面向容器日志的技术实践
Posted yunqishequ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面向容器日志的技术实践相关的知识,希望对你有一定的参考价值。
背景
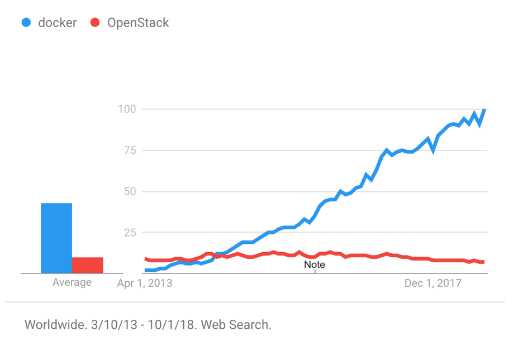
自 2013 年 dotCloud 公司开源 Docker 以来,以 Docker 为代表的容器产品凭借着隔离性好、可移植性高、资源占用少、启动迅速等特性迅速风靡世界。下图展示了 2013 年以来 Docker 和 OpenStack 的搜索趋势。
容器技术在部署、交付等环节给人们带来了很多便捷,但在日志处理领域却带来了许多新的挑战,包括:
- 如果把日志保存在容器内部,它会随着容器的销毁而被删除。由于容器的生命周期相对虚拟机大大缩短,创建销毁属于常态,因此需要一种方式持久化的保存日志;
- 进入容器时代后,需要管理的目标对象远多于虚拟机或物理机,登录到目标容器排查问题会变得更加复杂且不经济;
- 容器的出现让微服务更容易落地,它在给我们的系统带来松耦合的同时引入了更多的组件。因此我们需要一种技术,它既能帮助我们全局性的了解系统运行情况,又能迅速定位问题现场、还原上下文。
日志处理流程
本文以 Docker 为例,依托阿里云日志服务团队在日志领域深耕多年积累下的丰富经验,介绍容器日志处理的一般方法和最佳实践,包括:
- 容器日志实时采集;
- 查询分析和可视化;
- 日志上下文分析;
- LiveTail - 云上 tail -f。
容器日志实时采集
容器日志分类
采集日志首先要弄清日志存在的位置,这里以 nginx、Tomcat 这两个常用容器为例进行分析。
Nginx 产生的日志包括 access.log 和 error.log,根据 nginx Dockerfile 可知 access.log 和 error.log 被分别重定向到了 STDOUT 和 STDERR 上。
Tomcat 产生的日志比较多,包括 catalina.log、access.log、manager.log、host-manager.log 等,tomcat Dockerfile 并没有将这些日志重定向到标准输出,它们存在于容器内部。
容器产生的日志大部分都可以归结于上述情形。这里,我们不妨将容器日志分成以下两类。
| 容器日志分类 | 定义 |
|---|---|
| 标准输出 | 通过 STDOUT、STDERR 输出的信息,包括被重定向到标准输出的文本文件。 |
| 文本日志 | 存在于容器内部并且没有被重定向到标准输出的日志。 |
标准输出
使用 logging driver
容器的标准输出会由 logging driver 统一处理。如下图所示,不同的 logging driver 会将标准输出写往不同的目的地。
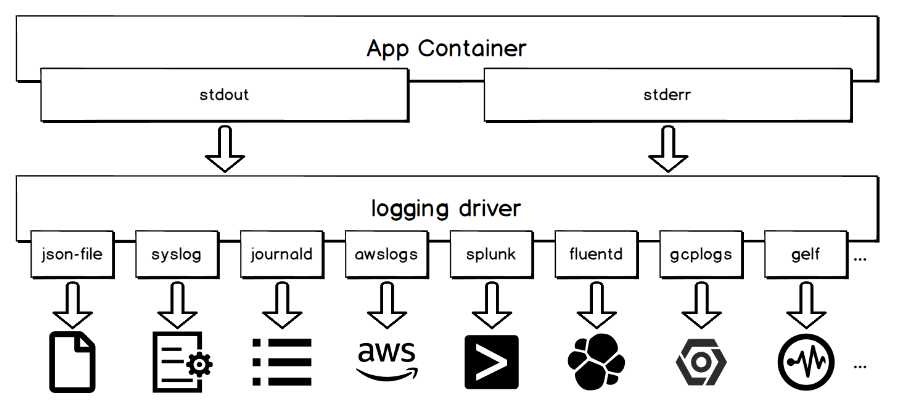
通过 logging driver 采集容器标准输出的优势在于使用简单,例如:
# 该命令表示在 docker daemon 级别为所有容器配置 syslog 日志驱动
dockerd -–log-driver syslog –-log-opt syslog-address=udp://1.2.3.4:1111
# 该命令表示为当前容器配置 syslog 日志驱动
docker run -–log-driver syslog –-log-opt syslog-address=udp://1.2.3.4:1111 alpine echo hello world缺点
除了 json-file 和 journald,使用其他 logging driver 将使 docker logs API 不可用。
例如,当您使用 portainer 管理宿主机上的容器,并且使用了上述两者之外的 logging driver,您会发现无法通过 UI 界面观察到容器的标准输出。
使用 docker logs API
对于那些使用默认 logging driver 的容器,我们可以通过向 docker daemon 发送 docker logs 命令来获取容器的标准输出。使用此方式采集日志的工具包括 logspout、sematext-agent-docker 等。下列样例中的命令表示获取容器自2018-01-01T15:00:00以来最新的5条日志。
docker logs --since "2018-01-01T15:00:00" --tail 5 <container-id>缺点
当日志量较大时,这种方式会对 docker daemon 造成较大压力,导致 docker daemon 无法及时响应创建容器、销毁容器等命令。
采集 json-file 文件
默认 logging driver 会将日志以 json 的格式写入宿主机文件里,文件路径为/var/lib/docker/containers/<container-id>/<container-id>-json.log。这样可以通过直接采集宿主机文件来达到采集容器标准输出的目的。
该方案较为推荐,因为它既不会使 docker logs API 变得不可用,又不会影响 docker daemon,并且现在许多工具原生支持采集宿主机文件,如 filebeat、logtail 等。
文本日志
挂载宿主机目录
采集容器内文本日志最简单的方法是在启动容器时通过 bind mounts 或 volumes 方式将宿主机目录挂载到容器日志所在目录上,如下图所示。
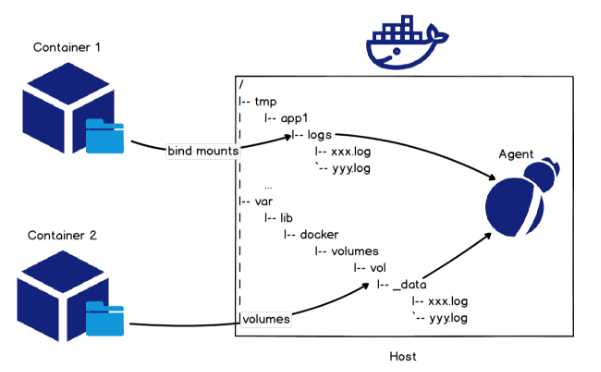
针对 tomcat 容器的 access log,使用命令docker run -it -v /tmp/app/vol1:/usr/local/tomcat/logs tomcat将宿主机目录/tmp/app/vol1挂载到 access log 在容器中的目录/usr/local/tomcat/logs上,通过采集宿主机目录/tmp/app/vol1下日志达到采集 tomcat access log 的目的。
计算容器 rootfs 挂载点
使用挂载宿主机目录的方式采集日志对应用会有一定的侵入性,因为它要求容器启动的时候包含挂载命令。如果采集过程能对用户透明那就太棒了。事实上,可以通过计算容器 rootfs 挂载点来达到这种目的。
和容器 rootfs 挂载点密不可分的一个概念是 storage driver。实际使用过程中,用户往往会根据 linux 版本、文件系统类型、容器读写情况等因素选择合适的 storage driver。不同 storage driver 下,容器的 rootfs 挂载点遵循一定规律,因此我们可以根据 storage driver 的类型推断出容器的 rootfs 挂载点,进而采集容器内部日志。下表展示了部分 storage dirver 的 rootfs 挂载点及其计算方法。
| Storage driver | rootfs 挂载点 | 计算方法 |
|---|---|---|
| aufs | /var/lib/docker/aufs/mnt/<id> | id 可以从如下文件读到。/var/lib/docker/image/aufs/layerdb/mounts/<container-id>/mount-id |
| overlay | /var/lib/docker/overlay/<id>/merged | 完整路径可以通过如下命令得到。docker inspect -f ‘{{.GraphDriver.Data.MergedDir}}‘ <container-id> |
| overlay2 | /var/lib/docker/overlay2/<id>/merged | 完整路径可以通过如下命令得到。docker inspect -f ‘{{.GraphDriver.Data.MergedDir}}‘ <container-id> |
| devicemapper | /var/lib/docker/devicemapper/mnt/<id>/rootfs | id 可以通过如下命令得到。docker inspect -f ‘{{.GraphDriver.Data.DeviceName}}‘ <container-id> |
Logtail 方案
在充分比较了容器日志的各种采集方法,综合整理了广大用户的反馈与诉求后,日志服务团队推出了容器日志一站式解决方案。
功能特点
logtail 方案包含如下功能:
- 支持采集宿主机文件以及宿主机上容器的日志(包括标准输出和日志文件);
- 支持容器自动发现,即当您配置了采集目标后,每当有符合条件的容器被创建时,该容器上的目标日志将被自动采集;
- 支持通过 docker label 以及环境变量过滤指定容器,支持白名单、黑名单机制;
- 采集数据自动打标,即对收集上来的日志自动加上 container name、container IP、文件路径等用于标识数据源的信息;
- 支持采集 K8s 容器日志。
核心优势
- 通过 checkpoint 机制以及部署额外的监控进程保证 at-least-once 语义;
- 历经多次双十一、双十二的考验以及阿里集团内部百万级别的部署规模,稳定和性能方面非常有保障。
K8s 容器日志采集
和 K8s 生态深度集成,能非常方便地采集 K8s 容器日志是日志服务 logtail 方案的又一大特色。
采集配置管理:
- 支持通过 WEB 控制台进行采集配置管理;
- 支持通过 CRD(CustomResourceDefinition)方式进行采集配置管理(该方式更容易与 K8s 的部署、发布流程进行集成)。
采集模式:
- 支持通过 DaemonSet 模式采集 K8s 容器日志,即每个节点上运行一个采集客户端 logtail,适用于功能单一型的集群;
- 支持通过 Sidecar 模式采集 K8s 容器日志,即每个 Pod 里以容器的形式运行一个采集客户端 logtail,适用于大型、混合型、PAAS 型集群。
关于 Logtail 方案的详细说明可参考文章全面提升,阿里云Docker/Kubernetes(K8S) 日志解决方案与选型对比。
查询分析和可视化
完成日志采集工作后,下一步需要对这些日志进行查询分析和可视化。这里以 Tomcat 访问日志为例,介绍日志服务提供的强大的查询、分析、可视化功能。
快速查询
容器日志被采集时会带上 container name、container IP、目标文件路径等信息,因此在查询的时候可以通过这些信息快速定位目标容器和文件。查询功能的详细介绍可参考文档查询语法。
实时分析
日志服务实时分析功能兼容 SQL 语法且提供了 200 多种聚合函数。如果您有使用 SQL 的经验,能够很容易写出满足业务需求的分析语句。例如:
- 统计访问次数排名前 10 的 uri。
* | SELECT request_uri, COUNT(*) as c GROUP by request_uri ORDER by c DESC LIMIT 10- 统计当前15分钟的网络流量相对于前一个小时的变化情况。
* | SELECT diff[1] AS c1, diff[2] AS c2, round(diff[1] * 100.0 / diff[2] - 100.0, 2) AS c3 FROM (select compare( flow, 3600) AS diff from (select sum(body_bytes_sent) as flow from log))该语句使用同比环比函数计算不同时间段的网络流量。
可视化
为了让数据更加生动,您可以使用日志服务内置的多种图表对 SQL 计算结果进行可视化展示,并将图表组合成一个仪表盘。

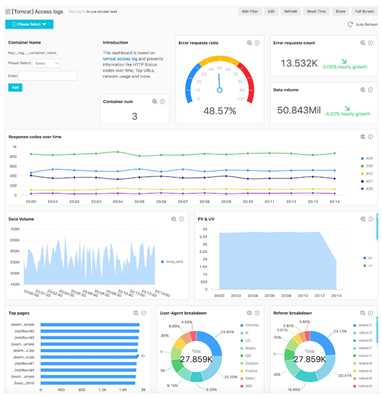
下图展示了基于 Tomcat 访问日志的仪表盘,它展示了错误请求率、网络流量、状态码随时间的变化趋势等信息。该仪表盘展现的是多个 Tomcat 容器数据聚合后的结果,您可以使用仪表盘过滤器功能,通过指定容器名查看单个容器的数据。
日志上下文分析
查询分析、仪表盘等功能能帮助我们把握全局信息、了解系统整体运行情况,但定位具体问题往往需要上下文信息的帮助。
上下文定义
上下文指的是围绕某个问题展开的线索,如日志中某个错误的前后信息。上下文包含两个要素:
- 最小区分粒度:区分上下文的最小空间划分,例如同一个线程、同一个文件等。这一点在定位问题阶段非常关键,因为它能够使得我们在调查过程中避免很多干扰。
- 保序:在最小区分粒度的前提下,信息的呈现必须是严格有序的,即使一秒内有几万次操作。
下表展示了不同数据源的最小区分粒度。
| 分类 | 最小区分粒度 |
|---|---|
| 单机文件 | IP + 文件 |
| Docker 标准输出 | Container + STDOUT/STDERR |
| Docker 文件 | Container + 文件 |
| K8s 容器标准输出 | Namespace + Pod + Container + STDOUT/STDERR |
| K8s 容器文件 | Namespace + Pod + Container + 文件 |
| SDK | 线程 |
| Log Appender | 线程 |
上下文查询面临的挑战
在日志集中式存储的背景下,采集端和服务端都很难保证日志原始的顺序:
- 在客户端层面,一台宿主机上运行着多个容器,每个容器会有多个目标文件需要采集。日志采集软件需要利用机器的多个 cpu 核心解析、预处理日志,并通过多线程并发或者单线程异步回调的方式处理网络发送的慢 IO 问题。这使得日志数据不能按照机器上的事件产生顺序依次到达服务端。
- 在服务端层面,由于水平扩展的多机负载均衡架构,使得同一客户端机器的日志会分散在多台存储节点上。在分散存储的日志基础上再恢复最初的顺序是困难的。
原理
日志服务通过给每条日志附加一些额外的信息以及服务端的关键词查询能力巧妙地解决了上述难题。原理如下图所示。
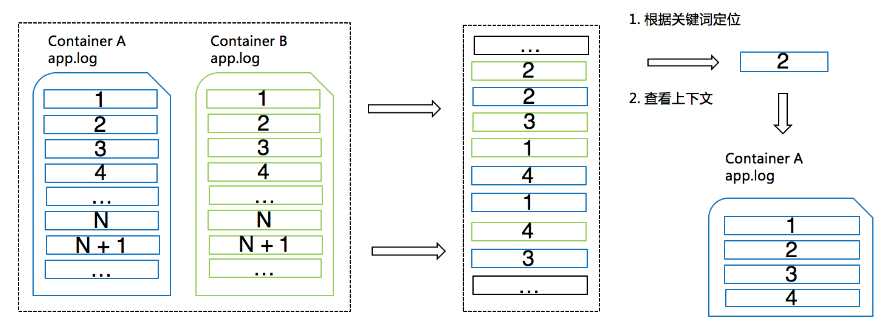
- 日志被采集时会自动加入用于标识日志来源的信息(即上文提到的最小区分粒度)作为 source_id。针对容器场景,这些信息包括容器名、文件路径等;
- 日志服务的各种采集客户端一般会选择批量上传日志,若干条日志组成一个数据包。客户端会向这些数据包里写入一个单调递增的 package_id,并且包内每条日志都拥有包内位移 offset;
- 服务端会将 source_id、package_id、offset 组合起来作为一个字段并为其建立索引。这样,即使各种日志在服务端是混合存储的状态,我们也可以根据 source_id、package_id、offset 精确定位某条日志。
想了解更多有关上下文分析的功能可参考文章上下文查询、分布式系统日志上下文查询功能。
LiveTail - 云上 tail -f
除了查看日志的上下文信息,有时我们也希望能够持续观察容器的输出。
传统方式
下表展示了传统模式下实时监控容器日志的方法。
| 类别 | 步骤 |
|---|---|
| 标准输出 | 1. 定位容器,获取容器 id; 2. 使用命令 docker logs –f <container id>或kubectl logs –f <pod name>在终端上观察输出;3. 使用 grep或grep –v过滤关键信息。 |
| 文本日志 | 1. 定位容器,获取容器 id; 2. 使用命令 docker exec或kubectl exec进入容器;3. 找到目标文件,使用命令 tail –f观察输出;4. 使用 grep或grep –v过滤关键信息。 |
痛点
通过传统方法监控容器日志存在以下痛点:
- 容器很多时,定位目标容器耗时耗力;
- 不同类型的容器日志需要使用不同的观察方法,增加使用成本;
- 关键信息查询展示不够简单直观。
功能和原理
针对这些问题,日志服务推出了 LiveTail 功能。相比传统模式,它有如下优点:
- 可以根据单条日志或日志服务的查询分析功能快速定位目标容器;
- 使用统一的方式观察不同类型的容器日志,无需进入目标容器;
- 支持通过关键词进行过滤;
- 支持设置关键列。
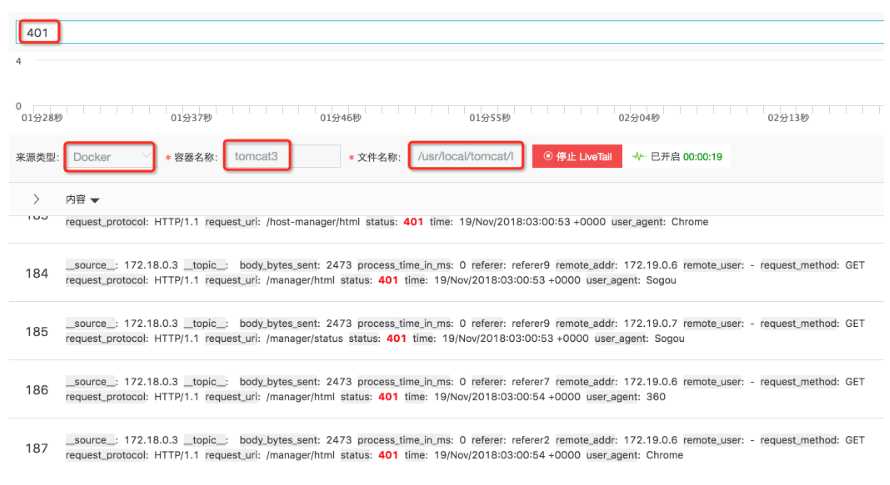
在实现上,LiveTail 主要用到了上一章中提到的上下文查询原理快速定位目标容器和目标文件。然后,客户端定期向服务端发送请求,拉取最新数据。
视频样例
您还可以通过观看视频,进一步理解容器日志的采集、查询、分析和可视化等功能。
原文链接
本文为云栖社区原创内容,未经允许不得转载。
以上是关于面向容器日志的技术实践的主要内容,如果未能解决你的问题,请参考以下文章
LC3视角:Kubernetes下日志采集存储与处理技术实践
万能日志数据收集器 Fluentd - 每天5分钟玩转 Docker 容器技术(91)