HBase数据存取流程
Posted nicoleljc
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HBase数据存取流程相关的知识,希望对你有一定的参考价值。
一、HBase的特点是什么
1.HBase一个分布式的基于列式存储或者行式存储的数据库,基于hadoop的hdfs存储,zookeeper进行管理。
2.HBase适合存储半结构化或非结构化数据,对于数据结构字段不够确定或者杂乱无章很难按一个概念去抽取的数据。
3.HBase为null的记录不会被存储.
4.数据存储模式为key,value模式:(Table,Rowkey,Column,Timestamp)-> value
5.HBase是主从架构。Hmaster作为主节点,Hregionserver作为从节点。
二、HBase存数据流程
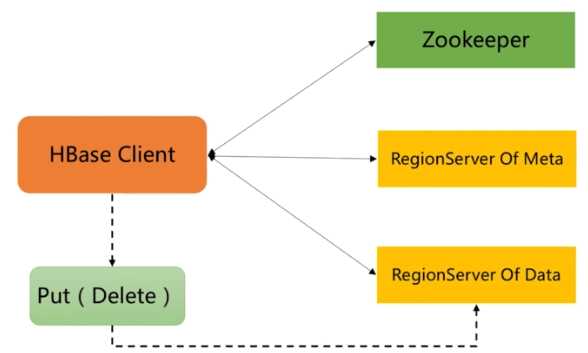
流程:Client请求Zookeeper确定meta表所在的RegionServer所在的地址,接着根据Rowkey找到数据所归属的RegionServer;用户提交put或delete请求时HbaseClient会将put或delete请求添加到本地buffer中,符合一定条件
会通过异步批量提交服务器处理。
接着数据到达Region后,服务端处理流程如下:
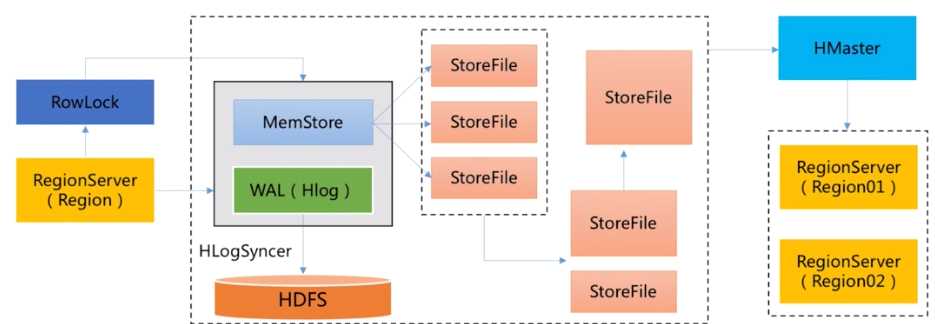
流程:RegionServer去获取RowLock,region更新共享锁;接着Hbase会先写写日志WAL(数据可靠性)再写缓存MemStore(阈值默认64M,每个列族对应一个Store下的MemStore);然后释放锁后将日志落到HDFS;若MemStore达到阈值则将缓存数据落磁盘StoreFile,最后多个StoreFile发生合并;若StoreFile很大会触发split操作,将当前region分割成2个Region,并同步到Hmaster。
三、HBase取数据流程
HbaseClient的操作和存数据类似
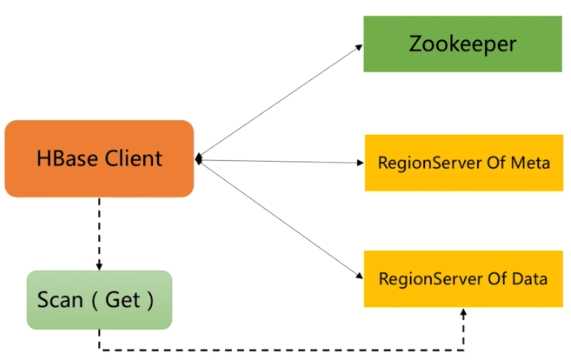
服务器操作流程:
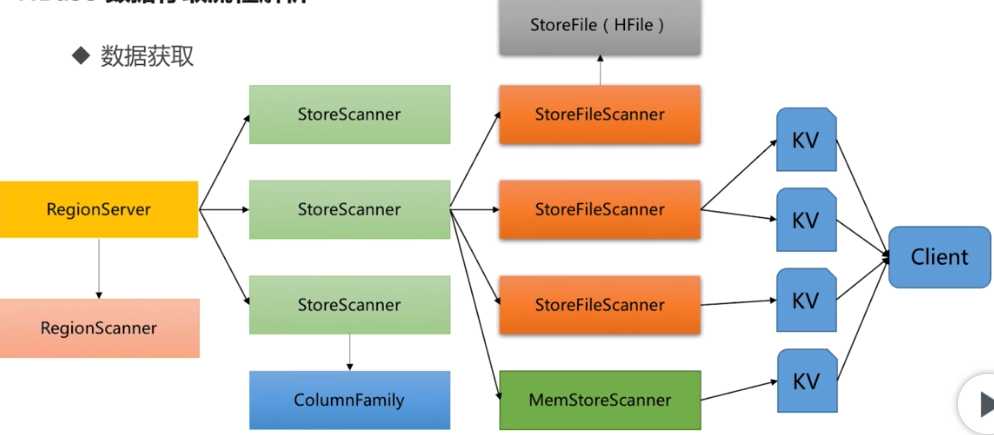
RegionServer收到get请求后,对当前Region进行Scan,接着会根据列族对Store进行Scan,同时会对对应的MemStore进行Scan;最后找到我们要的数据返回给Client。注意:一个StoreScanner会对应多个StoreFileScanner,整个过程是一个层级关系。
四、HBase存取优化
检索优化(BloomFilter):应用BloomFilter来提高随机读的性能,BloomFilter是列族级别的配置
五、HBase API使用



以上是关于HBase数据存取流程的主要内容,如果未能解决你的问题,请参考以下文章
2021年大数据HBase(十三):HBase读取和存储数据的流程