JDK源码--HashMap(之resize)
Posted pheonixhkbxoic
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK源码--HashMap(之resize)相关的知识,希望对你有一定的参考价值。
1.HashMap源码阅读目标
了解具体的数据结构(hash及冲突链表、红黑树)和重要方法的具体实现(hashCode、equals、put、resize...)
2.重要方法
hashCode 与 equals都是在AbstractMap中定义的
hashCode是各元素hash的累加 h += iter.next().hashCode();
equals 1.是否是本身; 2.是否是Map实例; 3.size是否相等; 4.比较每个value
重点在于put、resize具体实现步骤:
put:
1.tab为null或length为0 重新resize
2.位置hash(key) & (n-1)的元素为null,则直接赋值
3.既然对应位置的元素不为null,则要看它有什么类型(单个元素(hash无冲突)或红黑树或链表)
单个元素(新的元素如果与这个元素不相等)则要转为链表,链表则可能转为红黑树(转化规则 >= 7)
++modCount
4.++size > threshold 则resize()
remove类似(<=6则转化为链表)
1 final V putVal(int hash, K key, V value, boolean onlyIfAbsent, 2 boolean evict) { 3 Node<K,V>[] tab; Node<K,V> p; int n, i; 4 if ((tab = table) == null || (n = tab.length) == 0) 5 n = (tab = resize()).length; 6 if ((p = tab[i = (n - 1) & hash]) == null) 7 tab[i] = newNode(hash, key, value, null); 8 else { 9 Node<K,V> e; K k; 10 if (p.hash == hash && 11 ((k = p.key) == key || (key != null && key.equals(k)))) 12 e = p; 13 else if (p instanceof TreeNode) 14 e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); 15 else { 16 for (int binCount = 0; ; ++binCount) { 17 if ((e = p.next) == null) { 18 p.next = newNode(hash, key, value, null); 19 if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st 20 treeifyBin(tab, hash); 21 break; 22 } 23 if (e.hash == hash && 24 ((k = e.key) == key || (key != null && key.equals(k)))) 25 break; 26 p = e; 27 } 28 } 29 if (e != null) { // existing mapping for key 30 V oldValue = e.value; 31 if (!onlyIfAbsent || oldValue == null) 32 e.value = value; 33 afterNodeAccess(e); 34 return oldValue; 35 } 36 } 37 ++modCount; 38 if (++size > threshold) 39 resize(); 40 afterNodeInsertion(evict); 41 return null; 42 }
treeifyBin:
链表转为红黑树,红黑树较为复杂,所以将单独另起一篇仔细研究学习
keySet/entrySet:


1 new KeySet(); 2 forEach: 3 int mc = modCount; 4 for (int i = 0; i < tab.length; ++i) { 5 for (Node<K,V> e = tab[i]; e != null; e = e.next) 6 action.accept(e.key); 7 } 8 if (modCount != mc) 9 throw new ConcurrentModificationException();
resize:(重点在此)
JDK1.7中,resize时,index取得时,全部采用重新hash的方式进行了。JDK1.8对这个进行了改善。 以前要确定index的时候用的是(e.hash & oldCap-1),是取模取余,而这里用到的是(e.hash & oldCap),它有两种结果,一个是0,一个是oldCap, 比如oldCap=8,hash是3,11,19,27时,(e.hash & oldCap)的结果是0,8,0,8,这样3,19组成新的链表,index为3;而11,27组成新的链表,新分配的index为3+8; JDK1.7中重写hash是(e.hash & newCap-1),也就是3,11,19,27对16取余,也是3,11,3,11,和上面的结果一样,但是index为3的链表是19,3,index为3+8的链表是 27,11,也就是说1.7中经过resize后数据的顺序变成了倒叙,而1.8没有改变顺序。 原理: 我们使用的是2次幂的扩展(指长度扩为原来2倍),所以,元素的位置要么是在原位置,要么是在原位置再移动2次幂的位置。看下图可以明白这句话的意思,n为table的长度,图(a)表示扩容前的key1和key2两种key确定索引位置的示例,图(b)表示扩容后key1和key2两种key确定索引位置的示例,其中hash1是key1对应的哈希与高位运算结果。
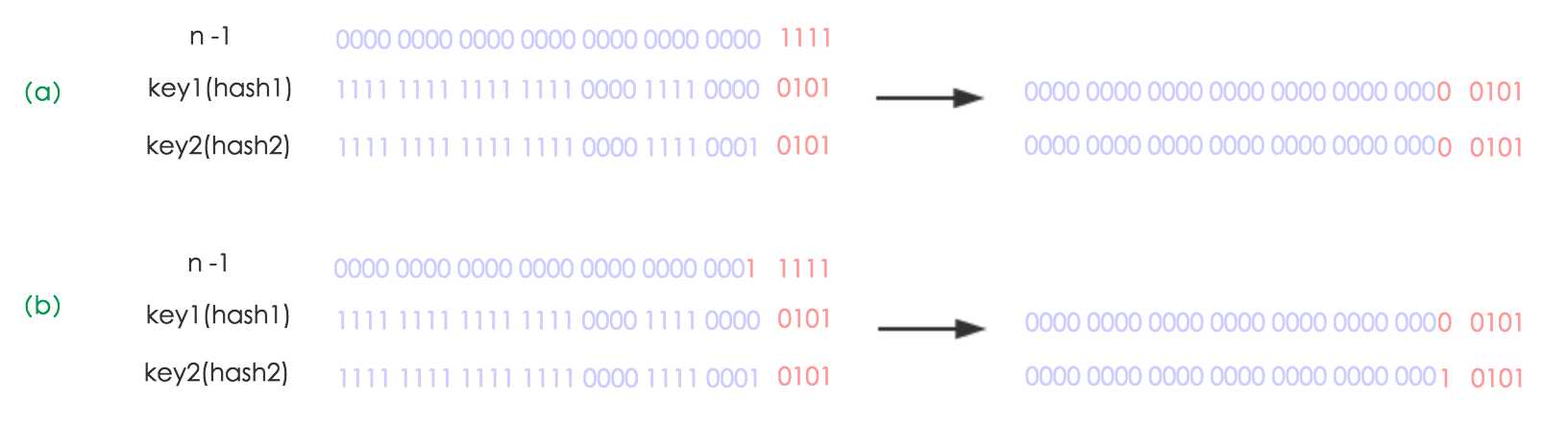
元素在重新计算hash之后,因为n变为2倍,那么n-1的mask范围在高位多1bit(红色),因此新的index就会发生这样的变化:
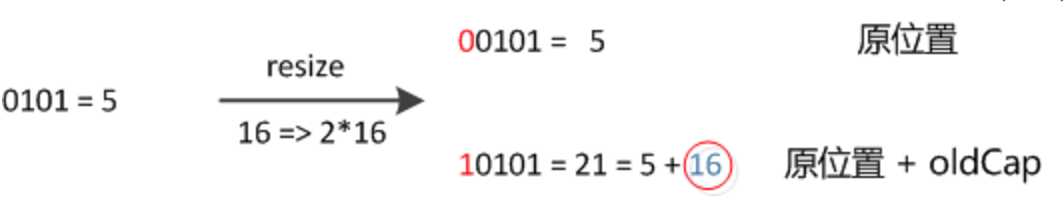
因此,我们在扩充HashMap的时候,不需要像JDK1.7的实现那样重新计算hash,只需要看看原来的hash值新增的那个bit是1还是0就好了,是0的话索引没变,是1的话索引变成“原索引+oldCap”,可以看看下图为16扩充为32的resize示意图:
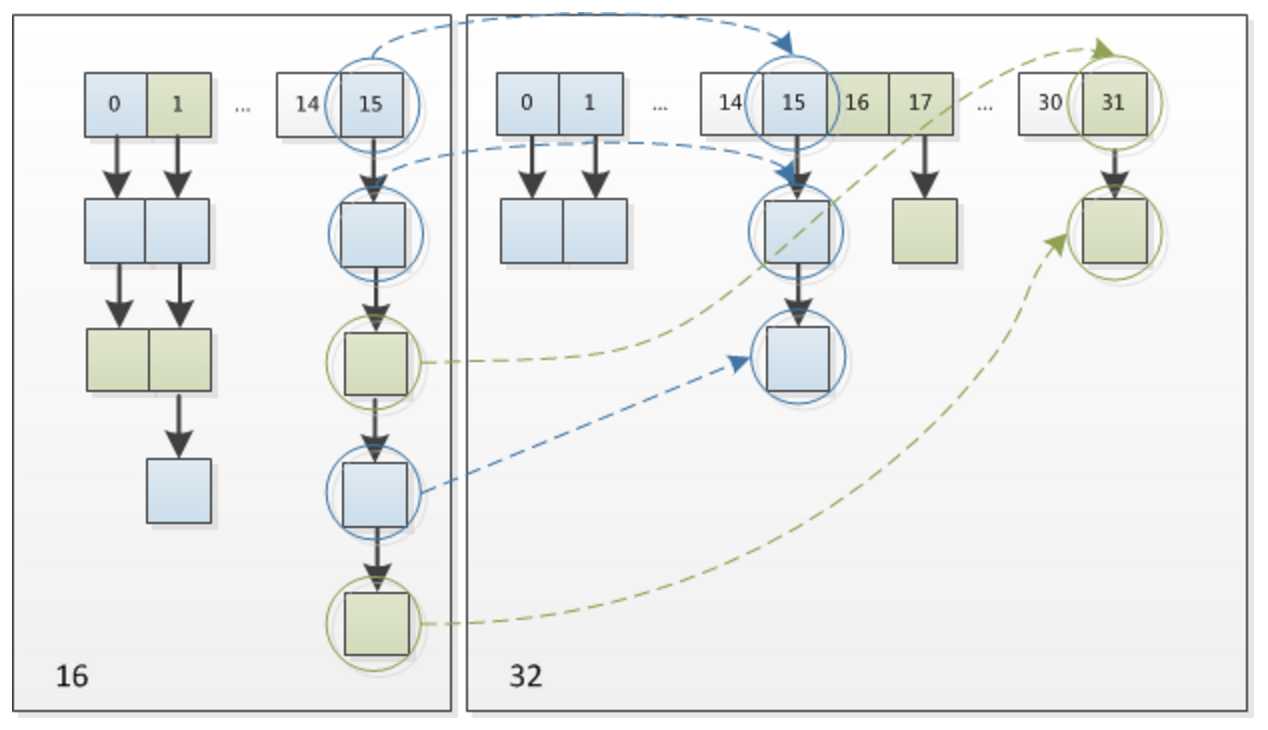
这个设计确实非常的巧妙,既省去了重新计算hash值的时间,而且同时,由于新增的1bit是0还是1可以认为是随机的,因此resize的过程,均匀的把之前的冲突的节点分散到新的bucket了。这一块就是JDK1.8新增的优化点。有一点注意区别,JDK1.7中rehash的时候,旧链表迁移新链表的时候,如果在新表的数组索引位置相同,则链表元素会倒置,但是从上图可以看出,JDK1.8不会倒置。 --------------------- 作者:bnmb888 来源:CSDN 原文:https://blog.csdn.net/bnmb888/article/details/77164485 版权声明:本文为博主原创文章,转载请附上博文链接!
上面的这位博主已经说的十分清楚了,鄙人也就不献丑了^_^, 详情可移步原博。
详细源码解析:在这里引用的是另一博主的(老艮头--JDK8:HashMap源码解析:resize方法)
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; //当前所有元素所在的数组,称为老的元素数组 int oldCap = (oldTab == null) ? 0 : oldTab.length; //老的元素数组长度 int oldThr = threshold; // 老的扩容阀值设置 int newCap, newThr = 0; // 新数组的容量,新数组的扩容阀值都初始化为0 if (oldCap > 0) { // 如果老数组长度大于0,说明已经存在元素 // PS1 if (oldCap >= MAXIMUM_CAPACITY) { // 如果数组元素个数大于等于限定的最大容量(2的30次方) // 扩容阀值设置为int最大值(2的31次方 -1 ),因为oldCap再乘2就溢出了。 threshold = Integer.MAX_VALUE; return oldTab; // 返回老的元素数组 } /* * 如果数组元素个数在正常范围内,那么新的数组容量为老的数组容量的2倍(左移1位相当于乘以2) * 如果扩容之后的新容量小于最大容量 并且 老的数组容量大于等于默认初始化容量(16),那么新数组的扩容阀值设置为老阀值的2倍。(老的数组容量大于16意味着:要么构造函数指定了一个大于16的初始化容量值,要么已经经历过了至少一次扩容) */ else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } // PS2 // 运行到这个else if 说明老数组没有任何元素 // 如果老数组的扩容阀值大于0,那么设置新数组的容量为该阀值 // 这一步也就意味着构造该map的时候,指定了初始化容量。 else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults // 能运行到这里的话,说明是调用无参构造函数创建的该map,并且第一次添加元素 newCap = DEFAULT_INITIAL_CAPACITY; // 设置新数组容量 为 16 newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); // 设置新数组扩容阀值为 16*0.75 = 12。0.75为负载因子(当元素个数达到容量了4分之3,那么扩容) } // 如果扩容阀值为0 (PS2的情况) if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); // 参见:PS2 } threshold = newThr; // 设置map的扩容阀值为 新的阀值 @SuppressWarnings({"rawtypes","unchecked"}) // 创建新的数组(对于第一次添加元素,那么这个数组就是第一个数组;对于存在oldTab的时候,那么这个数组就是要需要扩容到的新数组) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; // 将该map的table属性指向到该新数组 if (oldTab != null) { // 如果老数组不为空,说明是扩容操作,那么涉及到元素的转移操作 for (int j = 0; j < oldCap; ++j) { // 遍历老数组 Node<K,V> e; if ((e = oldTab[j]) != null) { // 如果当前位置元素不为空,那么需要转移该元素到新数组 oldTab[j] = null; // 释放掉老数组对于要转移走的元素的引用(主要为了使得数组可被回收) if (e.next == null) // 如果元素没有有下一个节点,说明该元素不存在hash冲突 // PS3 // 把元素存储到新的数组中,存储到数组的哪个位置需要根据hash值和数组长度来进行取模 // 【hash值 % 数组长度】 = 【 hash值 & (数组长度-1)】 // 这种与运算求模的方式要求 数组长度必须是2的N次方,但是可以通过构造函数随意指定初始化容量呀,如果指定了17,15这种,岂不是出问题了就?没关系,最终会通过tableSizeFor方法将用户指定的转化为大于其并且最相近的2的N次方。 15 -> 16、17-> 32 newTab[e.hash & (newCap - 1)] = e; // 如果该元素有下一个节点,那么说明该位置上存在一个链表了(hash相同的多个元素以链表的方式存储到了老数组的这个位置上了) // 例如:数组长度为16,那么hash值为1(1%16=1)的和hash值为17(17%16=1)的两个元素都是会存储在数组的第2个位置上(对应数组下标为1),当数组扩容为32(1%32=1)时,hash值为1的还应该存储在新数组的第二个位置上,但是hash值为17(17%32=17)的就应该存储在新数组的第18个位置上了。 // 所以,数组扩容后,所有元素都需要重新计算在新数组中的位置。 else if (e instanceof TreeNode) // 如果该节点为TreeNode类型 ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); // 此处单独展开讨论 else { // preserve order Node<K,V> loHead = null, loTail = null; // 按命名来翻译的话,应该叫低位首尾节点 Node<K,V> hiHead = null, hiTail = null; // 按命名来翻译的话,应该叫高位首尾节点 // 以上的低位指的是新数组的 0 到 oldCap-1 、高位指定的是oldCap 到 newCap - 1 Node<K,V> next; // 遍历链表 do { next = e.next; // 这一步判断好狠,拿元素的hash值 和 老数组的长度 做与运算 // PS3里曾说到,数组的长度一定是2的N次方(例如16),如果hash值和该长度做与运算,结果为0,就说明该hash值一定小于数组长度(例如hash值为1),那么该hash值再和新数组的长度取摸的话,还是hash值本身,所该元素的在新数组的位置和在老数组的位置是相同的,所以该元素可以放置在低位链表中。 if ((e.hash & oldCap) == 0) { // PS4 if (loTail == null) // 如果没有尾,说明链表为空 loHead = e; // 链表为空时,头节点指向该元素 else loTail.next = e; // 如果有尾,那么链表不为空,把该元素挂到链表的最后。 loTail = e; // 把尾节点设置为当前元素 } // 如果与运算结果不为0,说明hash值大于老数组长度(例如hash值为17) // 此时该元素应该放置到新数组的高位位置上 // 例:老数组长度16,那么新数组长度为32,hash为17的应该放置在数组的第17个位置上,也就是下标为16,那么下标为16已经属于高位了,低位是[0-15],高位是[16-31] else { // 以下逻辑同PS4 if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { // 低位的元素组成的链表还是放置在原来的位置 loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { // 高位的元素组成的链表放置的位置只是在原有位置上偏移了老数组的长度个位置。 hiTail.next = null; newTab[j + oldCap] = hiHead; // 例:hash为 17 在老数组放置在0下标,在新数组放置在16下标; hash为 18 在老数组放置在1下标,在新数组放置在17下标; } } } } } return newTab; // 返回新数组 }
以上是关于JDK源码--HashMap(之resize)的主要内容,如果未能解决你的问题,请参考以下文章