The Beam Model:Stream & Tables翻译(上)
Posted 163yun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了The Beam Model:Stream & Tables翻译(上)相关的知识,希望对你有一定的参考价值。
作者:周思华
欢迎访问网易云社区,了解更多网易技术产品运营经验。
本文尝试描述Beam模型和Stream & Table理论间的关系(前者描述于数据流模型论文、the-world-beyond-batch-streaming101和the-world-beyond-batch-streaming-102,后者被MartinKleppmann和JayKreps推广)。事实证明,Steam & Tables理论对描述Beam模型的底层基础观点具有启发性意义。此外,考虑稳健的流处理概念能被集成进SQL,清楚了解它们间的关系是特别有益的。考虑到完整性,本文首先会对上述文章(主要是Martin和Jay的帖子)进行一个简要的回顾。
1 Steam & Tables的基础知识
Steam & Tables的基本思想源于数据库。熟悉SQL的人都可能熟悉表和表的基本属性,大致概括为,表包含行和列,每行都由显式或隐式的键唯一标识。 回忆下大学数据库系统课程,可能会记得大部分数据库底层所使用到的数据结构是一个只能进行追加写的日志文件。事务应用于数据库表时,这些事务首先会记录在这个日志中,然后事务会顺序的作用于目标表来实现更新操作。在Steam & Tables概念中,上面提及的事务日志实际上就是流。从这个角度来看,我们现在可以理解如何将流转化为表:将流中的事务顺序的执行,其执行结果便成为了表。但是如何将表转化为流?本质上是逆思想:流是表的更新日志。数据库系统中的物化视图功能是一个用于说明表到流转换的不错案例。SQL中的物化视图,允许你指定表的查询语句,系统将这个查询语句视为另一张表。物化视图本质上是查询的缓存版本,当源表内容发生变化时,系统需要确保视图对应的内容最新。显而易见,物化视图是基于源表的更新日志实现,任何时刻源表发生变化都会被记录下来,然后数据库评估物化视图的查询上下文是否需要更新,并将结果更新到物化视图上,以此来保证视图的内容为最新。
结合以上两点,进行归纳总结,我们可以得出一个Steam & Tables的相对理论:
流→表:随着时间,在流上不断运用聚合操作,其结果便是表。
表→流:随着时间,观测到的表上的变更操作序列便是流。
这是一对非常强大的概念,它们能被正确的应用到了流处理中是ApacheKafka取得巨大成功的一个重要原因,其生态系统就是围绕这些基本原则构建而成。然而,这些理论本身没有足够泛化到可以将Steam & Tables与Beam模型中所有概念相结合。为此,我们必须更深入一点。
1.1 关于Steam & Tables的通用理论
如果想将Steam & Tables理论和我们所知道的Beam模型相结合,需要把一些零散的知识结合起来,特别是:
批处理是如何适应Steam & Tables这些理论的?流与有界和无界数据集的关系是什么?
如何将What、Where、When和How四个问题映射到Steam&Tables中
在此之前,我们首先需要对面临的问题有个清晰的认知。除了通过上述定义来理解Steam & Tables间的关系外,独立定义它们的含义也很有必要。先从简单的角度看下Steam & Tables的定义,这对我们未来的一些分析很有帮助,它们如下:
表:静态的数据
这并不是说表的内容是不变的。几乎所有实时表的内容都会以一些方式随时间不断变化。但在给定时刻,表的快照提供了数据库整体数据中的一部分数据视图。通过这种方式,表提供了一个供数据停下来缓存的静态场所:随着时间推移,在这里数据可以被累积计算、并且可以被观测。
流:动态的数据
表捕获的是某一特定时间点的数据视图,而流捕获的是数据随时间的变化发展。JulianHyde喜欢说流像表的求导结果,表像流的积分结果,这种使用数学思维来理解是不错的方式。
虽然流与表密切相关,即使在许多案例中,一方来源完全借鉴于另一方,但一定要记住,它们之间是存在区别的。虽然区别是微妙的,但也是重要的,我们会在下面看到。
2 批处理 vs Stream & Tables
随着讨论的深入,让我们开始总结一些零散分析。首先,我们要解决的第一个问题是关于批处理的问题。最后,我们将发现第二个关于流与有界和无界数据的关系的问题将自然而然地从第一个答案中得到解决。
2.1 从Stream & Tables的角度看MapReduce模型
为使我们分析起来更简单,首先我们可以看下Stream &Tables理论如何与传统的MapReduce任务相结合。就像它名字所表示的那样,MapReduce由两个关键的阶段组成:Map阶段和Reduce阶段,为了使得我们的分析更加清晰,这里将其拆分成6个子阶段:
1. MapRead:消费输入数据,将数据预处理成标准的K/V结构,为Map阶段准备;
2. Map: 不断的消费(可能并行)前面过程预处理的单个K/V对,输出0或者多个K/V对;
3. MapWrite: Map阶段输出的具有相同key的value在这过程会被集群聚合在一起,聚合后的数据形如(K,Iterator(V)),接着持久化这些(K, Iterator(V))数据,简单来说,MapWrite就是基本的根据key 进行聚合然后checkpoint这些结果到存储系统;
4. ReduceRead: 消费MapWrite阶段持久化的shuffle数据(K可能作为分桶的key,从而写入到不同的磁盘上),转变成标准的(K,List(value))结构为Reduce阶段做准备;
5. Reduce: 不断消费一个Key对应的多条value,输出0条或者多条记录,这些记录仍然对应这个key;
6. ReduceWrite:将Reduce阶段的结果写入数据存储介质。
虽然在很多资料中,上述的MapWrite、ReduceRead阶段会被统一称为MapReduce中的Shuffle阶段,但是出于我们的目的,这两个阶段最好单独分开看待。将MapRead和ReduceWrite分别看成是Sources与Sinks可能更好理解。除此之外,我们现在看看它们与Stream &Tables理论又存在哪些关系?
2.2 从Stream & Tables的角度看Map过程
有一点需要说明一下,由于在map阶段中,它的输入、输出都是表的形式,有些人可能会自然而然的认为,map过程中涉及到的都是只有表而已。毕竟对于批处理任务来说,大家都知道它是以表作为输入,然后再输出结果表。如果把整个批处理过程看出是执行一段SQL语句的话,可能更好理解一些。但是map过程与表之间的关系到底是什么呢?难道它就真的只与表有关,与流就一点关系也没有吗?下面让我们一步步深入的进行说明?
首先,MapRead消费一张表,然后产生结果数据,这些结果数据又被下一步Map阶段作为输入数据,想要理解的更透彻些,可以看下Map阶段的API,JAVA接口如下:
voidmap(KI key, VI value, Emit);
每消费一条input表中的k/v对,都将调用一次map方法,如果你发现这里输入表的记录数据像流一样被处理,那么恭喜你,你是对的。稍后我们将更进一步的去看表是如何转化为流,但是现在,我们已经了解到MapRead阶段会迭代消费输入表中的数据,同时使这些数据以流的形式供Map阶段消费。
下一步,Map阶段消费流,然后干什么呢?由于map执行的是对一个元素的转化操作,因此它不会做任何阻止数据流动的事情,通过过滤一些元素或者拆分一些元素成为多个元素,它可以有效改变流中的数据,但是map阶段结束以后,这些元素彼此相互独立。因此可以说,map阶段消费流同时产出流。
一旦map阶段结束以后,就进入了MapWrite阶段,我上面提到,MapWrite根据key聚合记录,然后以这种数据结构持久化到存储介质中。这里存储到持久化存储其实不是严格必须的,也可以存储到其他地方(假如上一节点流被存储了,中间结果再失败的时候就可以通过重新计算上个节点得到,类似spark的的RDD方法),最重要的是在这一步中记录被聚合到了一起,并被存储在存储介质上,可能是内存、磁盘、其他能够存储的介质。这个重要的原因是,聚合操作导致的结果是,那些先前在流中一条一条流动的数据通过key被放到同一位置,因此能够针对每个key后的分组数据进行聚合处理,注意这里是不是和前面提到定义流到表的转换很像呢?随着时间推移,更新流的聚合结果进而产生表,MapWrite以key来将流中的数据进行分组,将分组数据再写入下一级,因此将流又转化为了表。
到此为止我们已经讨论了MapReduce过程的上半部分(Map部分),来看下我们目前为止看到了什么?(在图1中)
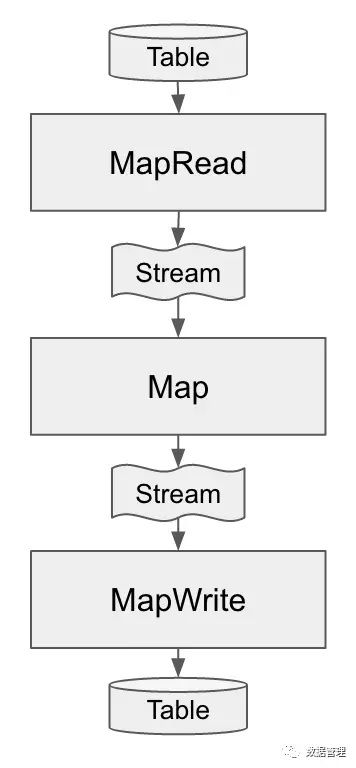
图 1: MapReduce的Map阶段,表中的数据转化为流之后又转回到表
通过三个操作完成了从表到流再到表的转换过程,MapRead将表转换成流,map阶段又将该流转变成了新流,最后这个新流经过 MapWrite又转表回到表,接下来将会发现Reduce阶段的三个操作和这三个操作很类似,尽管如此在接下来对Reduce阶段进行说明的过程中,我仍然会指出一个重要的细节出来。
3 从Stream & Tables的角度看Reduce过程
在了解了MapWrite以后,ReduceRead本身相对无趣,因为它基本上与MapRead相同,除了读取的是list形式的数据而不是单个值,因为MapWrite存储的数据是k/list(v)对。 但是,它仍然只是迭代计算一个表的快照,将其转换为流,这里没什么新鲜的。
Reduce实际上只是一个Map阶段的变形,接收每个键的值列表而不是单个值。因此,它仍然只是将单个(复合,(K,List(V)))记录映射到零个或多个新记录。ReduceWrite这里是值得注意的一个过程,我们都知道这个过程会将流转变成表,因为上面的Reduce过程产生流而最终的 ReduceWrite输出却是表。这个是如何做的?其实这个就像前面的MapWrite阶段一样,对前一个阶段的输出的流按照key进行分组,然后将结果持久化到存储介质。假如你记得我前面提到的指定key对于reduce过程是一个可选的特征,使用这个特征,ReduceWrite和MapWrite基本相同,如果reduce的输出没有指定key,那么数据到达下游以后会发生什么呢?
再回想下经典sql表的执行语义将有助于理解将会发生什么,尽管在sql表中推荐使用主键,但是sql表并不是严格需要主键来区分每行数据的,如果表中没有主键,插入到表中的每条数据都被视为新的独立的一行,尽管表中可能存在一条或者多条相同的数据,这里大部分是通过为表增加自动递增的列作为数据的key来实现的。在这些场景下这些key可能仅仅是一些物理块的位置索引,不会当做逻辑标识符去处理或者暴露出去。这个隐含的key,正是ReduceWrite中处理无Key数据情况的应对方法。 从概念上讲,这仍然是按key分组的操作,但是由于缺少用户提供的key,ReduceWrite认为每条数据都是新的,每条数据都拥有一个唯一的key,然后根据它进行分组(结果是每组仅有一条数据),最后将结果流传到下游。
现在让我们回顾下流/表的转换的整个流程,可以发现它是“表 -> 流 -> 流 -> 表 -> 流-> 流 -> 表”的序列。尽管我们处理的是有界数据,尽管我们使用的是传统的批处理思想,但其实本质仍然是流和表的转化。
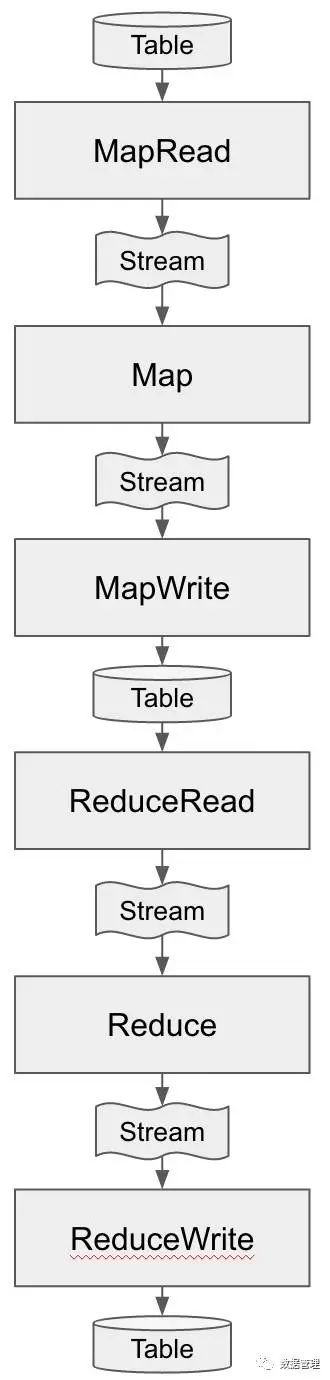
图2:从流/表的角度来看MapReduce的Map和Rdeuce
4 总 结
通过这些分析,除了前面提到的两个问题外还有哪些问题呢?
Question:批处理是如何适配到Stream & Tables理论中的?
Answer:不错的问题,基本模式是:
1. 读取全部表的数据变成了流;
2. 在分组操作之前,一个流被转化为新的流;
3. 分组将流变成了表;
4. 重复步骤1-3,直到跳出整个流程。
Question:流与有界和无界数据的有什么关联吗?
Answer:我们可以通过MapReduce例子看出,无论是对于有界还是无界的数据,流只是数据的动态形式。
通过这些分析,很容易发现Stream & Tables理论与有界数据的批处理理论差异并不大,事实上这更加支持我之前提出的批处理与流处理二者并无差异的想法,有了这些分析,我们可以很好的总结出一个通用的Stream & Tables理论,但是要把这些东西理清楚,我们最后要解决what/where/when/how这个四个问题,找出它们之间的联系。
网易有数:企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用PPT模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。可点击这里免费试用。
相关文章:
【推荐】 如何准确又通俗易懂地解释大数据及其应用价值?
【推荐】 云架构师进阶攻略(2)
【推荐】 Andorid自定义attr的各种坑
以上是关于The Beam Model:Stream & Tables翻译(上)的主要内容,如果未能解决你的问题,请参考以下文章
从 Apache Beam(GCP 数据流)写入 ConfluentCloud
HDU 5091---Beam Cannon(线段树+扫描线)