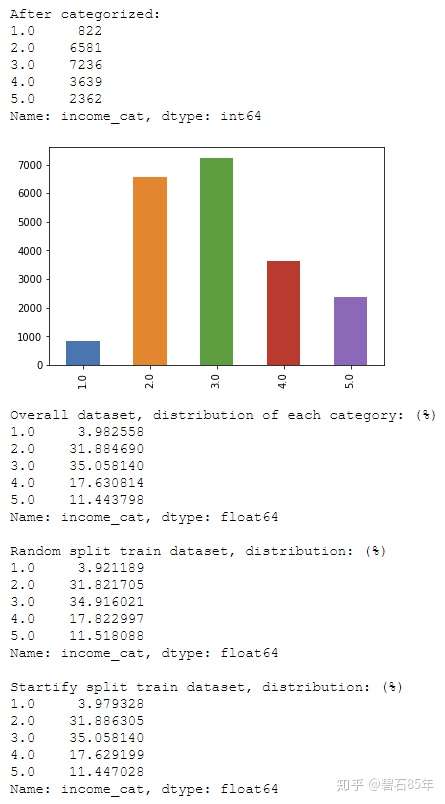
可以看到分层抽样所分出来的训练集(和测试集)数据在关键特征上具有和总体数据集上基本一致的分布。
因此采用分层抽样来生成训练集和测试集将会更严谨。
以上是关于train_test_split, 关于随机抽样和分层抽样的主要内容,如果未能解决你的问题,请参考以下文章