RAM-Based Shift Register (ALTSHIFT_TAPS) IP Core-实现3X3像素阵列存储
Posted dinging006
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RAM-Based Shift Register (ALTSHIFT_TAPS) IP Core-实现3X3像素阵列存储相关的知识,希望对你有一定的参考价值。
最近想要实现CNN的FPGA加速处理,首先明确在CNN计算的过程中,因为卷积运算是最耗时间的,因此只要将卷积运算在FPGA上并行实现,即可完成部分运算的加速
那么对于卷积的FPGA实现首先要考虑的是卷积子模板具体如何实现,我们在matlab或者c实现比如3X3的子模板的时候,只要用一个数组即可将模板的数据存储起来,而在FPGA的话有以下三种方法:
- 用2个或3个RAM存储3X3像素阵列
- 用2个或3个FIFO存储3X3像素阵列
- 用shift_RAM移位存储3X3像素阵列
而shift_RAM好像就是为了阵列的实现量身定做的一般。
shift_RAM的配置参数主要有以下几个:
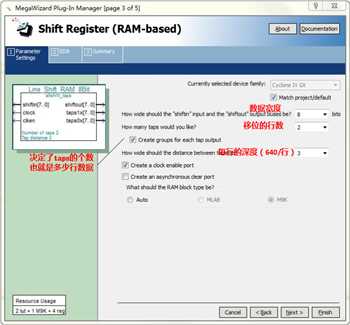
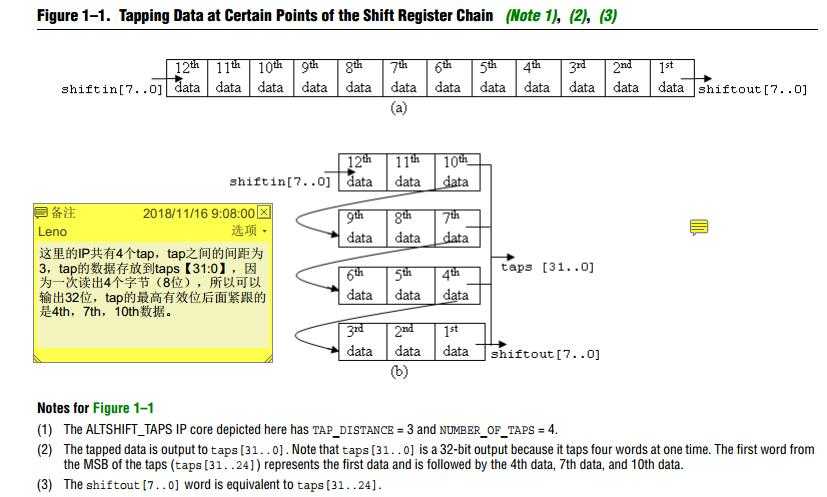
手册中可以参考理解的一个非常形象的图如下:
进一步的进行单独一个IP核的仿真后得到:

其中上述参数设置分别为8,2,3,上述仿真图中,相当于把一个矩阵A通过移位寄存的方法通过row3_data送入到RAM,然后分三行输出,在游标所示处就可以开始输出3X3矩阵
0,56,-122
92,50,-57
-58,-13,-61
以下部分是加入了对视频信号处理控制后的代码实现过程:
/*----------------------------------------------------------------------- CONFIDENTIAL IN CONFIDENCE This confidential and proprietary software may be only used as authorized by a licensing agreement from CrazyBingo (Thereturnofbingo). In the event of publication, the following notice is applicable: Copyright (C) 2011-20xx CrazyBingo Corporation The entire notice above must be reproduced on all authorized copies. Author : CrazyBingo Technology blogs : http://blog.chinaaet.com/crazybingo Email Address : [email protected] Filename : VIP_Matrix_Generate_3X3_8Bit.v Data : 2014-03-19 Description : Generate 8Bit 3X3 Matrix for Video Image Processor. Give up the 1th and 2th row edge data caculate for simple process Give up the 1th and 2th point of 1 line for simple process Modification History : Data By Version Change Description ========================================================================= 13/05/26 CrazyBingo 1.0 Original 14/03/16 CrazyBingo 2.0 Modification -*/ `timescale 1ns/1ns module VIP_Matrix_Generate_3X3_8Bit #( parameter [9:0] IMG_HDISP = 10‘d640, //640*480 parameter [9:0] IMG_VDISP = 10‘d480 ) ( //global clock input clk, //cmos video pixel clock input rst_n, //global reset //Image data prepred to be processd input per_frame_vsync, //Prepared Image data vsync valid signal input per_frame_href, //Prepared Image data href vaild signal input per_frame_clken, //Prepared Image data output/capture enable clock input [7:0] per_img_Y, //Prepared Image brightness input //Image data has been processd output matrix_frame_vsync, //Prepared Image data vsync valid signal output matrix_frame_href, //Prepared Image data href vaild signal output matrix_frame_clken, //Prepared Image data output/capture enable clock output reg [7:0] matrix_p11, matrix_p12, matrix_p13, //3X3 Matrix output output reg [7:0] matrix_p21, matrix_p22, matrix_p23, output reg [7:0] matrix_p31, matrix_p32, matrix_p33 ); //Generate 3*3 matrix //-------------------------------------------------------------------------- //-------------------------------------------------------------------------- //-------------------------------------------------------------------------- //sync row3_data with per_frame_clken & row1_data & raw2_data wire [7:0] row1_data; //frame data of the 1th row wire [7:0] row2_data; //frame data of the 2th row reg [7:0] row3_data; //frame data of the 3th row always@(posedge clk or negedge rst_n) begin if(!rst_n) row3_data <= 0; else begin if(per_frame_clken) row3_data <= per_img_Y; else row3_data <= row3_data; end end //--------------------------------------- //module of shift ram for raw data wire shift_clk_en = per_frame_clken; Line_Shift_RAM_8Bit #( .RAM_Length (IMG_HDISP) ) u_Line_Shift_RAM_8Bit ( .clock (clk), .clken (shift_clk_en), //pixel enable clock // .aclr (1‘b0), .shiftin (row3_data), //Current data input .taps0x (row2_data), //Last row data .taps1x (row1_data), //Up a row data .shiftout () ); //------------------------------------------ //lag 2 clocks signal sync 因为数据存储耗费了一个时钟,因此3*3阵列读取使能和时钟要偏移一个时钟 reg [1:0] per_frame_vsync_r; reg [1:0] per_frame_href_r; reg [1:0] per_frame_clken_r; always@(posedge clk or negedge rst_n) begin if(!rst_n) begin per_frame_vsync_r <= 0; per_frame_href_r <= 0; per_frame_clken_r <= 0; end else begin per_frame_vsync_r <= {per_frame_vsync_r[0], per_frame_vsync}; per_frame_href_r <= {per_frame_href_r[0], per_frame_href}; per_frame_clken_r <= {per_frame_clken_r[0], per_frame_clken}; end end //Give up the 1th and 2th row edge data caculate for simple process //Give up the 1th and 2th point of 1 line for simple process wire read_frame_href = per_frame_href_r[0]; //RAM read href sync signal wire read_frame_clken = per_frame_clken_r[0]; //RAM read enable //将存储RAM以及阵列生成两个步骤需要的时钟都去掉 assign matrix_frame_vsync = per_frame_vsync_r[1]; assign matrix_frame_href = per_frame_href_r[1]; assign matrix_frame_clken = per_frame_clken_r[1]; //---------------------------------------------------------------------------- //---------------------------------------------------------------------------- /****************************************************************************** ---------- Convert Matrix ---------- [ P31 -> P32 -> P33 -> ] ---> [ P11 P12 P13 ] [ P21 -> P22 -> P23 -> ] ---> [ P21 P22 P23 ] [ P11 -> P12 -> P11 -> ] ---> [ P31 P32 P33 ] ******************************************************************************/ //--------------------------------------------------------------------------- //--------------------------------------------------- /*********************************************** (1) Read data from Shift_RAM (2) Caculate the Sobel (3) Steady data after Sobel generate ************************************************/ //wire [23:0] matrix_row1 = {matrix_p11, matrix_p12, matrix_p13}; //Just for test //wire [23:0] matrix_row2 = {matrix_p21, matrix_p22, matrix_p23}; //wire [23:0] matrix_row3 = {matrix_p31, matrix_p32, matrix_p33}; always@(posedge clk or negedge rst_n) begin if(!rst_n) begin {matrix_p11, matrix_p12, matrix_p13} <= 24‘h0; {matrix_p21, matrix_p22, matrix_p23} <= 24‘h0; {matrix_p31, matrix_p32, matrix_p33} <= 24‘h0; end else if(read_frame_href) begin if(read_frame_clken) //Shift_RAM data read clock enable begin {matrix_p11, matrix_p12, matrix_p13} <= {matrix_p12, matrix_p13, row1_data}; //1th shift input {matrix_p21, matrix_p22, matrix_p23} <= {matrix_p22, matrix_p23, row2_data}; //2th shift input {matrix_p31, matrix_p32, matrix_p33} <= {matrix_p32, matrix_p33, row3_data}; //3th shift input end else begin {matrix_p11, matrix_p12, matrix_p13} <= {matrix_p11, matrix_p12, matrix_p13}; {matrix_p21, matrix_p22, matrix_p23} <= {matrix_p21, matrix_p22, matrix_p23}; {matrix_p31, matrix_p32, matrix_p33} <= {matrix_p31, matrix_p32, matrix_p33}; end end else begin {matrix_p11, matrix_p12, matrix_p13} <= 24‘h0; {matrix_p21, matrix_p22, matrix_p23} <= 24‘h0; {matrix_p31, matrix_p32, matrix_p33} <= 24‘h0; end end endmodule //注意这里得到的每一行得第一第二的像素都没有用到,而且最后一行的像素没有被运算。
以上是关于RAM-Based Shift Register (ALTSHIFT_TAPS) IP Core-实现3X3像素阵列存储的主要内容,如果未能解决你的问题,请参考以下文章