2017-2018-1 20155315 《信息安全系统设计基础》第14周学习总结
教材学习内容总结
- 上一周我学习了I/O设备,这一周我学习了第六章,知道了内在的存储设备及磁盘构造,也更明白程序运行的道理,对我之后设计程序有很大的帮助。
- 在简单模型中,存储器系统是一个线性的字节数组,而CPU能够在一个常数时间内访问每个存储器位置。实际上,存储器系统是一个具有不同容量、成本和访问时间的存储设备的层次结构。CPU寄存器保存着最常用的数据。靠近CPU的小的、快速的高度缓存存储器作为一部分存储在相对慢速的主存储器中的数据和指令的缓冲区域。 存储器层次结构是可行的。
RAM
- SRAM(静态):SRAM将每个位存储在一个双稳态的存储单元里。只要有电,他就会永远保持他的值。即使有干扰来扰乱电压,当干扰消除时,电路就会恢复稳定值。
- DRAM(动态):DRAM将每个位存储为对一个电容的充电。与SRAM不同,DRAM存储单元易受干扰。当电容的电压被扰乱后,他就永远不会恢复了。
- 特性:
- 只要供电SRAM就会保持不变。
- SRAM的存取比DRAM快。
- SRAM对干扰不敏感。
- SRAM单元比DRAM单元使用更多晶体管,密度较低,更贵,功耗更大。
- 传统的DRAM
- 行地址i:RAS
- 列地址j:CAS
- DRAM组织成二位阵列而不是线性数组的一个原因是降低芯片上地址引脚的数量。
- 二维阵列组织的缺点是必须分两步发送地址,这增加了访问时间。
- 存储器模块
- DRAM芯片包装在存储器模块中,他是插到主板的扩展槽位上的。常见的包括168个引脚的双列直插存储器模块,以64位为块传送数据到存储控制器和从存储控制器传出数据,还包括72个引脚的单列直插存储器模块,以32位为块传送数据。
- 通过将多个存储器模块连接到存储控制器,能够聚合主存,当控制器收到一个地址A时,控制器选择包含A的模块k,将A转换为它的(i, j)的模式,并将(i, j)发送到模块k。
- 增强的DRAM
- 快页模式DRAM(FPM DRAM):异步控制信号,允许对同一行连续的访问可以直接从行缓冲区得到服务。
- 扩展数据输出DRAM(EDO DRAM):异步控制信号,允许单独的CAS信号在时间上靠的更紧密一点。
- 同步DRAM(SDRAM):同步的控制信号,比异步的快。
- 双倍数据速率同步DRAM(DDR SDRAM):使用两个时钟沿作为控制信号,使DRAM速度翻倍。
- Rambus DRAM(RDRAM):一种私有技术。
- 视频RAM(VRAM):用在图形系统的帧缓冲区中。
ROM,非易失性存储器
- 如果断电,DRAM和SRAM会丢失他们的信息,所以他们是易失的。
- 非易失性存储器,即使是在关电以后,也仍然保存着他们的信息。他们整体上都称为只读存储器(ROM)。
- ROM以他们能够被重新编程的次数和对他们进行重编程所用的机制来区分的。
- PROM 只能被编程一次。
- 可擦可编程ROM,有个透明的石英窗口,允许光到达存储单元。
- 闪存,是一类非易失性存储器,基于EEPROM,他已经成为了一种重要的存储技术。
- 存储在ROM中的程序通常称为固件。
磁盘
磁盘是由盘片构成的。每个盘片有两个盘面,表面覆盖着磁性记录材料。盘片中央有个可以旋转的主轴,使得盘片以固定的旋转速率旋转。
- 旋转速率:通常5400~15000/min
- 磁道:同心圆们
- 扇区:每个磁道被划分为一组扇区
- 数据位:每个扇区包含相等数量的~,通常为512字节
- 间隙:存储用来标识扇区的格式化位
- 磁盘驱动器-磁盘-旋转磁盘
柱面:所有盘片表面上到主轴中心的距离相等的磁道的集合。
- 磁盘容量是由以下技术因素决定的:记录密度、磁道密度、面密度
- 记录密度:磁道一英寸的段可以放入的位数。
- 磁道密度:从盘片中心出发半径上一英寸的段内可以有的磁道数。
- 面密度:记录密度与磁道密度的乘积。
- 磁盘容量计算公式:

磁盘操作
- 磁盘以扇区大小的块来读写数据。
- 对扇区的访问时间有三个主要部分组成:
- 寻道时间:移动传动臂所用的时间。依赖于读/写头以前的位置和传动臂在盘面上移动的速度。通常为3-9ms,最大可达20ms。
- 旋转时间:驱动器等待目标扇区的第一个位旋转到读/写头下,依赖于盘面位置和旋转速度。最大旋转延迟=1/RPM X 0secs/min (s),
平均旋转时间是最大值的一半。 - 传送时间:依赖于旋转速度和每条磁道的扇区数目,平均传送时间= 1/RPM x 1/(平均扇区数/磁道) x 60s/1min,访问一个磁盘扇区内容的平均时间为平均寻道时间,平均旋转延迟和平均传送时间之和。
访问一个磁盘扇区的512字节的主要时间在于寻道和旋转延迟。访问时间:磁盘>DRAM>SRAM
逻辑磁盘块
- 现代磁盘构造复杂,有多个盘面,这些盘面上有不同的记录区。为了对操作系统隐藏这样的复杂性,现代磁盘将它们的构造简化为一个b个扇区大小的逻辑块的序列,编号为0,1,2,...b-1。磁盘中有一个小的硬件/固件设备,称为磁盘控制器,维护着逻辑块号的和实际(物理)磁盘扇区之间的映射关系。
局部性
- 循环体里的指令是按照连续的存储器顺序执行的,因此循环有良好的空间局部性,因为循环体会被执行多次,所以它也有良好的时间局部性。
- 代码区别于程序数据的一个重要属性时在运行时是不能被修改的。
- 评价一个程序中局部性的简单原则:
- 重复引用同一个变量的程序有良好的时间局部性。
- 对于具有步长为k的引用模式的程序,步长越小,空间局部性越好;在存储器中以大步长跳来跳去的程序空间局部性会很差。
- 对于取指令来说,循环有很好的时间和空间局部性。循环体越小,循环迭代次数越多,局部性越好。
- 有良好局部性的程序比局部性差的程序运行得更快
- 概括来说,基于缓存的存储层次结构行之有效,是因为较慢的存储设备比较快的存储设备更便宜,还因为程序倾向于展示局部性。
利用时间局部性
由于时间局部性,同一数据对象可能会被多次使用。因为缓存比第一层的存储设备更快,对后面的命中的服务回避最开始的不命中的更快。
利用空间局部性
块通常包含有多个对象。由于空间局部性,我们会期望后面对该快中其他对象的访问能够补偿不命中后复制该块的花费。
现代系统中到处都使用了缓存。
存储器层次结构——缓存
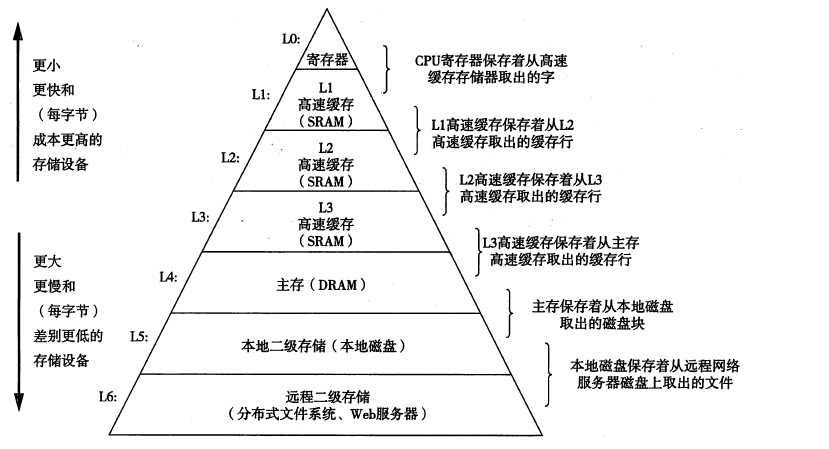
- 对于每个k,位于k层的更快更小的存储设备作为位于(k+1)层的更大更慢的存储设备的缓存。
- 第(k+1)层的存储器被划分成连续的数据对象片,称为块;数据总是以块大小为传送单元在相邻两层之间来回拷贝的;在任何时刻,第k层的缓存包括第(k+1)层块的一个子集的拷贝。
- 缓存命中及缓存不命中
- 缓存命中:当程序需要第(k+1)层的数据对象d的时候,首先会在第k层找d;如果d刚好缓存在第k层,那么就叫做缓存命中;反之,不命中
- 如果缓存不命中,那么第k层缓存就从第(k+1)层取出包含该数据的块,有可能会覆盖现有的块。覆=决定替换哪个块是由缓存的替换策略来控制的;例如,一个具有随机替换策略的缓存会随机选择;而LRU替换策略会选择被访问时间距今最远的块
- 缓存管理
- 在每一层上,某种形式的逻辑必须管理缓存;
- 可以是硬件也可以是硬件、软件的结合。
- 高速缓存存储器(S,E,B,m)
- 作用:连接CPU和主存
- 每个存储器地址有m位,形成M=2^m个不同地址。这m位被划分成t个标记位、s个组索引位和b个块偏移位。
- 一个机器的高速缓存被组织成S=2^s个高速缓存组的数组;每个数组包含E个高速缓存行;每行由一个B=2^b字节的数据块、一个有效位(指明这个行是否包含有效信息)、t=m-(b+s)个标记位(唯一标识存储在这个高速缓存行中的块)组成。
- 直接映射高速缓存
- 高速缓存确定一个请求是否命中,然后抽搐被请求字的过程,分为:组选择,行匹配,字抽取
- 组选择:从w的地址中抽取组索引;这些位被解释成对应于一个组号的无符号整数
- 行匹配:对于直接映射高速缓存,行匹配是容易而且快的;因为每个组只有一行
- 字匹配:块偏移提供的是这个字的第一个字节是从哪个位置开始的
缓存不冲突的种类
- 强制性不命中/冷不命中:即第k层的缓存是空的(称为冷缓存),对任何数据对象的访问都不会命中。通常是短暂事件,不会在反复访问存储器使得缓存暖身之后的稳定状态中出现。
- 冲突不命中:由于一个放置策略:将第k+1层的某个块限制放置在第k层块的一个小的子集中,这就会导致缓存没有满,但是那个对应的块满了,就会不命中。
- 容量不命中:当工作集的大小超过缓存的大小时,缓存会经历容量不命中,就是说缓存太小了,不能处理这个工作集。
练习题
6.1
- 接下来,设r表示一个DRAM阵列中的行数,c表示列数,br表示行寻址所需的位数,bc表示列寻址所需的位数。对于下面每个DRAM,确定2的幂数的阵列维数,使得max(br,bc)是对阵列的行或列寻址所需的位数中较大的值。
- 答案
| 组织 | r | c | br | bc | max(br,bc) |
|---|---|---|---|---|---|
| 16x1 | 4 | 4 | 2 | 2 | 2 |
| 16x4 | 4 | 4 | 2 | 2 | 2 |
| 128x8 | 16 | 8 | 4 | 3 | 4 |
| 512x4 | 32 | 16 | 5 | 4 | 5 |
| 1024x4 | 32 | 32 | 5 | 5 | 5 |
6.2
- 计算这样一个磁盘的容量,它有2个盘片,10000个柱面,每条磁道平均有400个扇区,而每个扇区有512个字节。
答案:
磁盘容量=512字节/扇区x400扇区/磁道x10000磁道/表面x2表面/盘片x2盘片/磁盘 =8192000000字节 =8.192GB
6.3
- 估计访问下面这个磁盘上一个扇区的访问时间(以ms为单位):
| 参数 | 值 |
|---|---|
| 旋转速率 | 15000RPM |
| Tavgseek | 8ms |
| 每条磁道的平均扇区数 | 500 |
答案:
平均旋转时间为:1/2x(60s/15000RPM)x1000ms/s=2ms 平均传送时间为:(60s/15000RPM)x1/500扇区/磁道x1000ms/s=0.008ms 总的预计访问时间为:8ms+2ms+0.008ms=10ms
教材学习中的问题和解决过程
问题1: 书本402页中图6-4所示,如果示例的128位DRAM被组织成一个16个超单元的线性数组,地址为0~15,为什么芯片会需要4个地址引脚而不是2个?
解决1:
DRAM组成二维阵列而不是一维线性数组的一个原因是降低芯片上地址引脚的数量。
例如,16个超单元组成的阵列,二维和一维分别需要2个和4个地址引脚。二维组织的缺点是,地址必须分两步发送,增加了访问时间。(一个行地址,一个列地址)。
问题2: 为什么要用中间的位作为组的索引,而不是组索引,标记位,和偏移量来定义地址
解决2:
如果用高位做索引,那么一些连续的内存块就会映射到相同的高速缓存块。这样的话,顺序扫描一个数组的元素,任何时刻,高速缓存都只保存着一个块的大小的数组内容,对高速缓存的使用效率很低。
代码托管
(statistics.sh脚本的运行结果截图)
结对及互评
其他(感悟、思考等,可选)
学习了磁盘管理之后,对一些较为简单的知识如存储覆盖等的理解都更深入了,对我之后处理程序也有帮助。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 5/5 | 1/1 | 25/25 | |
| 第二周 | 236/241 | 3/4 | 30/55 | |
| 第三周 | 169/410 | 2/6 | 30/85 | |
| 第四周 | 169/410 | 2/8 | 50/135 | |
| 第五周 | 1177/1587 | 2/10 | 30/165 | |
| 第六周 | 1826/3413 | 2/12 | 30/195 | |
| 第七周 | 977/4390 | 3/15 | 30/225 | |
| 第八周 | 977/4390 | 2/17 | 30/255 | |
| 第九周 | 977/4390 | 2/19 | 30/285 | |
| 第十周 | 977/4390 | 0/15 | 30/315 | |
| 第十一周 | 977/4390 | 2/21 | 25/335 | |
| 第十二周 | 977/4390 | 0/21 | 25/360 | |
| 第十三周 | 977/4390 | 2/23 | 30/390 | |
| 第十四周 | 865/5255 | 1/24 | 30/420 |
- 计划学习时间:20小时
- 实际学习时间:30小时
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)