
在游戏开发中,我们使用分布式ID。有很多优点
- 便于合服
- 便于ID管理
- 等等
一、单服各自ID系统的弊端
1. 列如合服
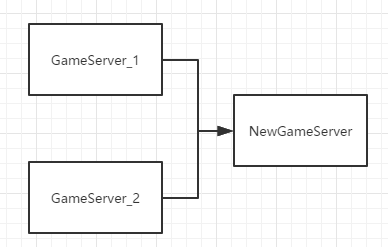
在游戏上线后,合服是避免不了的事情。如果按照传统的数据库表自增来作为数据的唯一ID、或者每个游戏中是相同的自增。这样在合服的时候你就会相当的麻烦了。
比如上图我们要把GameServer_2的数据合并到GameServer_1中,它们都有一个Player ID = 1的玩家,这个时候你就必须要重建GameServer_2中的Player_ID了。而引用了PlayerID的相关数据的PlayerID也全部需要修改。这还只是PlayerID的变化。在游戏中很多的表和关联,如果都要去修正ID,想想都可怕!
2. ID管理
在很多手游、页游中。都设计有跨服系统。一旦ID是各自自增。在跨服服务器你就傻傻分不清楚了。还有比如GM后台查询等等一系列问题。
二、分布式ID推荐
为了解决上面的问题,最好的解决办法就是采用分布式ID方案,分布式ID方案很多。java有自带的UUID。但是考虑到排序、存储空间等。UUID不是最佳的解决方案。下面我介绍一种分布式ID解决方案。
Twitter_Snowflake
SnowFlake的结构如下(每部分用-分开):
0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000
1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0
41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69
10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br>
12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号
加起来刚好64位,为一个Long型。<br>
SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。上面这种分位,可能有些不是很适合服务器很多的游戏。这里留给我们可部署的服务器节点站位10个
System.out.print(1 << 10);算得结果就是1024个服务器,1024个服务器对于大多数游戏应该是够用了。但是极个别的1024个服务器节点可能不够。我们可以有很多办法解决此问题。
1.独立ID服务器:
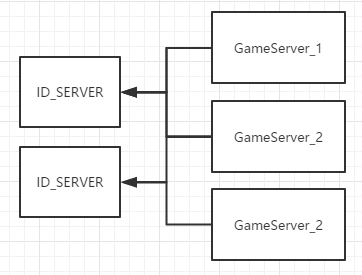
同一个ID_SERVER可以同时为多个游戏服务器提供ID,游戏服务器可以固定自定ID服务器,也可以吧ID服务器做成集群。这样我们的游戏就不受1024个节点的限制了!
但是有注意的一点,不要一个一个的去拿ID。毕竟不是当前进程去远程拿ID还是有网络、IO等消耗。较好的做法是一次拿一批,比如每次拿1000个然后缓存在本地服务器,当1000个快要耗尽时再去拿一批ID。
2.就是改Snowflake的分位
Snowflake能使用69年,如果觉得时间过长可以缩短时间的位数。比如39位可以用17年。那么我们机器标示就是12位就可以有4096个服务器节点。如果还是觉得不好我们可以把单位时间做到秒级时间占31位,我们现在还有32位可支配。后面自增系列16位,一秒钟可以生成65536个ID,同样机器标示位16位也可以65536个服务器节点。怎么组合就看你自己的需求了。
Snowflake源码
package com.sojoys.artifact.tools;
/**
* Twitter_Snowflake<br>
* SnowFlake的结构如下(每部分用-分开):<br>
* 0 - 0000000000 0000000000 0000000000 0000000000 0 - 00000 - 00000 - 000000000000 <br>
* 1位标识,由于long基本类型在Java中是带符号的,最高位是符号位,正数是0,负数是1,所以id一般是正数,最高位是0<br>
* 41位时间截(毫秒级),注意,41位时间截不是存储当前时间的时间截,而是存储时间截的差值(当前时间截 - 开始时间截)
* 得到的值),这里的的开始时间截,一般是我们的id生成器开始使用的时间,由我们程序来指定的(如下下面程序IdWorker类的startTime属性)。41位的时间截,可以使用69年,年T = (1L << 41) / (1000L * 60 * 60 * 24 * 365) = 69<br>
* 10位的数据机器位,可以部署在1024个节点,包括5位datacenterId和5位workerId<br>
* 12位序列,毫秒内的计数,12位的计数顺序号支持每个节点每毫秒(同一机器,同一时间截)产生4096个ID序号<br>
* 加起来刚好64位,为一个Long型。<br>
* SnowFlake的优点是,整体上按照时间自增排序,并且整个分布式系统内不会产生ID碰撞(由数据中心ID和机器ID作区分),并且效率较高,经测试,SnowFlake每秒能够产生26万ID左右。
*/
public class SnowflakeIdWorker {
// ==============================Fields===========================================
/** 开始时间截 (2015-01-01) */
private final long twepoch = 1420041600000L;
/** 机器id所占的位数 */
private final long workerIdBits = 5L;
/** 数据标识id所占的位数 */
private final long datacenterIdBits = 5L;
/** 支持的最大机器id,结果是31 (这个移位算法可以很快的计算出几位二进制数所能表示的最大十进制数) */
private final long maxWorkerId = -1L ^ (-1L << workerIdBits);
/** 支持的最大数据标识id,结果是31 */
private final long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
/** 序列在id中占的位数 */
private final long sequenceBits = 12L;
/** 机器ID向左移12位 */
private final long workerIdShift = sequenceBits;
/** 数据标识id向左移17位(12+5) */
private final long datacenterIdShift = sequenceBits + workerIdBits;
/** 时间截向左移22位(5+5+12) */
private final long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
/** 生成序列的掩码,这里为4095 (0b111111111111=0xfff=4095) */
private final long sequenceMask = -1L ^ (-1L << sequenceBits);
/** 工作机器ID(0~31) */
private long workerId;
/** 数据中心ID(0~31) */
private long datacenterId;
/** 毫秒内序列(0~4095) */
private long sequence = 0L;
/** 上次生成ID的时间截 */
private long lastTimestamp = -1L;
//==============================Constructors=====================================
/**
* 构造函数
* @param workerId 工作ID (0~31)
* @param datacenterId 数据中心ID (0~31)
*/
public SnowflakeIdWorker(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException(String.format("worker Id can‘t be greater than %d or less than 0", maxWorkerId));
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException(String.format("datacenter Id can‘t be greater than %d or less than 0", maxDatacenterId));
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
// ==============================Methods==========================================
/**
* 获得下一个ID (该方法是线程安全的)
* @return SnowflakeId
*/
public synchronized long nextId() {
long timestamp = timeGen();
//如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过这个时候应当抛出异常
if (timestamp < lastTimestamp) {
throw new RuntimeException(
String.format("Clock moved backwards. Refusing to generate id for %d milliseconds", lastTimestamp - timestamp));
}
//如果是同一时间生成的,则进行毫秒内序列
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
//毫秒内序列溢出
if (sequence == 0) {
//阻塞到下一个毫秒,获得新的时间戳
timestamp = tilNextMillis(lastTimestamp);
}
}
//时间戳改变,毫秒内序列重置
else {
sequence = 0L;
}
//上次生成ID的时间截
lastTimestamp = timestamp;
//移位并通过或运算拼到一起组成64位的ID
return ((timestamp - twepoch) << timestampLeftShift) //
| (datacenterId << datacenterIdShift) //
| (workerId << workerIdShift) //
| sequence;
}
/**
* 阻塞到下一个毫秒,直到获得新的时间戳
* @param lastTimestamp 上次生成ID的时间截
* @return 当前时间戳
*/
protected long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
/**
* 返回以毫秒为单位的当前时间
* @return 当前时间(毫秒)
*/
protected long timeGen() {
return System.currentTimeMillis();
}
//==============================Test=============================================
/** 测试 */
public static void main(String[] args) {
SnowflakeIdWorker idWorker = new SnowflakeIdWorker(0, 0);
for (int i = 0; i < 1000; i++) {
long id = idWorker.nextId();
System.out.println(Long.toBinaryString(id));
System.out.println(id);
}
}
}
