20172327 2018-2019-1 《程序设计与数据结构》第九周学习总结
Posted mrf1209
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了20172327 2018-2019-1 《程序设计与数据结构》第九周学习总结相关的知识,希望对你有一定的参考价值。
20172327 2018-2019-1 《程序设计与数据结构》第九周学习总结
教材学习内容总结
第十五章 图
无向图
1.图的概念(非线性结构):允许树中每个结点与多个结点相连,不分父子结点。
2.图由顶点和边组成。
顶点由名字或标号来表示,如:A、B、C、D;
边由连接的定点对来表示,如:(A,B),(C,D),表示两顶点之间有一条边。
3.无向图:顶点之间无序连接。
如:边(A,B)意味着A与B之间的连接是双向的,与(B,A)的含义一样。
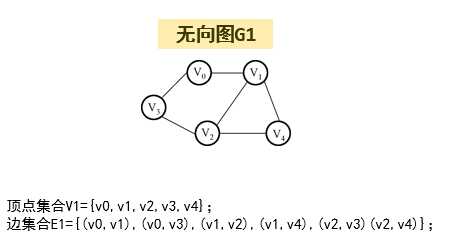
4.邻接(邻居):两个顶点之间有边连接。
5.自循环(悬挂):自己连接到自己的边。
6.完全图:含有最多条边的无向图。例如:
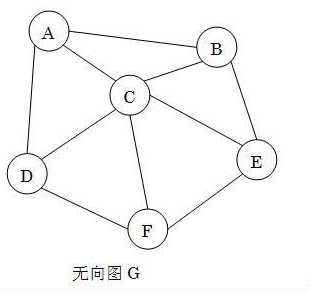
无向图G是一个完全图。
7.路径:连接图中两个顶点的边的序列,可以由多条边组成。
<无向图中的路径是双向的。
8.路径长度:路径中所含边的数目(顶点个数减1)。
9.联通图:无向图中任意两个顶点间都有路径。例如:
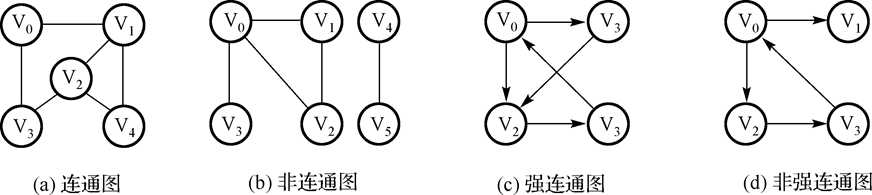
完全图一定是连通图,连通图不一定是完全图。
10.环(回路):第一个顶点与最后一个顶点相同且没有重复边的路径。例如:
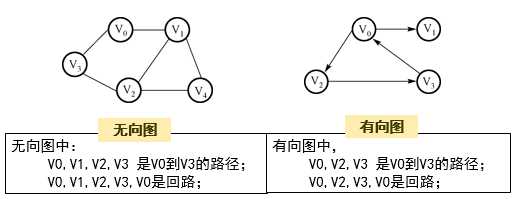
11.无环图:没有环的图。
12.子图:类似集合中“子集”的概念,示例如下:
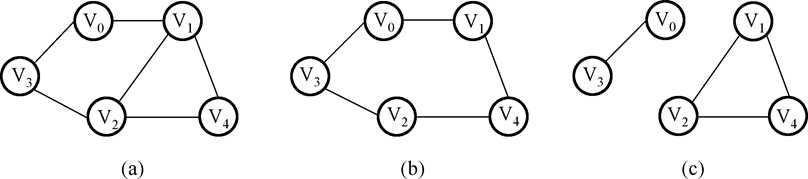
其中,(b),(c)是(a)的子图。
13.生成树:包含无向图G1所有顶点的极小连通子图称为G1的生成树。例如:
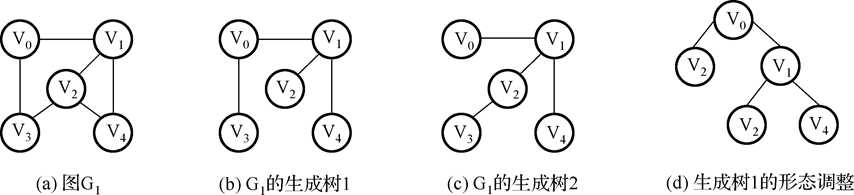
14.稀疏图与稠密图:有很少条边或弧(如e<nlogn,n是图的顶点数,e是弧数)的图称为稀疏图,反之称为稠密图。
有向图
1.有向图:顶点之间有序连接,边是顶点的有序对。
边(A,B)和(B,A)方向不同。
2.有向路径:连接两个顶点有向边的序列。
有向图中的有序对常用序偶表示,例如:
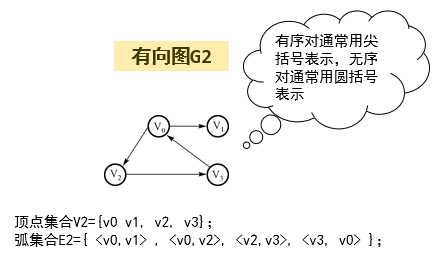
上图中路径 V0→V2→V3是从V0到V3的路径,但反过来不再成立。
注意联通有向图与无向图不同,有向边决定连通性。例如:
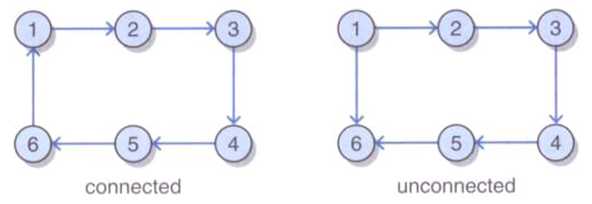
上图中左图为联通图,右图不联通,因为从任何顶点到顶点1都没有路径。
3.有向树是一个有向图,其中指定一个元素为根,则具有下列特性:
任何顶点到根都没有连接。
到达每个非根元素的连接都只有一个。
从根到每个顶点都有路径。
顶点的度、出度、入度:

带权图
1.带权图(网络):每条边都对应一个权值(数据信息)的图。(城市之间的航线、票价等)
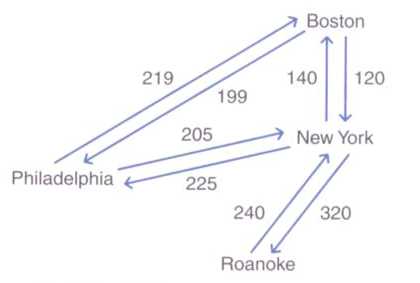
带权图可以是无向的也可以是有向的。
2.带权图的边:由起始点、结束点和权构成。
有向图的每条边必须使用三元组表示。
常用的图算法
1.图的遍历:
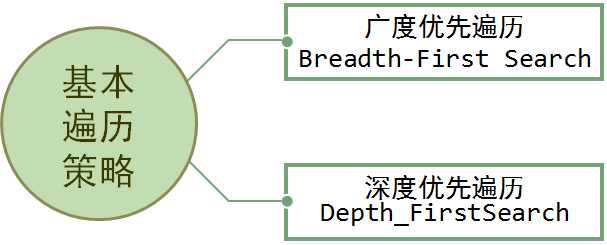
2.广度优先遍历:从一个顶点开始,辐射状地优先遍历其周围较广的区域。
3.深度优先遍历:图的深度优先搜索,类似于树的先序遍历,所遵循的搜索策略是尽可能“深”地搜索图。
4.连通性:从任意结点开始的广度优先遍历中得到的顶点数等于图中所含顶点数。
生成树:包含图中所有顶点及图中部分边的一棵树。
5.最小生成树:所含边权值之和小于其他生成树的边的权值之和。
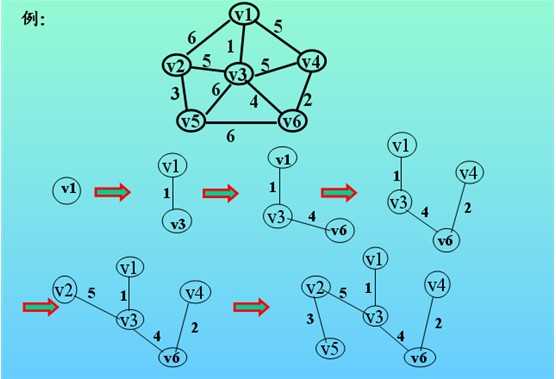
判定最短路径:
判定起始顶点和目标顶点之间是否存在最短路径(两个顶点之间边数最少的路径)。
在带权图中找到最短路径。(Dijkstra算法)
图的实现策略:
1.邻接矩阵:
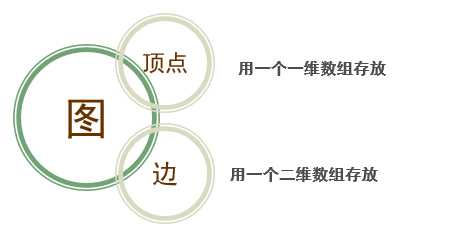

2.无向图邻接矩阵:
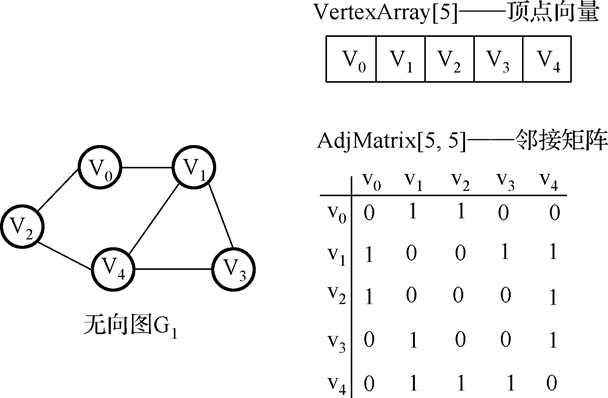
特点:对称,可压缩存储。顶点 vi 的度是邻接矩阵中第 i 行 1 的个数。
3.有向图邻接矩阵:
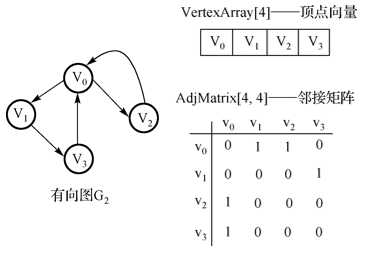
特点:不一定对称。顶点 vi 的出度是邻接矩阵中第 i 行 1 的个数。顶点 vi 的入度是邻接矩阵中第 i 列 1 的个数。
4.网的邻接矩阵:
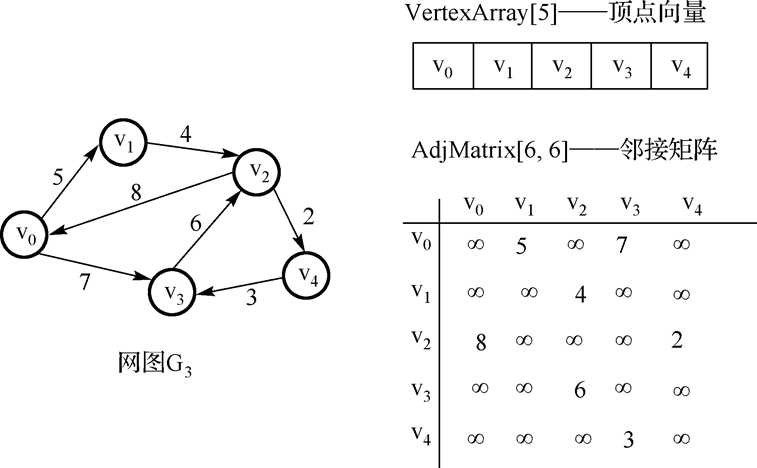
采用邻接矩阵表示图,优点:直观方便,运算简单。
时间复杂度:边查找O(1);顶点度计算O(n)。
空间复杂度:O(n^2)(尽量不要用来表示稀疏图)。
5.边集数组:
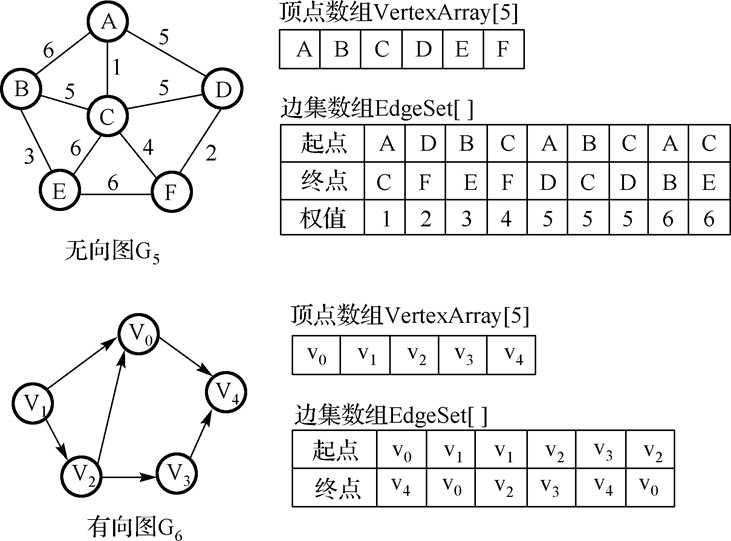
在边集数组中查找一条边或一个顶点的度都需要扫描整个数组,所以其时间复杂性为O(e)。
边集数组适合那些对边依次进行处理的运算,不适合对顶点的运算和对任一条边的运算。
边集数组表示通常包括一个 边集数组和一个顶点数组,所以其空间复杂性为O(n+e)。
从空间复杂性上讲, 边集数组也适合表示稀疏图。
6.无向图邻接表:
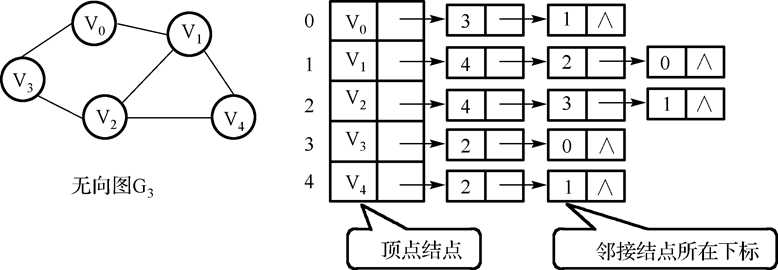
特点:若无向图中有 n 个顶点、e 条边,则其邻接表需 n 个头结点和 2e 个表结点。适宜存储稀疏图。
无向图中顶点 vi 的度为第 i 个单链表中的结点数。
7.有向图邻接表:
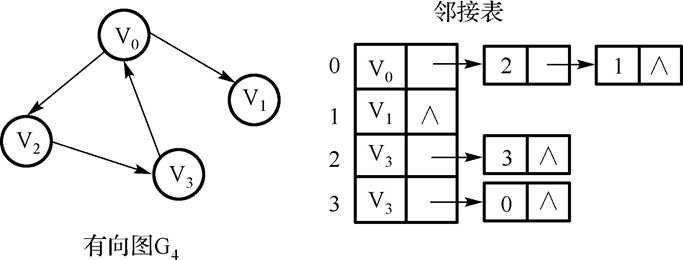
特点:顶点 vi 的出度为第 i 个单链表中的结点个数。
顶点 vi 的入度为整个单链表中邻接点域值是 i -1 的结点个数。
找出度易,找入度难。
8.逆邻接表:
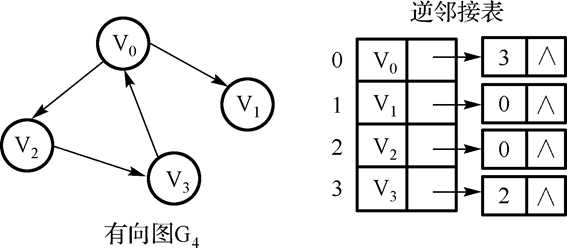
特点:顶点 vi 的入度为第 i 个单链表中的结点个数。
顶点 vi 的出度为整个单链表中邻接点域值是 i -1 的结点个数。
找入度易,找出度难。
9.带权邻接表:
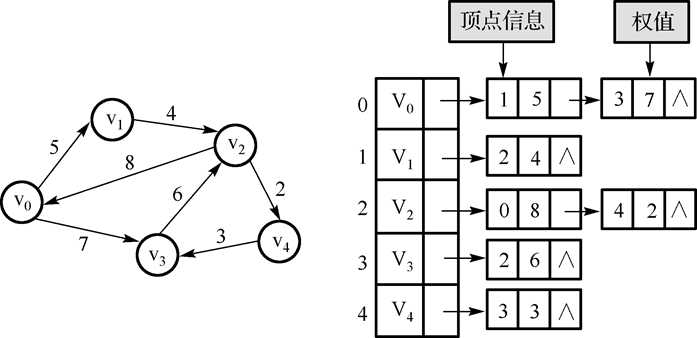
邻接表用于表示稀疏图比较节省存储空间,因为只需要很少的边结点,若用于表示稠密图,则将占用较多的存储空间,同时也将增加顶点的查找结点时间。
10.十字链表:
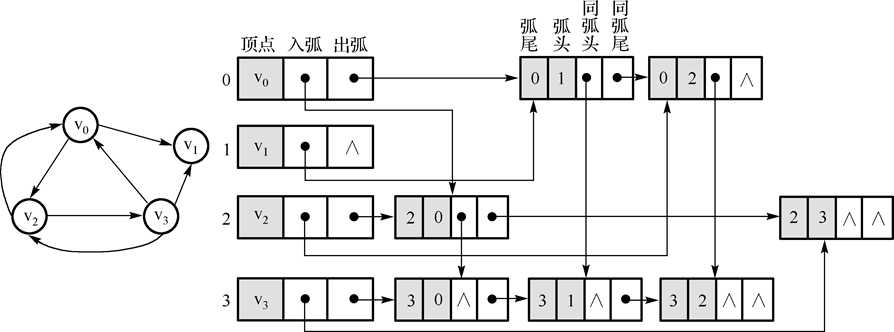
十字链表除了结构复杂一点外,其创建图的时间复杂度是和邻接表相同的,用十字链表来存储稀疏有向图,可以达到高效存取的效果。
11.邻接多重表:
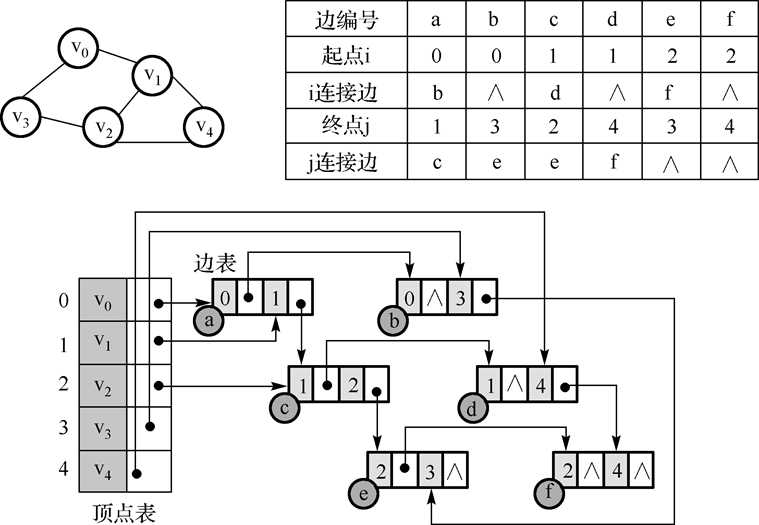
邻接多重表容易操作,如求顶点的度等。建立邻接多重表的空间复杂度与时间复杂度都与邻接表相同。
图的存储结构归结比较:
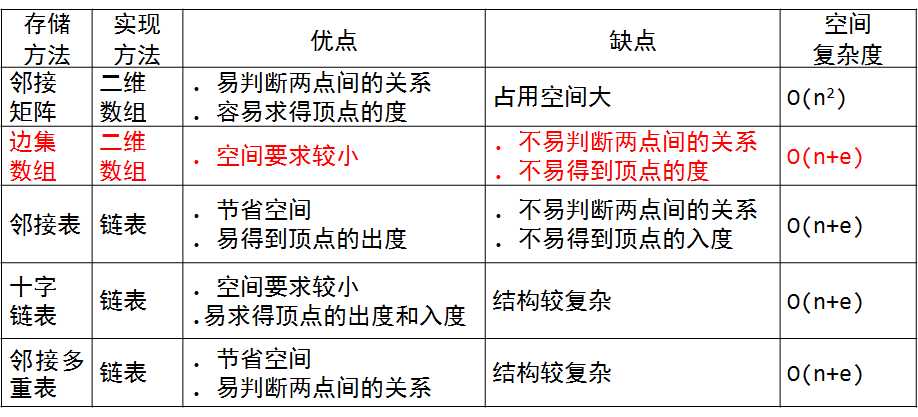
教材学习中的问题和解决过程
- 问题1:对于堆排序的详细步骤(具体顺序)不清楚,教材上也只提供了思路。
- 解决方案:
【步骤一】构造初始堆,以大顶堆为例,给无序序列构造一个大顶堆,假设无序序列如下:
图三
从最后一个非叶子结点开始(叶结点不用调整,第一个非叶子结点 arr.length/2-1=5/2-1=1,也就是下面的6结点),从左至右,从下至上进行调整:
图四
找到第二歌非页结点4,由于[4、9、8]中9最大,4和9交换/
图五
这时,交换导致了子根[4,5,6]结构混乱,继续调整,[4,5,6]中6最大,交换4和6。
图六
这样大顶堆就完成了。
【步骤二】将堆顶元素与末尾元素进行交换,使末尾元素最大。然后继续调整堆,再将堆顶元素与末尾元素交换,得到第二大元素。首先将堆顶元素9和末尾元素4进行交换:
图七
重新调整结构,使其继续满足堆定义:
图八
再将堆顶元素8与末尾元素5进行交换,得到第二大元素8:
图九
【步骤三】如此反复进行交换、重建、交换。反复进行此过程,便可得到有序序列:
图十
所以,基本步骤概括为:将无序堆构建成大顶堆或小顶堆,再通过反复交换堆顶元素和当前末尾元素并调整,最后使整个序列有序。
代码调试中的问题和解决过程
- 问题1:在实现ArrayOrderedListTest测试时,我遇到了显示最后一个数字时,人家显示为null这个问题。
图片 - 解决分析,在我对前面ArrayList类检查时,发现我在显示last时,将rear-1不小心写成rear了,所以它所读取的是最后一个后边的,所以肯定为空。
上周考试错题总结
- 错题1.In removing an element from a binary search tree, another node must be ___________ to replace the node being removed.
A .duplicated
B .demoted
C .promoted
D .None of the above 分析:在从二叉查找树中删除元素时, 另一个节点必须促进以替换要删除的节点。
- 错题2.The leftmost node in a binary search tree will contain the __________ element, while the rightmost node will contain the __________ element.
A .Maximum, minimum
B .Minimum, maximum
C .Minimum, middle
D .None of the above 分析:二叉查找树中最左边的节点将包含最小元素, 而最右边的节点将包含最大元素。
- 错题3.One of the uses of trees is to provide _________ implementations of other collections.
A .efficient
B .easy
C .useful
D .None of the above 分析:树的用途之一是提供其他集合的高效的实现。
- 错题4.The leftmost node in a binary search tree will contain the minimum element, while the rightmost node will contain the maximum element.
A .True
B .Flase 分析:同错题2。
- 错题5.One of the uses of trees is to provide simpler implementations of other collections.
A .True
B .Flase 分析:同错题3.
- 错题6.What type does "compareTo" return?
A .int
B .String
C .boolean
D .char 分析:compareTo返回的是-1,0,1。所以为int值
- 错题7.Bubble, Selection and Insertion sort all have time complexity of O(n).
A .true
B .false
分析:气泡和插入排序都具有 o (n) 的时间复杂度,但选择排序最好情况为O(n^2)。
A .true
B .false
分析:插入排序在实现上,通常采用in-place排序(即只需用到O(1)的额外空间的排序),因而在从后向前扫描过程中,需要反复把已排序元素逐步向后挪位,为最新元素提供插入空间。
代码托管
结对及互评
正确使用Markdown语法(加1分)
模板中的要素齐全(加1分)
教材学习中的问题和解决过程, (加3分)
代码调试中的问题和解决过程, 无问题
感想,体会真切的(加1分)
点评认真,能指出博客和代码中的问题的(加1分)
- 20172317
基于评分标准,我给以上博客打分:4分。得分情况如下: 20172320
基于评分标准,我给以上博客打分:8分。得分情况如下:- 结对学习内容
- 教材第12章,运行教材上的代码
- 完成课后自测题,并参考答案学习
- 完成程序设计项目:至少完成PP12.1、PP12.8、PP12.9
- 结对学习内容
其他(感悟、思考等,可选)
这周学的有点麻烦,栈还行,就是链表有点糊涂。
学习进度条
| 代码行数(新增/累积) | 博客量(新增/累积) | 学习时间(新增/累积) | 重要成长 | |
|---|---|---|---|---|
| 目标 | 5000行 | 30篇 | 400小时 | |
| 第一周 | 0/0 | 1/1 | 8/8 | |
| 第二周 | 1306/1306 | 1/2 | 20/28 | |
| 第三周 | 1291/2597 | 1/3 | 18/46 | |
| 第四周 | 4361/6958 | 2/3 | 20/66 | |
| 第五周 | 1755/8713 | 1/6 | 20/86 | |
| 第六周 | 3349/12062 | 1/7 | 20/106 |
计划学习时间:10小时
实际学习时间:8小时
改进情况:
(有空多看看现代软件工程 课件
软件工程师能力自我评价表)
参考资料
以上是关于20172327 2018-2019-1 《程序设计与数据结构》第九周学习总结的主要内容,如果未能解决你的问题,请参考以下文章