字典树
Posted bhd123
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了字典树相关的知识,希望对你有一定的参考价值。
以下为自己个人学习字典树的一些总结(不一定对,初学)
字典树用一张图就可以看懂他的作用:
单词列表为”apps”,”apply”,”apple”,”append”,”back”,”backen”以及”basic”对应的字母树可以是如下图所示。
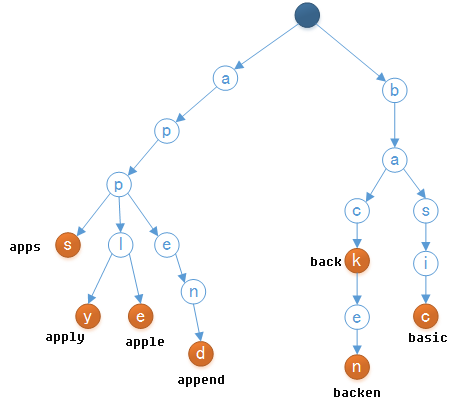
定义一个结构体:
typedef struct Tire_node
{
int cnt; //记录该前缀出现了几次
struct Tire_node* next[26];//视情况而定,一个字母下的其他分支
} Tirenode,*Tire;
cnt 存这个结点的经过次数,比如a这个点(第二层,apple的开头的a),这个点后面有一个分支(因为这些点的后面都跟得是p)。
为什么next这个数组的大小是26呢?
因为我们写的这个函数的作用是查单词出现没有,单词如果只是大写或者小写,只有26.
下面附一个初学的题:
use MathJax to parse formulas
Description
A prefix of a string is a substring starting at the beginning of the given string. The prefixes of "carbon" are: "c", "ca", "car", "carb", "carbo", and "carbon". Note that the empty string is not considered a prefix in this problem, but every non-empty string is considered to be a prefix of itself. In everyday language, we tend to abbreviate words by prefixes. For example, "carbohydrate" is commonly abbreviated by "carb". In this problem, given a set of words, you will find for each word the shortest prefix that uniquely identifies the word it represents.
In the sample input below, "carbohydrate" can be abbreviated to "carboh", but it cannot be abbreviated to "carbo" (or anything shorter) because there are other words in the list that begin with "carbo".
An exact match will override a prefix match. For example, the prefix "car" matches the given word "car" exactly. Therefore, it is understood without ambiguity that "car" is an abbreviation for "car" , not for "carriage" or any of the other words in the list that begins with "car".
In the sample input below, "carbohydrate" can be abbreviated to "carboh", but it cannot be abbreviated to "carbo" (or anything shorter) because there are other words in the list that begin with "carbo".
An exact match will override a prefix match. For example, the prefix "car" matches the given word "car" exactly. Therefore, it is understood without ambiguity that "car" is an abbreviation for "car" , not for "carriage" or any of the other words in the list that begins with "car".
Input
The input contains at least two, but no more than 1000 lines. Each line contains one word consisting of 1 to 20 lower case letters.
Output
The output contains the same number of lines as the input. Each line of the output contains the word from the corresponding line of the input, followed by one blank space, and the shortest prefix that uniquely (without ambiguity) identifies this word.
Sample Input
carbohydrate cart carburetor caramel caribou carbonic cartilage carbon carriage carton car carbonate
Sample Output
carbohydrate carboh cart cart carburetor carbu caramel cara caribou cari carbonic carboni cartilage carti carbon carbon carriage carr carton carto car car carbonate carbona
#include <iostream> #include <cstdio> #include <cstring> #include <cmath> #include <map> #include <cstdlib> #include <algorithm> #include <queue> #include <stack> #define ll long long #define INF 0x3f3f3f3f #define PI acos(-1) const int MAX=1e5+10; using namespace std; typedef struct Tire_node { int cnt; //记录该前缀出现了几次 struct Tire_node* next[26];//视情况而定,一个字母下的其他分支 } Tirenode,*Tire; char s[1005][25]; Tire CreatTirenode() { Tire node=(Tire)malloc(sizeof(Tirenode)); node->cnt=0; memset(node->next,0,sizeof(node->next)); return node; } void Tire_insert(Tire root,int k) { int i; Tire node=root; int len=strlen(s[k]); for(i=0;i<=len-1;i++) { int a=s[k][i]-‘a‘; if(node->next[a]==NULL) node->next[a]=CreatTirenode(); node=node->next[a]; node->cnt++; } } void Tire_search(Tire root,int k) { Tire node=root; int i; int len=strlen(s[k]); for(i=0;i<=len-1;i++) { int a=s[k][i]-‘a‘; node=node->next[a]; if(node->cnt==1) { printf("%c",a+‘a‘); return ; } else { printf("%c",a+‘a‘); } } } int main() { Tire root=CreatTirenode(); int i=0; while(scanf("%s",s[i])!=EOF) { Tire_insert(root,i); i++; } for(int j=0; j<=i; j++) { printf("%s ",s[j]); Tire_search(root,j); printf(" "); } return 0; }
构造字典树以及查询操作如下:
代码如下:
以上是关于字典树的主要内容,如果未能解决你的问题,请参考以下文章