生成对抗网络与图像分割
Posted ariel-dreamland
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了生成对抗网络与图像分割相关的知识,希望对你有一定的参考价值。
深度学习已经在图像分类、检测、分割、高分辨率图像生成等诸多领域取得了突破性的成绩。但是它也存在一些问题。
首先,它与传统的机器学习方法一样,通常假设训练数据与测试数据服从同样的分布,或者是在训练数据上的预测结果与在测试数据上的预测结果服从同样的分布。而实际上这两者存在一定的偏差,比如在测试数据上的预测准确率就通常比在训练数据上的要低,这就是过度拟合的问题。
另一个问题是深度学习的模型(比如卷积神经网络)有时候并不能很好地学到训练数据中的一些特征。比如,在图像分割中,现有的模型通常对每个像素的类别进行预测,像素级别的准确率可能会很高,但是像素与像素之间的相互关系就容易被忽略,使得分割结果不够连续或者明显地使某一个物体在分割结果中的尺寸、形状与在金标准中的尺寸、形状差别较大。
1、对抗学习
对抗学习(adversarial learning)就是为了解决上述问题而被提出的一种方法。学习的过程可以看做是我们要得到一个模型(例如CNN),使得它在一个输入数据X上得到的输出结果尽可能与真实的结果Y(金标准)一致。
在这个过程中使用一个鉴别器(discriminator),它可以识别出一个结果y到底是来自模型的预测值还是来自真实的结果。如果这个鉴别器的水平很高,而它又把X和Y搞混了,无法分清它们之间的区别,那么就说明我们需要的模型具有很好的表达或者预测能力。
2、GAN用于图像分割
Semantic Segmentation using Adversarial Networks (https://arxiv.org/abs/1611.08408, 25Nov 2016),这篇文章第一个将对抗网络(adversarial network)应用到图像分割中,该文章中的方法如下图。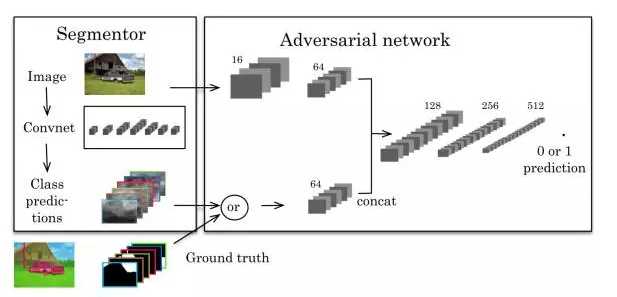
左边是一个CNN的分割模型,右边是一个对抗网络。对抗网络的输入有两种情况,一是原始图像+金标准,二是原始图像+分割结果。它的输出是一个分类值(1代表它判断输入是第一种情况,0代表它判断输入是第二种情况)。代价函数定义为:
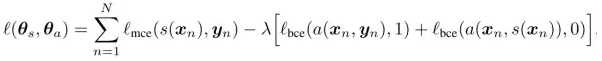
其中Θs和Θa分别是分割模型和对抗模型的参数。yn是金标准,s(xn)是分割结果。上式第一项是经典的分割模型的代价函数,例如交叉熵(cross entropy)即概率值的负对数。第二项和第三项是对抗模型的代价函数,由于希望对抗模型尽可能难以判别yn和S(xn), 第二项的权重是-λ。
训练过程中,交替训练对抗模型(Θa)和分割模型(Θs)。训练对抗模型的代价函数为:
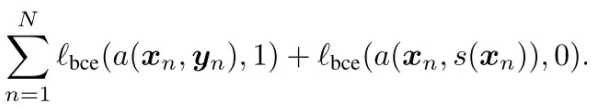
使该函数最小化,得到性能尽可能好的判别器,即对抗模型。训练分割模型的代价函数为:
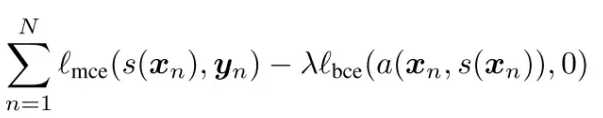
yn与s(xn)在像素级别尽可能接近,另一方面尽可能使判别器从整体上无法区分它们。下图是一个分割的结果,可见对抗模型得到的结果在空间上更加具有一致性。
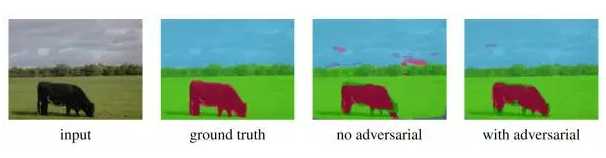
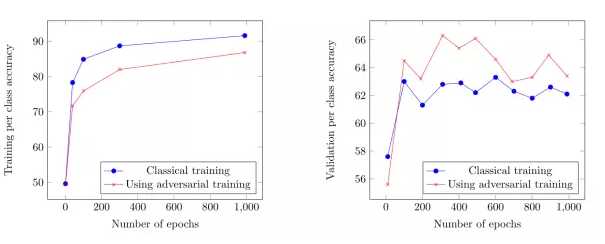
另外从训练过程中的性能上也可以看出,使用对抗训练,降低了过度拟合。
3、GAN用于半监督学习
An Adversarial Regularisation for Semi-Supervised Training of Structured Output Neural Networks(https://arxiv.org/pdf/1702.02382.pdf, 8 Feb 2017),这篇文章中使用对抗网络来做图像分割的半监督学习。半监督学习中一部分数据有标记,而另一部分数据无标记,可以在准备训练数据的过程中节省大量的人力物力。
假设(xt,λt)是有标记的训练数据,xu是未标记的训练数据, 理论上分割结果fw(xt)与fw(xu)应该同分布,实际上由于x的维度太大而训练数据不足以表达它的所有变化,因此fw(xt)与fw(xu)存在一定偏差。该文中使用一个判别器δu(y)来得到来自于有标记的训练数据的分割结果fw(xt)的概率,1-δu(y)作为y是来自于未标记的训练数据的分割结果的概率。
训练过程的代价函数为: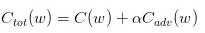
C(w)是常规的基于标记数据的代价函数,Cadv(w)是基于未标记数据的代价函数,定义为:
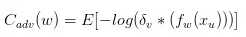
该代价函数使分割算法在标记数据和未标记数据上得到尽可能一致的结果。整个算法可以理解成通过使用未标记数据,实现对分割网络的参数的规则化。
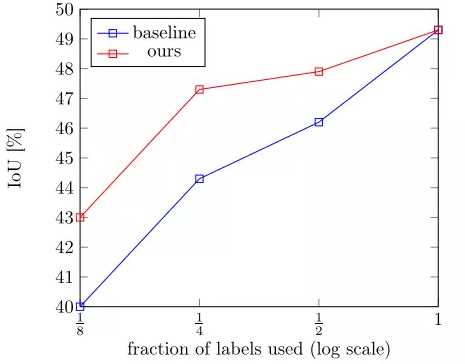
上图是在CamVid数据集上分别使用1/8, 1/4, 1/2 和1/1的标记数据进行训练的结果。相比于蓝线只使用标记数据进行训练,该方法得到了较大的性能提高,如红线所示。
4、GAN用于域适应的分割
关于域的理解:域适配当中的域指的是一个领域,类似于聚类中的簇。通常,域适配的文章中的实验是针对分类任务的,某个类别就可以看作是一个领域域。但是在分割任务重,一个域指的是一类分割场景,比如街道场景、游戏场景。这里的场景中包含多中类别的物体,但是就分割任务而言,某一个场景就是一个领域。
目前的自适应语义分割的训练策略包含两种:对抗训练和自训练。针对语义分割网络的架构,分别从输入和输出来做文章。
FCNs in the Wild: Pixel-level Adversarial and Constraint-based Adaptation (https://arxiv.org/abs/1612.02649, 8 Dec 2016 ),这篇文章将对抗学习用到基于域适应的分割中。
域适应是指将在一个数据集上A训练得到的模型用到与之类似的一个数据集B上,这两个数据集的数据分布有一定的偏移(distribution shift),也叫做域偏移(domain shift)。A 被称为源域 source domain,B被称为目标域 target domain。源域中的数据是有标记的,而目标域的数据没有标记,这种问题就被称为非监督域适应。该文章要解决的问题如下图所示: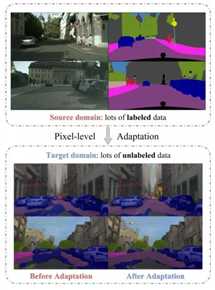
该文章认为一个好的分割算法应该对图像是来自于源域还是目标域不敏感。具体而言就是从输入图像中提取的抽象特征不受域之间的差异影响,因此从源域中的图像提取的抽象特征与从目标域中的图像提取的抽象特征很接近。那么如果用一个判别器来判断这个抽象特征是来自于源域中的图像还是来自于目标域中的图像,这个判别器应该尽量无法判断出来。方法的示意图如下: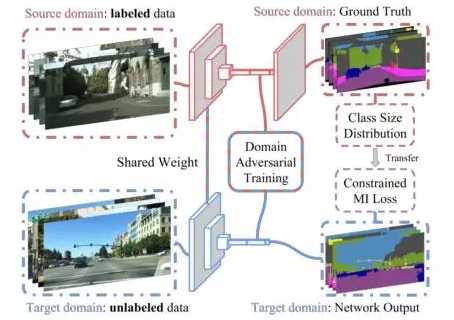
文章认为有两个方面引起了域之间的偏移,一个是全局性的,比如不同天气状况下的街道场景,一个是与特定的类别相关的 ,比如不同国家城市之间的交通标志。 因此在代价函数中考虑了这两种情况:
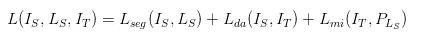
其中,第一项是通常的监督学习的代价函数。
第二项是对抗学习的目标函数,该函数又包括两个最小化过程,一个是更新特征提取网络,使得从两个域中的图像提取的特征接近从而判别器无法区分,一个是更新判别器参数,使它尽可能区分两个域中的图像的特征。
第三项Lmi(IT,PLs)是一个与特定类别有关的代价函数。其思想是利用源域中的标记结果,统计出各个类别物体的尺寸范围,再用这些尺寸范围作为先验知识去限制目标域中图像的分割结果。
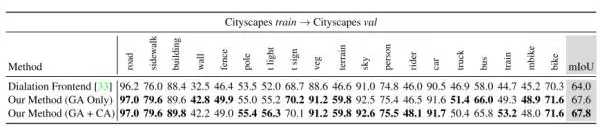
上图是在Cityscapes数据集上的结果。实验中把训练集作为源域,验证集作为目标域,分别展示了只使用全局性的域适应(GA)和类别特异性域适应(CA)的结果。
5、小结
对抗学习的概念就是引入一个判别器来解决不同数据域之间分布不一致的问题,通过使判别器无法区分两个不同域的数据,间接使它们属于同一个分布,从而作为一个规则化的方法去指导深度学习模型更新参数,达到更好的效果。关于它的数学证明,可以参见[1]。
6、参考资料
[1] Goodfellow, Ian, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. "Generative adversarial nets." In Advances in neural information processing systems, pp. 2672-2680. 2014.
[2] Luc, Pauline, Camille Couprie, Soumith Chintala, and Jakob Verbeek. "Semantic Segmentation using Adversarial Networks." arXiv preprint arXiv:1611.08408 (2016).
[3] Mateusz Koziński, Lo?c Simon, Frédéric Jurie, "An Adversarial Regularisation for Semi-Supervised Training of Structured Output Neural Networks", arXiv preprint arXiv:1702.02382(2017).
[4] Hoffman, Judy, Dequan Wang, Fisher Yu, and Trevor Darrell. "FCNs in the Wild: Pixel-level Adversarial and Constraint-based Adaptation." arXiv preprint arXiv:1612.02649 (2016).
[5] Ledig, Christian, Lucas Theis, Ferenc Huszár, Jose Caballero, Andrew Cunningham, Alejandro Acosta, Andrew Aitken et al. "Photo-realistic single image super-resolution using a generative adversarial network." arXiv preprint arXiv:1609.04802 (2016)
感谢作者,参考资料:
https://blog.csdn.net/shenziheng1/article/details/72821001
https://blog.csdn.net/hairui88/article/details/83692090
以上是关于生成对抗网络与图像分割的主要内容,如果未能解决你的问题,请参考以下文章