MTCNN实时人脸检测网络详解与opencv+tensorflow代码演示
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MTCNN实时人脸检测网络详解与opencv+tensorflow代码演示相关的知识,希望对你有一定的参考价值。
MTCNN模型概述
多任务卷积神经网络(MTCNN)实现人脸检测与对齐是在一个网络里实现了人脸检测与五点标定的模型,主要是通过CNN模型级联实现了多任务学习网络。整个模型分为三个阶段,第一阶段通过一个浅层的CNN网络快速产生一系列的候选窗口;第二阶段通过一个能力更强的CNN网络过滤掉绝大部分非人脸候选窗口;第三阶段通过一个能力更加强的网络找到人脸上面的五个标记点;完整的MTCNN模型级联如下: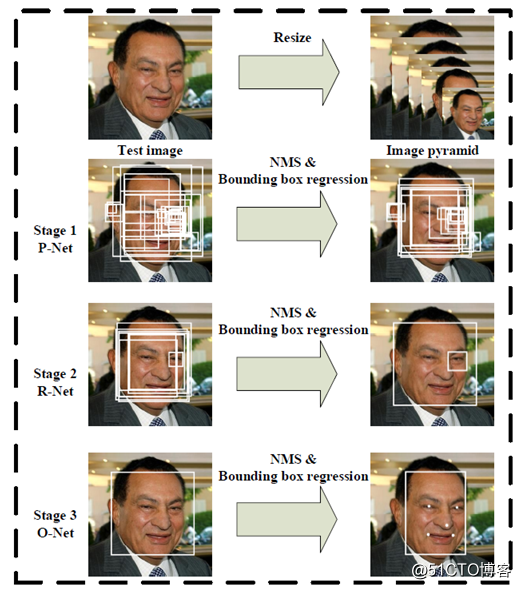
该模型的特征跟HAAR级联检测在某些程度上有一定的相通之处,都是采用了级联方式,都是在初期就拒绝了绝大多数的图像区域,有效的降低了后期CNN网络的计算量与计算时间。MTCNN模型主要贡献在于:
1.提供一种基于CNN方式的级联检测方法,基于轻量级的CNN模型就实现了人 脸检测与点位标定,而且性能实时。
2.实现了对难样本挖掘在线训练提升性能
3.一次可以完成多个任务。阶段方法详解
第一阶段
网络是全卷积神经网络是一个推荐网络简称 P-Net, 主要功能是获得脸部区域的窗口与边界Box回归,获得的脸部区域窗口会通过BB回归的结果进行校正,然后使用非最大压制(NMS)合并重叠窗口。
第二阶段
网络模型称为优化网络R-Net,大量过滤非人脸区域候选窗口,然后继续校正BB回归的结果,使用NMS进行合并。
第三阶段
网络模型称为O-Net,输入第二阶段数据进行更进一步的提取,最终输出人脸标定的5个点位置。
网络架构与训练
对CNN网络架构,论文作者发现影响网络性能的因素主要原因有两个:
1.样本的多样性缺乏会影响网络的鉴别能力
2.相比其它的多类别的分类与检测任务来说,
人脸检测是一个二分类,每一层不需要太多filters,
也就是说每层网络的feature maps个数不需要太多根据上述两个因素,作者设计网络每层的filter个数有限,但是它增加了整个网络的深度,这样做的好处是可以显著减少计算量,提升整个网络性能,同时全部改用3x3的filter更进一步降低计算量,在卷积层与全连接层使用PReLU作为非线性激活函数(输出层除外)整个网络架构如下: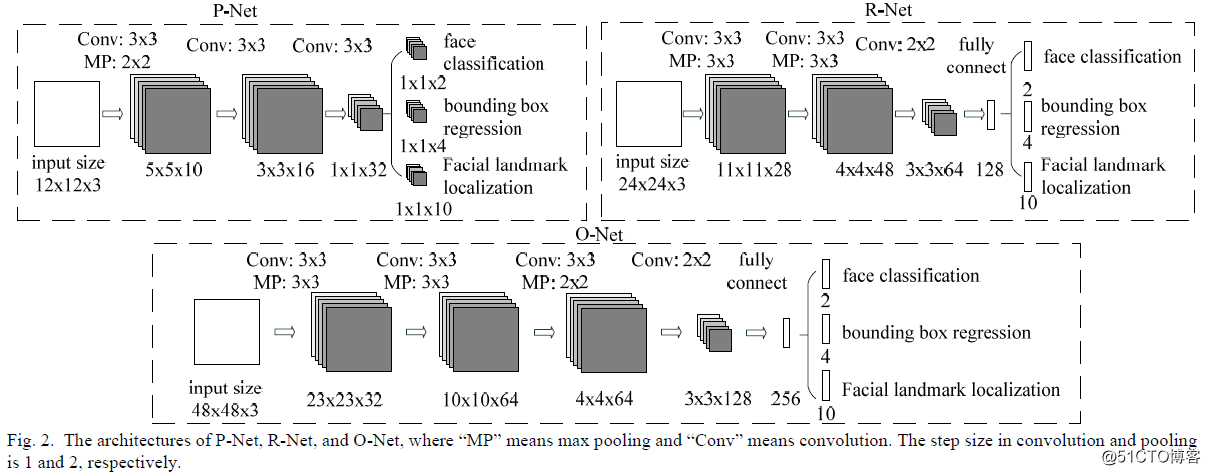
训练这个网络需要如下三任务得到收敛
1.人脸二元分类
2.BB回归(bounding box regression)
3.标记定位(Landmark localization)训练时候对于人脸采用交叉熵损失: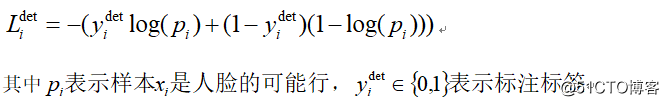
BB回归损失:
对每个候选窗口,计算它与标注框之间的offset,目标是进行位置回归,计算其平方差损失如下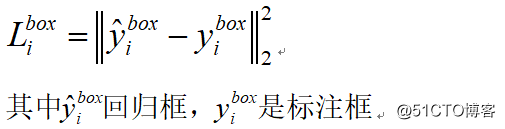
脸部landmark位置损失:
总计有五个点位坐标分别为左眼、右眼、鼻子、左嘴角、右嘴角
因为每个CNN网络完成不同的训练任务,所以在网络学习/训练阶段需要不同类型的训练数据。所以在计算损失的时候需要区别对待,对待背景区域,在R-Net与O-Net中的训练损失为0,因为它没有包含人脸区域,通过参数beta=0来表示这种类型。总的训练损失可以表示如下: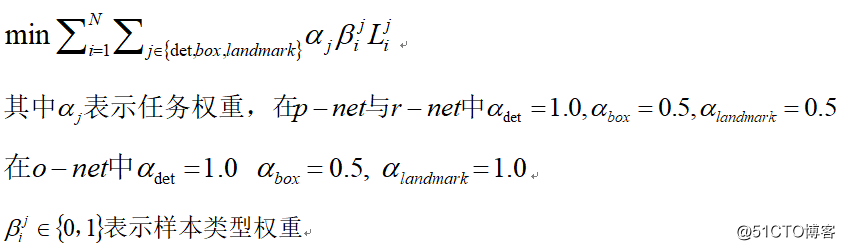
在P-Net中对人脸进行二元分类时候就可以在线进行难样本挖掘,在网络前向传播时候对每个样本计算得到的损失进行排序(从高到低)然后选择70%进行反向传播,原因在于好的样本对网络的性能提升有限,只有那些难样本才能更加有效训练,进行反向传播之后才会更好的提升整个网络的人脸检测准确率。作者的对比实验数据表明这样做可以有效提升准确率。在训练阶段数据被分为四种类型:
负样本:并交比小于0.3
正样本:并交比大于0.65
部分脸:并交比在0.4~0.65之间
Landmark脸:能够找到五个landmark位置的其中在负样本与部分脸之间并没有明显的差异鸿沟,作者选择0.3与0.4作为区间。
正负样本被用来实现人脸分类任务训练
正样本与部分脸样本训练BB回归
Landmark脸用来训练人脸五个点位置定位
整个训练数的比例如下:
负样本:正样本:部分脸:landmark脸=3:1:1:2
测试代码
加载网络
print(‘Creating networks and loading parameters‘)
with tf.Graph().as_default():
gpu_options = tf.GPUOptions(per_process_gpu_memory_fraction=gpu_memory_fraction)
sess = tf.Session(config=tf.ConfigProto(gpu_options=gpu_options, log_device_placement=False))
with sess.as_default():
pnet, rnet, onet = align.detect_face.create_mtcnn(sess, None)人脸检测
def detection(image):
minsize = 20 # minimum size of face
threshold = [0.6, 0.7, 0.7] # three steps‘s threshold
factor = 0.709 # scale factor
# detect with RGB image
h, w = image.shape[:2]
bounding_boxes, _ = align.detect_face.detect_face(image, minsize, pnet, rnet, onet, threshold, factor)
if len(bounding_boxes) < 1:
print("can‘t detect face in the frame")
return None
print("num %d faces detected"% len(bounding_boxes))
bgr = cv.cvtColor(image, cv.COLOR_RGB2BGR)
for i in range(len(bounding_boxes)):
det = np.squeeze(bounding_boxes[i, 0:4])
bb = np.zeros(4, dtype=np.int32)
# x1, y1, x2, y2
bb[0] = np.maximum(det[0] - margin / 2, 0)
bb[1] = np.maximum(det[1] - margin / 2, 0)
bb[2] = np.minimum(det[2] + margin / 2, w)
bb[3] = np.minimum(det[3] + margin / 2, h)
cv.rectangle(bgr, (bb[0], bb[1]), (bb[2], bb[3]), (0, 0, 255), 2, 8, 0)
cv.imshow("detected faces", bgr)
return bgr实时摄像头检测
capture = cv.VideoCapture(0)
height = capture.get(cv.CAP_PROP_FRAME_HEIGHT)
width = capture.get(cv.CAP_PROP_FRAME_WIDTH)
out = cv.VideoWriter("D:/mtcnn_demo.mp4", cv.VideoWriter_fourcc(‘D‘, ‘I‘, ‘V‘, ‘X‘), 15,
(np.int(width), np.int(height)), True)
while True:
ret, frame = capture.read()
if ret is True:
frame = cv.flip(frame, 1)
cv.imshow("frame", frame)
rgb = cv.cvtColor(frame, cv.COLOR_BGR2RGB)
result = detection(rgb)
out.write(result)
c = cv.waitKey(10)
if c == 27:
break
else:
break
cv.destroyAllWindows()运行演示:
本来想上传视频的发现上传不了了,所以就把视频写成多张连续的图像,截屏显示各种效果,其实视频十分流畅,效果也非常的好。
有遮挡、部分脸检测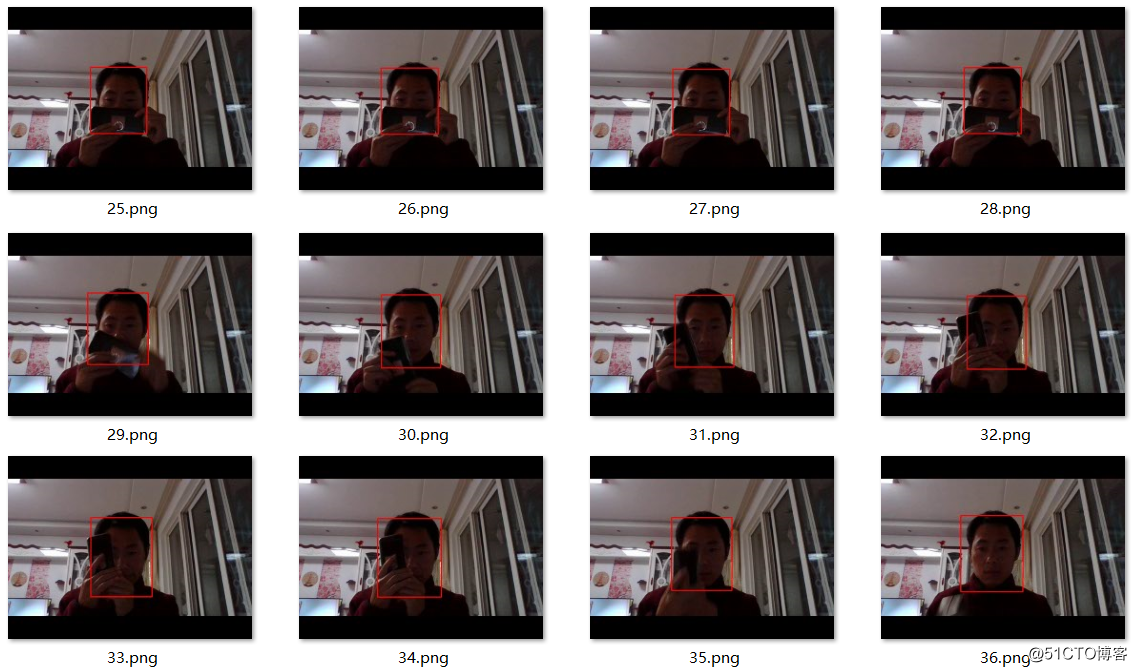
侧脸检测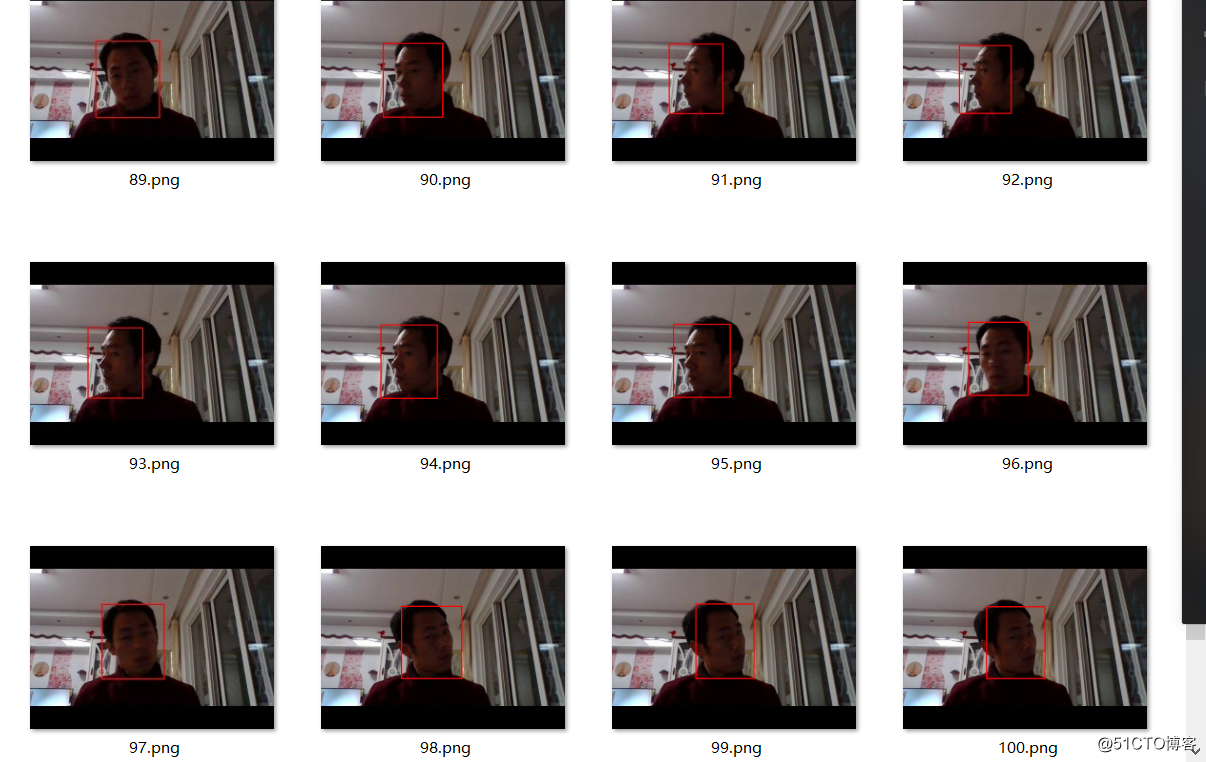
角度俯仰脸检测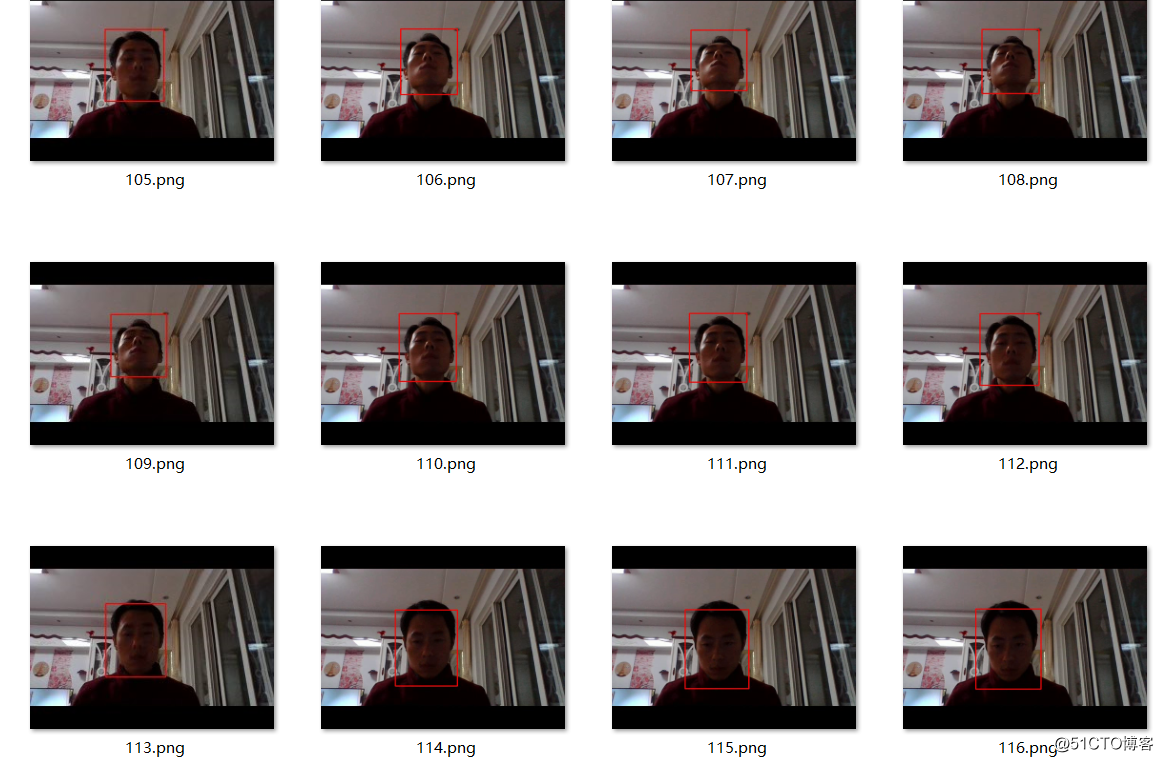
总结一下
整个模型的运行速度极快,即使在CPU上也可以完全达到实时性能,关键是其检测准确率与稳定性跟HAAR/LBP的方式相比,你就会感觉HAAR/LBP的方式就是渣,完全凉啦!
视频学习OpenCV与tensorflow开发技术
OpenCV C++ 系统化课程
以上是关于MTCNN实时人脸检测网络详解与opencv+tensorflow代码演示的主要内容,如果未能解决你的问题,请参考以下文章