Kubernetes网络方案的三大类别和六个场景
Posted 163yun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes网络方案的三大类别和六个场景相关的知识,希望对你有一定的参考价值。
欢迎访问网易云社区,了解更多网易技术产品运营经验。
本文章根据网易云资深解决方案架构师 王必成在云原生用户大会上的分享整理。

今天我将分享个人对于网络方案的理解,以及网易云在交付 Kubernetes 场景时的一些网络实践。
本文分为两部分:
第一部分:常见容器网络方案;
第二部分:网易云基于 VPC 深度集成的 Kubernetes 网络实践。
常见容器网络方案
常见容器网络方案分类
常见的容器网络方案可以从协议栈层级、穿越形态、隔离方式这三种形式进行划分。

协议栈层级:
第一种:协议栈二层。协议栈二层比较好理解,在以前传统的机房或虚拟化场景中比较常见,就是基于桥接的 ARP+MAC 学习,它有什么缺陷呢?它最大的缺陷是广播。因为二层的广播,会限制节点的量级。
第二种:协议栈三层(纯路由转发)。协议栈三层一般基于 BGP,自主学习整个机房的路由状态。它最大的优点是它的 IP 穿透性,也就是说只要是基于这个 IP 的网络,那此网络就可以去穿越。显而易见,它的规模是非常有优势,且具有良好的量级扩展性。但它也存在问题:在实际部署过程中,因为企业的网络大多受控。比如,有时企业网络的 BGP 是基于安全考虑不给开发者用,或者说企业网络本身不是 BGP,那这种情况下你就没办法了。
第三种:协议栈二层加三层。为什么会出现这种方案?在说二层加三层的优点之前,先提一下它的缺点。缺点是节点内部是一个子网,这对于运维同学来说很苦恼。因为大家都习惯利用传统的云化场景,希望每一个独立可见的应用有一个独立的 IP,且不会改变。这一点,二层加三层做不到。但是这个方案比较符合 Kubernetes 对于 Pod 网络假设,Pod 会漂移,IP 也会改变,不变的是 Service 和 Ingress。
但它的优点是它能够解决纯二层的规模性问题,又能解决纯三层的各种限制问题,特别是在云化 VPC 场景下可以利用 VPC 的三层转发能力。所以,如今你看到的实际部署 Kubernetes 的网络方案中,二层加三层也比较多。后面的章节,我们再详述那些常见的方案。
穿越形态:
按穿越的形态划分,这个与实际部署环境十分相关。穿越形态分为两种:Underlay、Overlay。
Underlay:在一个较好的一个可控的网络场景下,我们一般利用 Underlay。可以这样通俗的理解,无论下面是裸机还是虚拟机,只要网络可控,整个容器的网络便可直接穿过去 ,这就是 Underlay。
Overlay:Overlay 在云化场景比较常见。Overlay 下面是受控的 VPC 网络,当出现不属于 VPC 管辖范围中的 IP 或者 MAC,VPC 将不允许此 IP/MAC 穿越。出现这种情况时,我们都利用 Overlay 方式来做。
隔离方式:
隔离方式与多种户型相关(用户与用户之间的隔离方式),隔离方式分为 FLAT、VLAN、VXLAN 三种:
FLAT:纯扁平网络,无隔离;
VLAN:VLAN 机房中使用偏多,但实际上存在一个问题?就是它总的租户数量受限。众所周知,VLAN 具有数量限制。
VXLAN:VXLAN 是现下较为主流的一种隔离方式。因为它的规模性较好较大,且它基于 IP 穿越方式较好。
大家如今看到的所有的容器网络方案,都是由这三种不同的分类所组建起来的。
常见容器网络方案
这些是目前在实际部署中的所有容器网络方案。

Calico:基于 BGP 的三层 Underlay。它的 IP 隧道是当网络受控时的一种妥协的三层 Overlay 且支持 Network policy。
Contiv:Contiv 方案,功能非常全,我们可以看到它有二层桥接,基于 VLAN 的网络 ;有三层路由,基于 BGP 的网络;同时它可以支持 Overlay,通过 VXLAN,去应对一些受控的网络环境,提供 ACI 去支持网络策略。
Flannel:host-gw 模式,节点内部子网,节点之间通过路由指过去。但是这种方式存在限制。当它直接指引过去时,要求你所有节点在同个二层里。因为你直接指过去,将不能穿越不同子网。
在不能穿越子网时,应该如何处理?通过 VXLAN 的方式来解决,它可以帮助你把报文在二层网络上穿越。VPC vRouter,是公有云厂商的一些场景,通过自定义路由,Flannel 帮助你完成与各个不同公有云厂商的 VPC vRouter 对接。目前在云化场景里面,这是一个非常主流的方案。
Openshift SDN:基于 VXLAN 的二层+三层 Overlay 方案,同时支持 network policy,数据面基于 OVS 流表实现。
Kubenet + VPC 自定义路由:在公有云平台中,它自行搭建 Kubernetes 集群时使用较多。它会利用公有云平台本身自带的 VPC vRouter,配合 Kubernetes 自带的节点子网方式,用路由方式去完成整个容器网络的转发。
传统机房自定义路由:比如你的 BGP 不管用且受控,或不是 BGP。应该怎么办?这种情况,我们在实际部署时也遇到过。首先,运维将这个核心路由进行配置。每个节点对应一条核心路由,也可以使用。
目前大家看到的所有容器网络方案,都可以应用到前面的三个分类。
分别适用什么场景
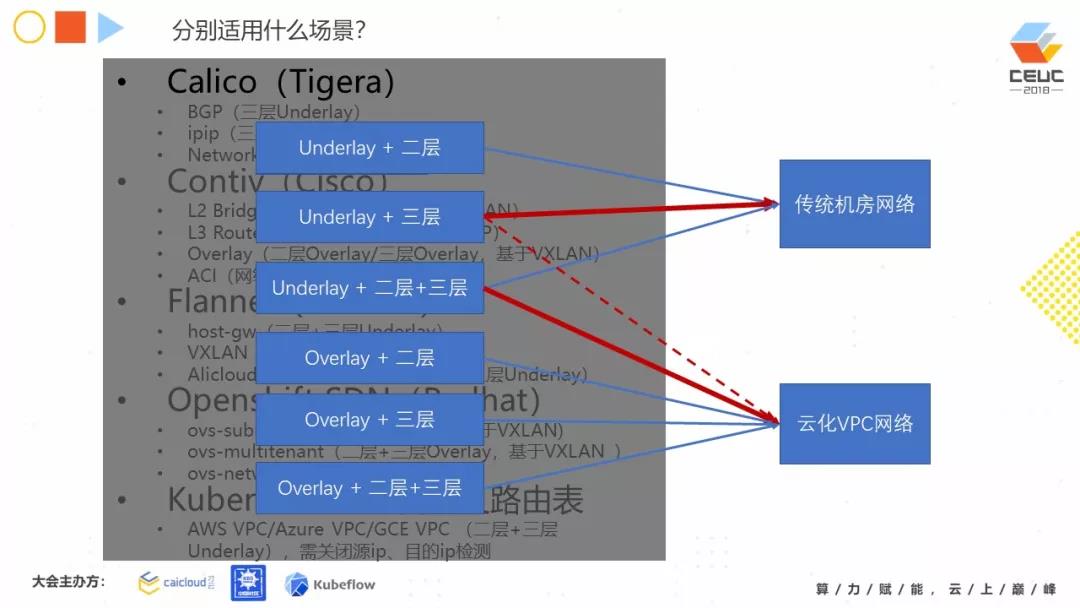
他们分别适用什么场景?我们简单地把现在部署的容器网络场景分为两大类:传统机房网、云化 VPC 网络。无论是传统机房网 ,还是云化 VPC 网络。我们可以看到 Overlay 方案是通用的,它在云化场景里可能用的更多一些,因为它有很好的穿越性。
在上图红线实线指向,需要重点说明。Underlay + 三层的方案,是传统机房网络非常流行的方案,同时它的性能非常可观,这个在我们的客户场景应用比较偏多。Underlay + 二层 + 三层的方案,在云化 VPC 场景(特别是公有云)也是比较主流的一个方案,借助 VPC 的自定义路由完成转发。
红色虚线指向,Underlay + 三层网络在云化 VPC 场景下,也是可以受限使用。受限使用顾名思义,可以使用但不是每个供应商都让你用,因为每一个云厂商对他自己网络保护的定义不一样。比如像 Calico 方案,它的 BGP 在 AWS 中就容易做,但在 Azure 中就不允许,因为 Azure 的 VPC 本身是不允许不受它管控范围的 IP 通过。
在云化 VPC 场景下存在哪些问题
在云化的 VPC 情况下,目前我们能看到这些网络方案都存在一些问题。
第一个问题:不关你是哪一种方案,你都需要管理两套网络策略,一套是 VPC 层的安全组等;另一套是 Kubernetes 的 network policy。如此,你的管理成本是比较偏高的。
第二个问题:在 BGP 场景下,BGP Underlay 即使能使用但它是无法跨越多 AZ。如今,公有云厂商中跨越 AZ 一般意味着跨子网,跨子网就意味着跨越路由,但是很可惜 VPC 的 vRouter 一般不支持 BGP。BGP Underlay 可以用,但也仅限于单 AZ。
在 VPC 自定义路由的场景下(非常主流的一种网络使用方式),存在什么问题呢?第一,节点规模受限于路由表数量,一般的厂商都会在 100 以下, AWS 支持 50 条,阿里云默认 48 条。第二,多次网络跳转,性能略有下降,你在节点层要跳一次,在 VPC 里也要跳一次 ,使之性能有所影响。
之前我们说到 Overlay 场景很通用,但同时又存在两层 Overlay 开销问题 。IaaS 层一般有一层,容器层有一层,性能下降是非常明显的。对于这种 PPS 敏感型业务,很明显是不能接受的,怎么办呢?所以我们看到,基于 VPC 深度集成的容器网络。
基于 VPC 深度集成的容器网络
目前很多厂商也有类似的方案,比如说 AWS EKS 的 VPC CNI 插件,Azure AKS 的 VNET CNI 插件,阿里云现在公测的 Terway。基于 VPC 这种深度集成的容器网络,把 VPC 的能力上移到容器网络这一层,用 VPC 的能力去做转发与控制。
基于 VPC 深度集成的 Kubernetes 网络实践
接下来,为大家讲解网易云如何基于 VPC 深度集成 Kubernetes 网络。首先,这里有很多方案,在这里我将它们都列出来。
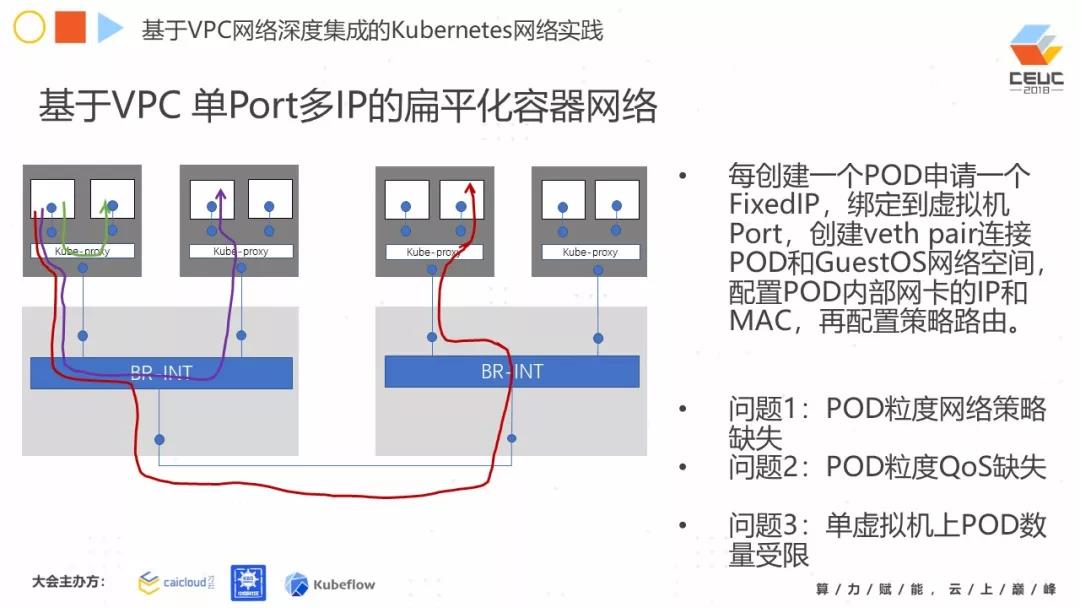
第一个方案,我们叫基于 VPC 单 Port 多 IP 的扁平化容器网络。如图所示:下面是物理机,上面大框是虚机,里面白色的小框是 Pod。第一种方式,每一台虚拟机,在申请完都会有一个虚拟网卡。
现在设计多个容器,多个 Pod 要怎么办呢?每申请一个 Pod,在下层的 VPC 申请一个 VPC IP,绑到这个虚拟机的端口上,然后通过 veth pair(就是容器的空间和 GuestOS 的空间连起来),把 Pod 里的 IP 配置上,再配置策略路由,就有一个在节点内部的转发。
节点外部如何转发?通过 VPC 的端口弄出来。但是这种方式存在什么问题?第一个问题,Pod 粒度网络策略缺失。为什么会出现此种问题?因为你从底层只申请一个端口。网络策略一般在 VPC,都在端口级别。
Pod 内部的网络策略是需要自己做,需要跑两套网络策略。第二个问题,QoS 同样如此。就是你端口粒度的 Port, QoS 需要自己做。第三个问题,单虚拟机上 Pod 数量有限制。这是因为 VPC 对于这个端口的 IP 数量有限制,也是就是 Pod 数量有限制。
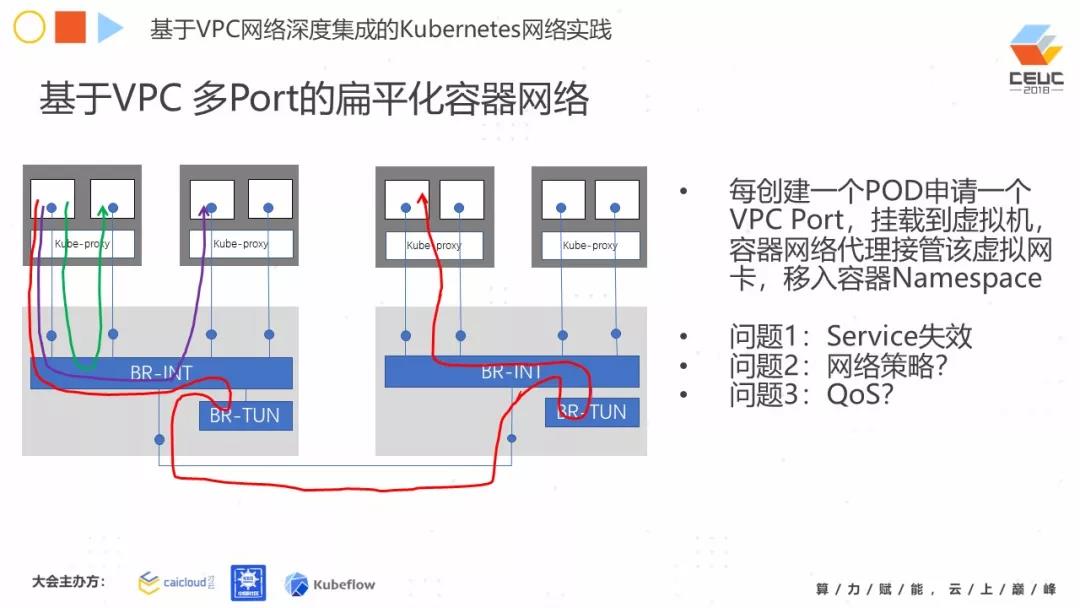
第二个方案,基于 VPC 多 Port 方案的扁平化容器网络,大家比较容易理解,简单来说就是每创建一个 Pod,你申请一个端口,就可以直接把这个虚拟网卡移到 Pod 虚拟空间里。但是存在什么问题呢?
如果我直接移上去之后,绕开这个节点的 Kubernetes-Proxy,报文一旦不经过它,原有的 Pod 的能力,比如 Sevice 的转发解析怎么办?这个就会失效。这个问题应该如何解决?另一个问题,原有的一些网络方案的网络策略,QoS 也可能会失效,因为报文没有经过 host 协议栈,任何方案都没有用。
我们的解决方案
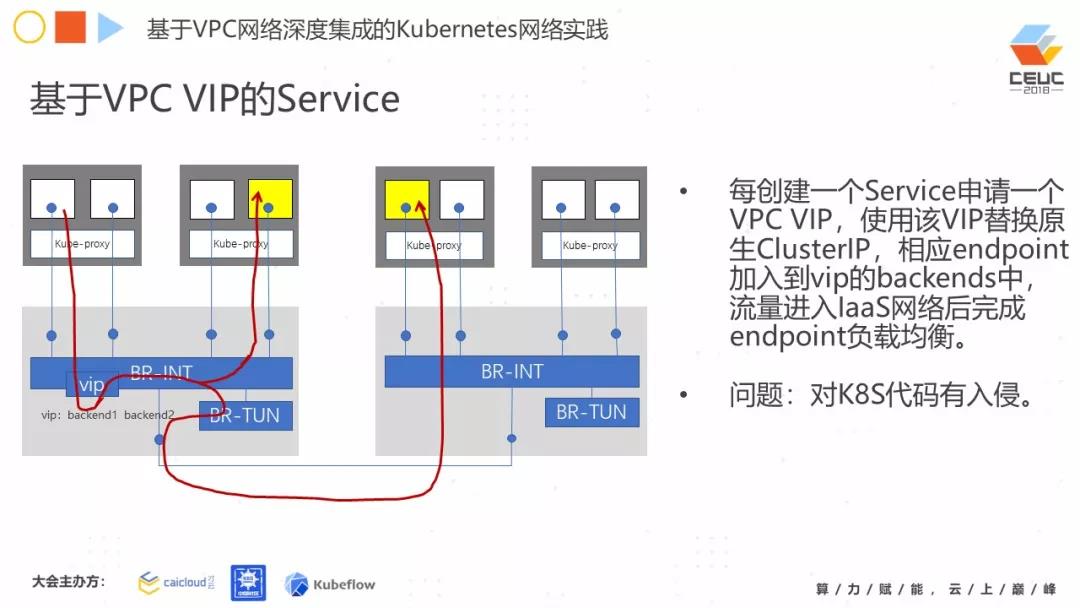
第一种方案:基于 VPC VIP 的 Service。利用 VPC VIP,每创建一个 Sevice,就同时申请一个 VPC VIP。然后用这个 VIP 把原来的 CluserIP 换掉,再把 endpoint 加到 VIP 的后端。当流量进到二层后,它就会进入到 VIP 中,然后进行转发。但是这里有一个问题,目前的 Kubernetes ClusterIP 是在 API Server 里做的。在这个方案中,比较糟糕的是在设计时需要修改这一块的代码。
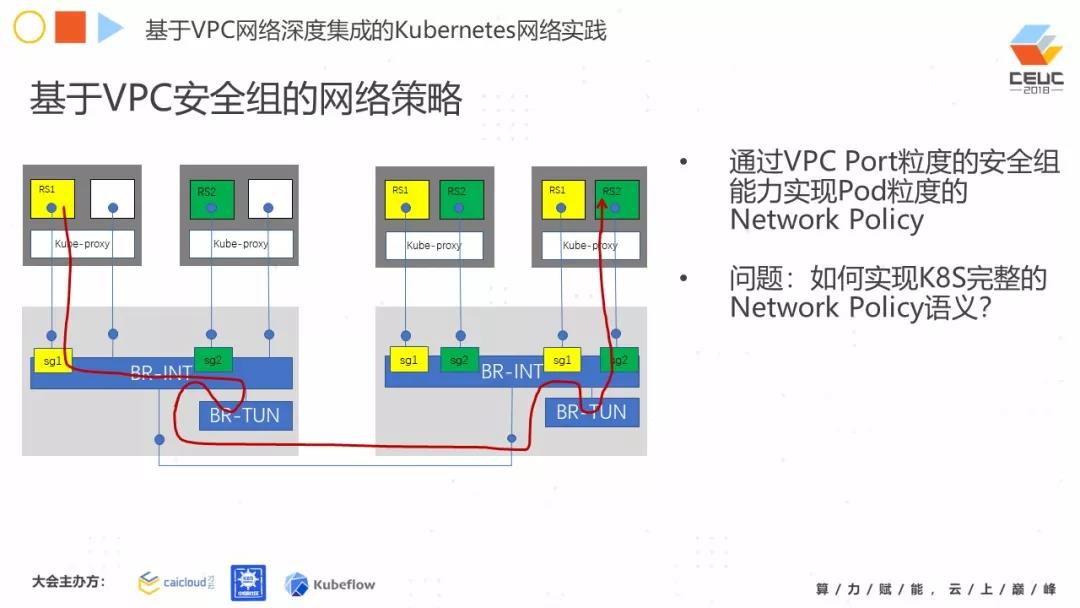
第二种方案:通过 VPC 的端口安全组,实现 Pod 粒度的网络策略。比如,两个 APP 互相之间要有通讯,我就可以在 Pod 的端口上做文章,把这个 Policy 实现。但是有个问题 ,你需要完成对 Kubernetes 整个网络策略进行语义转换。在 Kubernetes 的网络策略中,同一个 Namespace 里面的哪些 Pod 能够访问哪些 Pod 的哪些端口,哪些 Namespace 能够访问哪些 Pod 的哪些端口,那么你必须完成这种语义转换。
第三种方案:基于 VPC Port 的 QoS 保证。那么你可以在 VPC 的 Port 上,去完成这个 QoS 在每一个 Pod 的类似保证,但是还是一样有问题,就是你怎么去跟这个 IaaS 的整个原始 QoS 设计去协同。
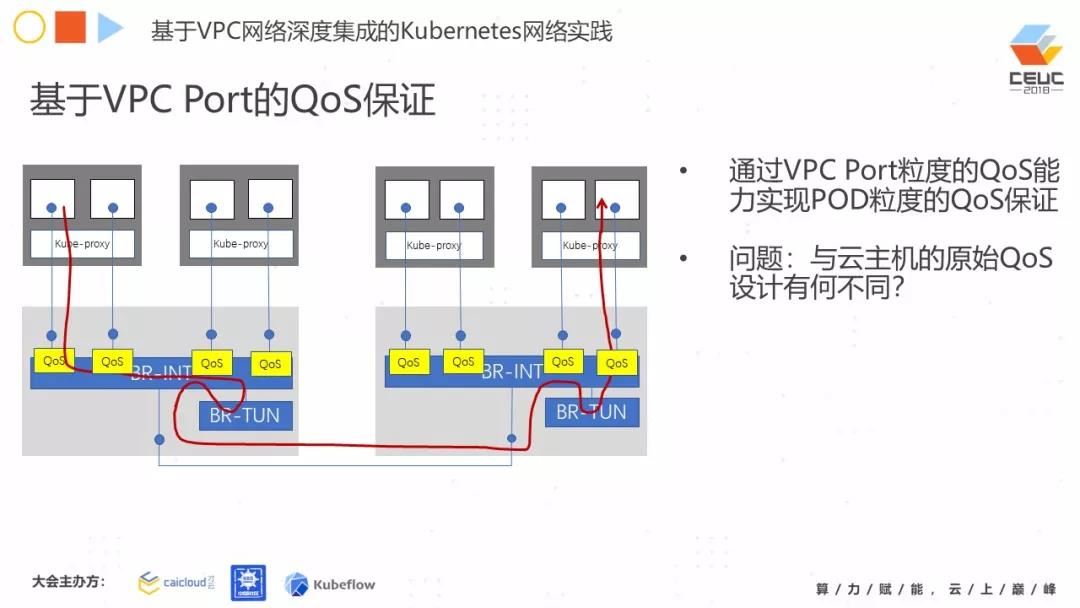
我们知道,在这个公有云或私有云的主机上(Hypervisor),一般来讲它的网络能力一般是主流的 10G 网卡,也就是说整个主机上的所有流量,不管是虚机负载还是虚机里面的 Pod 负载,进出都是 10G。
一般来讲,他们对云主机都会做限速,虚机默认就是有 1Gbs 流量的限速。如今到了这个容器级别,你的虚机里面就会跑很多个容器,那你的量级会产生变化。而且以前你在一个 Pod 级别做了一个 QoS,那我们是不是要考虑虚拟机的能力?
你要考虑整个 Kubernetes 的设计,所以它其实是有一个很强的 QoS 的设计层级在里面的。那但是这个具体的细节,因为时间的关系不再进行讲解,下次再与大家分享。
结语
此次主要为同学们介绍常见的容器网络方案分类、主流的容器网络方案和其适用的场景,重点论述 VPC 场景下不同方案存在的问题;最后为同学们介绍网易云在 VPC 场景下深度集成的容器网络方案的一些设计和实践。后续有机会再为各位同学详细介绍,我们在高性能数据面方面的一些想法和设计。
网易云计算基础服务深度整合了 IaaS、PaaS 及容器技术,提供弹性计算、DevOps 工具链及微服务基础设施等服务,帮助企业解决 IT、架构及运维等问题,使企业更聚焦于业务,是新一代的云计算平台,点击可免费试用。
相关文章:
【推荐】 云架构师进阶攻略(1)
以上是关于Kubernetes网络方案的三大类别和六个场景的主要内容,如果未能解决你的问题,请参考以下文章