爬虫从入门到放弃——爬虫的基本原理
Posted heshen175
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫从入门到放弃——爬虫的基本原理相关的知识,希望对你有一定的参考价值。
爬虫的基本原理:https://www.cnblogs.com/zhaof/p/6898138.html
这个文章写的非常好,把爬虫 的基本思路解释的很清楚的。
一、介绍工具(用什么爬)
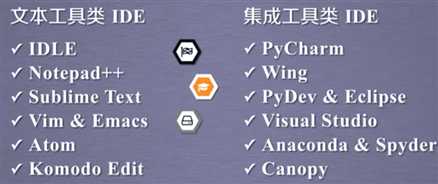
1、Python IDLE就是用了创建、运行、测试和调试python的工具。
集成开发环境:用于程序开发环境的应用程序,一般包括代码编辑器、编译器、调试器和图形用户界面工具。就是集成了代码编写功能、分析功能、编译功能、debug功能等一体化的开发软件套。
后面我学习python,老师教的用得这几个工具,后面会一 一介绍。

文本类:
IDLE:是Python 自带、默认、常用、入门级的Python编辑工具。对于入门、要求功能简单,代码不超过300行的同学,这玩意儿就很实用。
sublime text :专门为程序员开发第三方专用程序员工具。编写体验好,专业程序员喜欢。
集成类工具
wing :收费、调试丰富、版本同步,适合多人共同开发。
visual studio &PTVS :微软提供、调试丰富。
Eclipse pydev :开源IDLE开发工具,要有一定的开发经验。
PyCharm:简单、集成度高,适合复杂项目。
abaconda:开源免费、支持800个第三方库。
2、爬取数据用到的工具
requests:用来爬取HTML。页面、自动提交请求的。(模拟人的动作)
robots 协议:网络爬虫协议,去爬取东西时要遵循的规矩。
beautiful soup :把爬取回来的东西解析了
正则表达式:用来提取已经解析好的,你要的东西。
3、一系列的安装
安装requests库(前提要有pip),百度里面有很多安装教程。
二、requests库的介绍
requests库的7个主要方法 ,网络安全限制,更多用得用得是GET方法。

request基础方法,其他方法在其中分装。

get方法

mthod请求方式有7种,就是HTTP协议里面的7种方法,再加上OPTIONS方法,OPTIONS方法是向服务器获取参数。
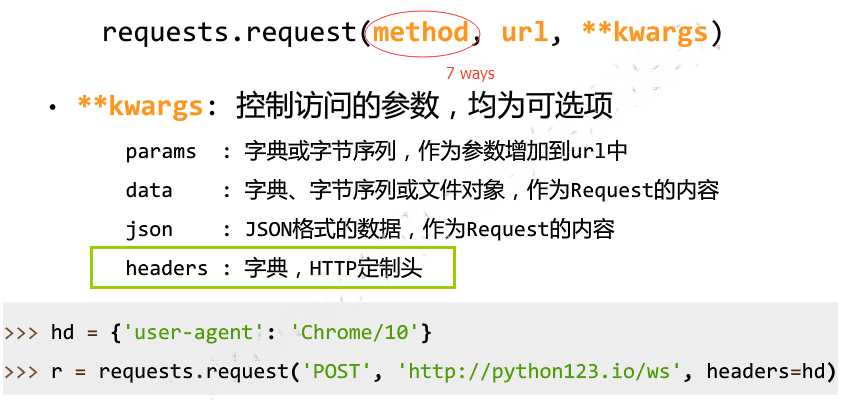
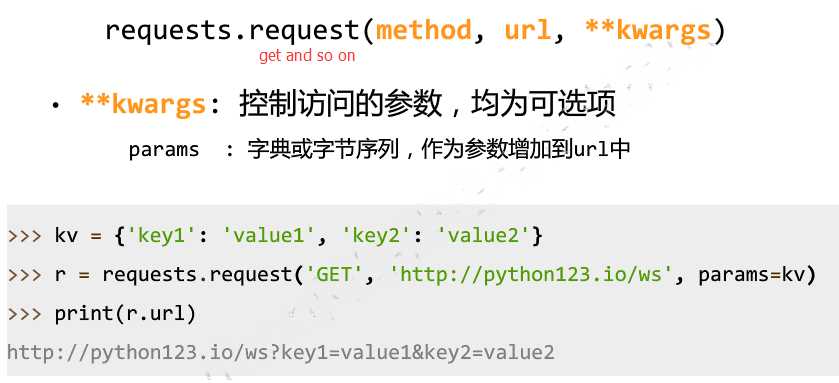
**Kwargs


requests库异常
response 对象属性

# GET 全部信息 # HEADER 仅头部信息 # Put 全部重置 # Patch 局部更新 ## 更改操作用户 # POST 后面添加新内容 ## 搜索使用 # DELETE 删除全部 import requests ‘‘‘ r = requests.get("http://www.baidu.com") # 获得全部文本信息 uRL对应的页面内容 print(r.headers) # 头部信息 print(r.text) # seem is also all information ‘‘‘ # requests.head ‘‘‘ r2 = requests.head("http://www.baidu.com") # just head information print(r.headers) # head information print(r2.text) # no ! because just get the head information ‘‘‘ # payload = {"key1":"value1","key2":"value2"} r3 = requests.post("http://www.baidu.com",data=payload) print(r3.text)
--------------------------------------------------------------------------------------------------------------------------------------------------- 分割线
三、HTTP协议
我们去爬URL,就得知道URL遵循HTTP协议,
http 协议对资源的操作,http协议和requests库方法一一对应。


四、robots协议
爬虫需要遵循的规则,告知你那些能爬,那些不能爬。


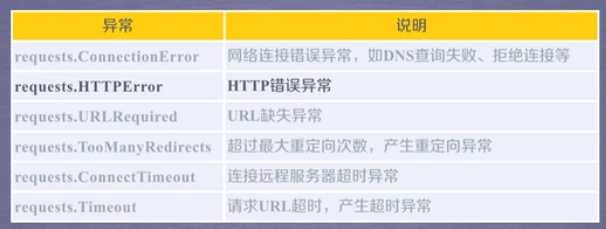
‘‘‘ import requests r = requests.get(‘https://item.jd.com/13115733485.html‘) print(r.status_code) print(r.encoding) print(r.text) ‘‘‘ ‘‘‘ import requests url = ‘https://item.jd.com/13115733485.html‘ try: r = requests.get(url, timeout=30) r.raise_for_status() r.encoding = r.apparent_encoding print(r.text[:1000]) #显示前1000的字符 except: print("404") ‘‘‘ import requests def getHTMLText(url): try: r = requests.get(url,timeout = 30) r.raise_for_status() # 如果状态是200,引发异常 r.encoding = r.apparent_encoding return r.text except: return "404" if __name__ == "__main__": #证明小明是自己,不用在执行该代码了 url = "https://item.jd.com/13115733485.html" print(getHTMLText(url)[:1000])
五、response 库 用来获取网站信息
import requests r = requests.get("http://www.baidu.com") print(r.status_code) # HTTP请求的返回状态,200表示连接成功。404表示失败 print(r.text) # HTTP响应内容的字符串形式,即,uRL对应的页面内容。 print(r.encoding) # 从HTTP header中猜测的响应内容编码方式 print(r.apparent_encoding) # 内容中分析出的响应内容编码方式 print(r.content) # 响应内容的二进制形式 (处理图片,视频等使用) r.encoding = r.apparent_encoding # 转化编码 r.apparent_encoding 根据它的结果转码 print(r.text)
六、通用代码框架
def getHTMLText(url): try: r = requests.get(url,timeout = 30) r.raise_for_status() # 如果状态是200,引发异常 r.encoding = r.apparent_encoding return r.text except: return "404" if __name__ == "__main__": # 证明小明是自己人,不用在执行这段代码 url = "http://www.baidu.com" print(getHTMLText(url))
●涉及到异常处理用Python的 try -- except 语句。
try语句里面有四句,第一句是get方法、第二句判断是否链接异常、第三句用表兄弟替代encoding去找编写格式,第四句返回内容。
●def 是自定义函数的意思
●if __name__ == ‘__main__‘
通俗的理解__name__ == ‘__main__‘:假如你叫小明.py,在朋友眼中,你是小明(__name__ == ‘小明‘);在你自己眼中,你是你自己(__name__ == ‘__main__‘)。
if __name__ == ‘__main__‘的意思是:当.py文件被直接运行时,if __name__ == ‘__main__‘之下的代码块将被运行;当.py文件以模块形式被导入时,if __name__ == ‘__main__‘之下的代码块不被运行。
相信参考这里:https://blog.csdn.net/yjk13703623757/article/details/77918633/
以上是关于爬虫从入门到放弃——爬虫的基本原理的主要内容,如果未能解决你的问题,请参考以下文章