数据挖掘概念杂记
Posted zhxuxu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据挖掘概念杂记相关的知识,希望对你有一定的参考价值。
混淆矩阵

利用混淆矩阵可更好的分辨出分类中分错误的。

1. 数据集中的记录总数=TP+FP+FN+TN
2. 数据集中肯定记录数=TP+FN
3. 数据集中否定记录数=FP+TN
4. 分类模型作出阳性判断的记录数=TP+FP
5. 分类模型作出阴性判断的记录数=FN+TN
6. 分类模型作出正确分类的记录数=TP+TN
7. 分类模型作出错误分类的记录数=FP+FN
表1中给出的二元分类问题混淆矩阵结构可以很容易地推广到多元分类问题。对于存在n 个类别的分类问题,混淆矩阵是个n ×n的情形分析表,每一列对应一个真实的类别,而每一行对应分类模型判断的一个类别 (混淆矩阵的行和列互换没有实质影响)。
正确率
预测正确的比率
TP/(TP+FP)
召回率
预测为正的真实正例占所有正例的比例
TP/(TP+FN)
AUC
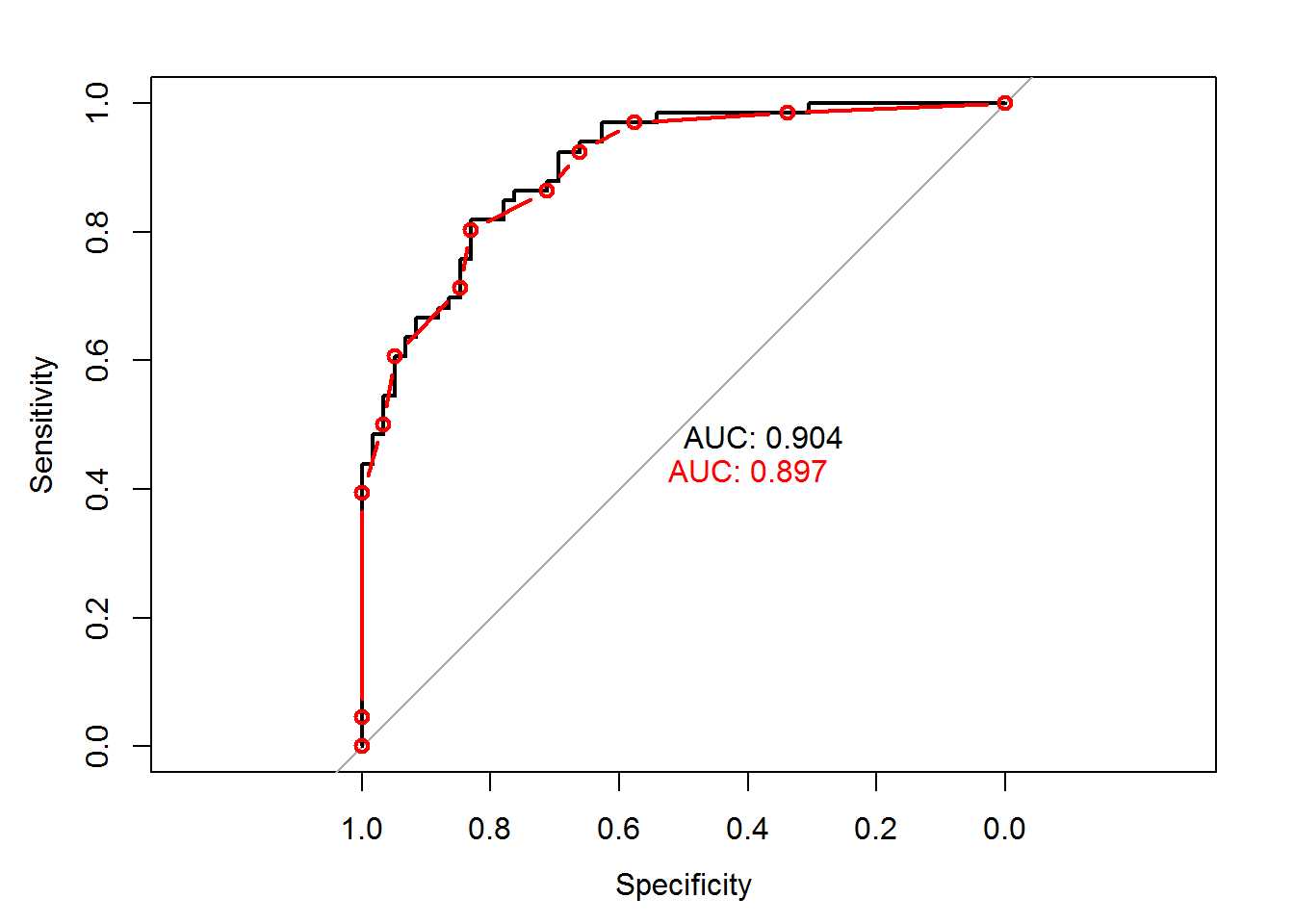
是指召回率曲线的以下的面积,AUC给出分类器的平均性能,一个完美的分类器AUC为1,随机猜测AUC是0.5
随机森林
随机森林顾名思义,是用随机的方式建立一个森林,森林里面有很多的决策树组成,随机森林的每一棵决策树之间是没有关联的。
下面是随机森林的构造过程:
1. 假如有N个样本,则有放回的随机选择N个样本(每次随机选择一个样本,然后返回继续选择)。这选择好了的N个样本用来训练一个决策树,作为决策树根节点处的样本。
2. 当每个样本有M个属性时,在决策树的每个节点需要分裂时,随机从这M个属性中选取出m个属性,满足条件m << M。然后从这m个属性中采用某种策略(比如说信息增益)来选择1个属性作为该节点的分裂属性。
3. 决策树形成过程中每个节点都要按照步骤2来分裂(很容易理解,如果下一次该节点选出来的那一个属性是刚刚其父节点分裂时用过的属性,则该节点已经达到了叶子节点,无须继续分裂了)。一直到不能够再分裂为止。注意整个决策树形成过程中没有进行剪枝。
4. 按照步骤1~3建立大量的决策树,这样就构成了随机森林了。
随机化有助于减少决策树之间的相关性,从而改善组合分类器的泛化误差。
让每一颗数完全的增长不进行剪枝,这可能有助于减少结果数的偏移。
可以使用多数表决权来组合预测结果。
随机森林的准确性可以与Adaboost相媲美,而且要比Adaboost的运行速度快。
互信息
互信息,Mutual Information,缩写为MI,表示两个变量X与Y是否有关系,以及关系的强弱。
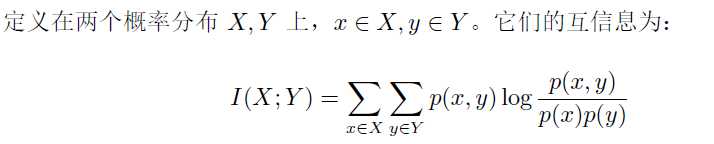
直观上,互信息度量 X 和 Y 共享的信息:它度量知道这两个变量其中一个,对另一个不确定度减少的程度。例如,如果 X 和 Y 相互独立,则知道 X 不对 Y 提供任何信息,反之亦然,所以它们的互信息为零。在另一个极端,如果 X 是 Y 的一个确定性函数,且 Y 也是 X 的一个确定性函数,那么传递的所有信息被 X 和 Y 共享:知道 X 决定 Y 的值,反之亦然。因此,在此情形互信息与 Y(或 X)单独包含的不确定度相同,称作 Y(或 X)的熵。而且,这个互信息与 X 的熵和 Y 的熵相同。(这种情形的一个非常特殊的情况是当 X 和 Y 为相同随机变量时。)
互信息是 X 和 Y 联合分布相对于假定 X 和 Y 独立情况下的联合分布之间的内在依赖性。于是互信息以下面方式度量依赖性:I(X; Y) = 0 当且仅当 X 和 Y 为独立随机变量。
此外,互信息是非负的(即 I(X;Y) ≥ 0; 见下文),而且是对称的(即 I(X;Y) = I(Y;X))
多任务学习
多任务学习(Multitask Learning)是一种推导迁移学习方法,主任务(main tasks)使用相关任务(related tasks)的训练信号(training signal)所拥有的领域相关信息(domain-specific information),做为一直推导偏差(inductive bias)来提升主任务(main tasks)泛化效果(generalization performance)的一种机器学习方法。多任务学习涉及多个相关的任务同时并行学习,梯度同时反向传播,多个任务通过底层的共享表示(shared representation)来互相帮助学习,提升泛化效果。简单来说:多任务学习把多个相关的任务放在一起学习(注意,一定要是相关的任务,后面会给出相关任务(related tasks)的定义,以及他们共享了那些信息),学习过程(training)中通过一个在浅层的共享(shared representation)表示来互相分享、互相补充学习到的领域相关的信息(domain information),互相促进学习,提升泛化的效果。
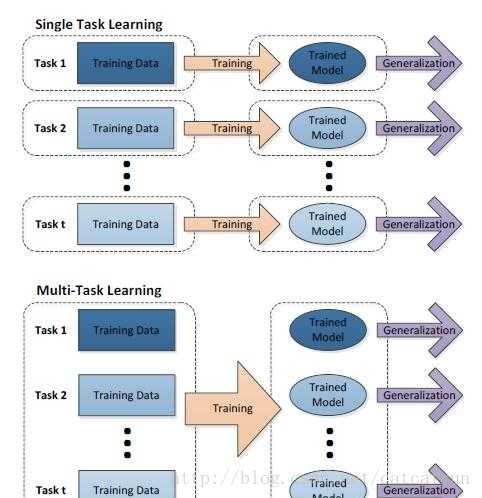
(1) 多人相关任务放在一起学习,有相关的部分,但也有不相关的部分。当学习一个任务(Main task)时,与该任务不相关的部分,在学习过程中相当于是噪声,因此,引入噪声可以提高学习的泛化(generalization)效果。
(2) 单任务学习时,梯度的反向传播倾向于陷入局部极小值。多任务学习中不同任务的局部极小值处于不同的位置,通过相互作用,可以帮助隐含层逃离局部极小值。
(3) 添加的任务可以改变权值更新的动态特性,可能使网络更适合多任务学习。比如,多任务并行学习,提升了浅层共享层(shared representation)的学习速率,可能,较大的学习速率提升了学习效果。
(4) 多个任务在浅层共享表示,可能削弱了网络的能力,降低网络过拟合,提升了泛化效果。
计算数据混乱度的方式
1 熵
2 方差
首先计算数据的均值,然后捐每条数据到均值的差值,为了对正负差值同等看待,一般使用绝对值或平方替代,方差是平方误差的均值(均方差)。
以上是关于数据挖掘概念杂记的主要内容,如果未能解决你的问题,请参考以下文章