自己训练卷积模型实现猫狗
Posted nxf-rabbit75
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自己训练卷积模型实现猫狗相关的知识,希望对你有一定的参考价值。
原数据集:包含 25000张猫狗图像,两个类别各有12500
新数据集:猫、狗 (照片大小不一样)
- 训练集:各1000个样本
- 验证集:各500个样本
- 测试集:各500个样本
# 将图像复制到训练、验证和测试的目录 import os,shutil orginal_dataset_dir = ‘kaggle_original_data/train‘ base_dir = ‘cats_and_dogs_small‘ os.mkdir(base_dir)#保存新数据集的目录 train_dir = os.path.join(base_dir,‘train‘) os.mkdir(train_dir) validation_dir = os.path.join(base_dir,‘validation‘) os.mkdir(validation_dir) test_dir = os.path.join(base_dir,‘test‘) os.mkdir(test_dir) #猫、狗的训练图像目录 train_cats_dir = os.path.join(train_dir,‘cats‘) os.mkdir(train_cats_dir) train_dogs_dir = os.path.join(train_dir,‘dogs‘) os.mkdir(train_dogs_dir) #猫、狗的验证图像目录 validation_cats_dir = os.path.join(validation_dir,‘cats‘) os.mkdir(validation_cats_dir) validation_dogs_dir = os.path.join(validation_dir,‘dogs‘) os.mkdir(validation_dogs_dir) #猫、狗的测试图像目录 test_cats_dir = os.path.join(test_dir,‘cats‘) os.mkdir(test_cats_dir) test_dogs_dir = os.path.join(test_dir,‘dogs‘) os.mkdir(test_dogs_dir) #将前1000张猫的图像复制到train_cats_dir fnames = [‘cat.{}.jpg‘.format(i) for i in range(1000)] for fname in fnames: src = os.path.join(orginal_dataset_dir,fname) dst = os.path.join(train_cats_dir,fname) shutil.copyfile(src,dst) #将接下来500张猫的图像复制到validation_cats_dir fnames = [‘cat.{}.jpg‘.format(i) for i in range(1000,1500)] for fname in fnames: src = os.path.join(orginal_dataset_dir,fname) dst = os.path.join(validation_cats_dir,fname) shutil.copyfile(src,dst) #将接下来的500张猫的图像复制到test_cats_dir fnames = [‘cat.{}.jpg‘.format(i) for i in range(1500,2000)] for fname in fnames: src = os.path.join(orginal_dataset_dir,fname) dst = os.path.join(test_cats_dir,fname) shutil.copyfile(src,dst) #将前1000张狗的图像复制到train_dogs_dir fnames = [‘dog.{}.jpg‘.format(i) for i in range(1000)] for fname in fnames: src = os.path.join(orginal_dataset_dir,fname) dst = os.path.join(train_dogs_dir,fname) shutil.copyfile(src,dst) #将接下来500张狗的图像复制到validation_dogs_dir fnames = [‘dog.{}.jpg‘.format(i) for i in range(1000,1500)] for fname in fnames: src = os.path.join(orginal_dataset_dir,fname) dst = os.path.join(validation_dogs_dir,fname) shutil.copyfile(src,dst) #将接下来的500张狗的图像复制到test_cats_dir fnames = [‘dog.{}.jpg‘.format(i) for i in range(1500,2000)] for fname in fnames: src = os.path.join(orginal_dataset_dir,fname) dst = os.path.join(test_dogs_dir,fname) shutil.copyfile(src,dst) |

|
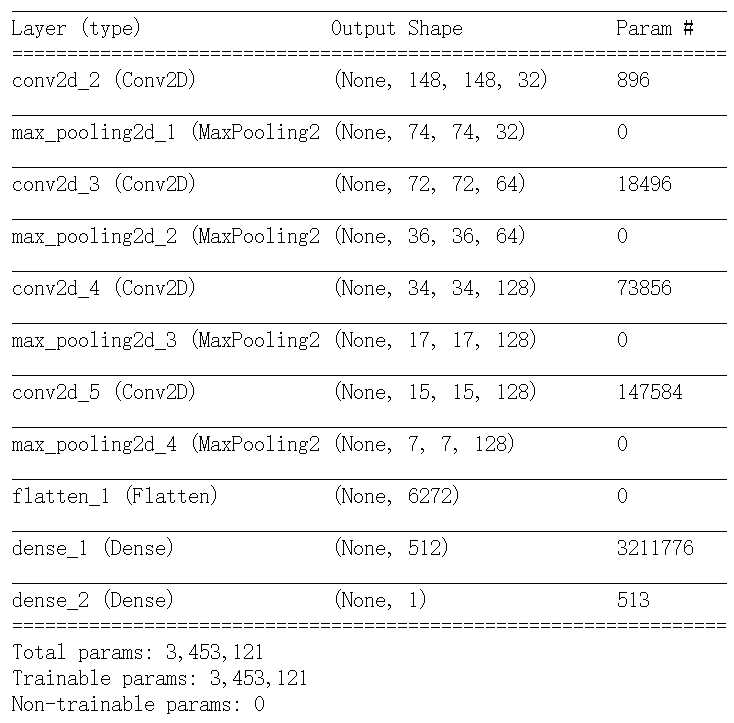
#将猫狗分类的小型卷积神经网络实例化 from keras import layers from keras import models model = models.Sequential() model.add(layers.Conv2D(32,(3,3),activation=‘relu‘,input_shape=(150,150,3))) model.add(layers.MaxPool2D((2,2))) model.add(layers.Conv2D(64,(3,3),activation=‘relu‘)) model.add(layers.MaxPool2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation=‘relu‘)) model.add(layers.MaxPool2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation=‘relu‘)) model.add(layers.MaxPool2D((2,2))) model.add(layers.Flatten()) model.add(layers.Dense(512,activation=‘relu‘)) model.add(layers.Dense(1,activation=‘sigmoid‘))
|
|
from keras import optimizers model.compile(loss=‘binary_crossentropy‘, optimizer = optimizers.RMSprop(lr=1e-4), metrics = [‘acc‘]) |
|
#使用ImageDataGenerator从目录中读取图像 #ImageDataGenerator可以快速创建Python生成器,能够将硬盘上的图像文件自动转换为预处理好的张量批量 from keras.preprocessing.image import ImageDataGenerator #将所有图像乘以1/255缩放 train_datagen = ImageDataGenerator(rescale = 1./255) test_datagen = ImageDataGenerator(rescale = 1./255) train_generator = train_datagen.flow_from_directory( train_dir, target_size = (150,150), batch_size = 20, class_mode = ‘binary‘ #因为使用了binary_crossentropy损失,所以需要用二进制标签 ) validation_generator = test_datagen.flow_from_directory( validation_dir, target_size = (150,150), batch_size = 20, class_mode = ‘binary‘ ) |

|
for data_batch,labels_batch in train_generator: print(‘data batch shape:‘,data_batch.shape) print(‘labels batch shape:‘,labels_batch.shape) break |
data batch shape: (20, 150, 150, 3)
labels batch shape: (20,)
|
#利用批量生成器拟合模型 history = model.fit_generator( train_generator, steps_per_epoch = 50, epochs = 30, validation_data = validation_generator, validation_steps = 50#需要从验证生成器中抽取50个批次用于评估 ) #保存模型 |
|
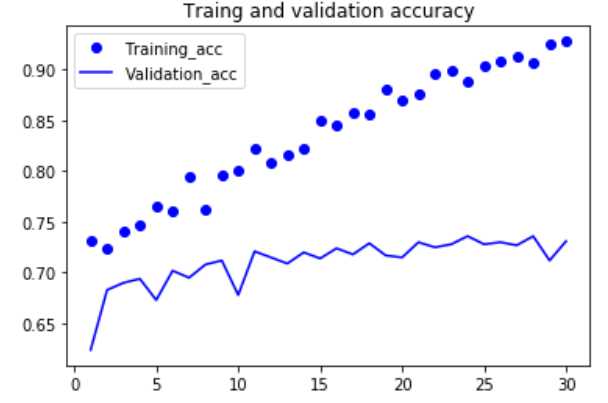
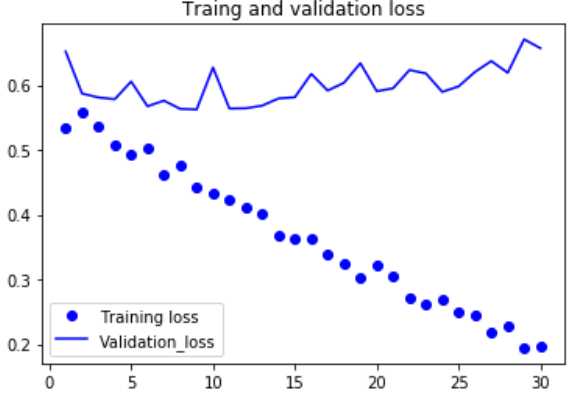
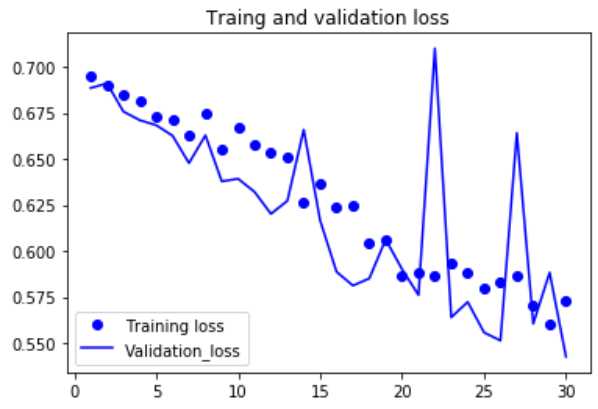
#绘制损失曲线和精度曲线 import matplotlib.pyplot as plt acc = history.history[‘acc‘] val_acc = history.history[‘val_acc‘] loss = history.history[‘loss‘] val_loss = history.history[‘val_loss‘] epochs = range(1,len(acc)+1) plt.plot(epochs,acc,‘bo‘,label=‘Training_acc‘) plt.plot(epochs,val_acc,‘b‘,label=‘Validation_acc‘) plt.title(‘Traing and validation accuracy‘) plt.legend() plt.figure() plt.plot(epochs,loss,‘bo‘,label=‘Training loss‘) plt.plot(epochs,val_loss,‘b‘,label=‘Validation_loss‘) plt.title(‘Traing and validation loss‘) plt.legend() plt.show() |
|
#因为数据样本较少,容易过拟合,因此我们使用数据增强来减少过拟合 #利用ImageDataGenerator来设置数据增强 datagen = ImageDataGenerator( rotation_range = 40, width_shift_range = 0.2, height_shift_range=0.2, shear_range=0.2, zoom_range = 0.2, horizontal_flip = True, fill_mode = ‘nearest‘ ) |
|
#显示几个随机增强后的训练图像 from keras.preprocessing import image fnames = [os.path.join(train_cats_dir,fname) for fname in os.listdir(train_cats_dir)] # [‘cats_and_dogs_small\\train\\cats\\cat.0.jpg‘,‘cats_and_dogs_small\\train\\cats\\cat.1.jpg‘,...] img_path = fnames[3]#选择一张图像进行增强 # ‘cats_and_dogs_small\\train\\cats\\cat.3.jpg‘ img = image.load_img(img_path,target_size=(150,150))#读取图像并调整大小 x = image.img_to_array(img) # ==> array(150,150,3) x = x.reshape((1,)+x.shape) # ==> array(1,150,150,3) i = 0 for batch in datagen.flow(x,batch_size=1): plt.figure(i) implot = plt.imshow(image.array_to_img(batch[0])) i += 1 if i % 1 == 0: break plt.show() |

|
#向模型中添加一个Dropout层,添加到密集连接分类器之前 model = models.Sequential() model.add(layers.Conv2D(32,(3,3),activation=‘relu‘,input_shape=(150,150,3))) model.add(layers.MaxPool2D((2,2))) model.add(layers.Conv2D(64,(3,3),activation=‘relu‘)) model.add(layers.MaxPool2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation=‘relu‘)) model.add(layers.MaxPool2D((2,2))) model.add(layers.Conv2D(128,(3,3),activation=‘relu‘)) model.add(layers.MaxPool2D((2,2))) model.add(layers.Flatten()) model.add(layers.Dropout(0.5)) model.add(layers.Dense(512,activation=‘relu‘)) model.add(layers.Dense(1,activation=‘sigmoid‘)) model.compile(loss=‘binary_crossentropy‘, optimizer = optimizers.RMSprop(lr=1e-4), metrics = [‘acc‘]) |
|
#利用数据增强生成器训练卷积神经网络 train_datagen = ImageDataGenerator( rescale = 1./255, rotation_range = 40, width_shift_range = 0.2, height_shift_range = 0.2, shear_range = 0.2, zoom_range = 0.2, horizontal_flip = True, ) test_datagen = ImageDataGenerator(rescale = 1./255) train_generator = train_datagen.flow_from_directory( train_dir, target_size = (150,150), batch_size = 20, class_mode = ‘binary‘ #因为使用了binary_crossentropy损失,所以需要用二进制标签 ) validation_generator = test_datagen.flow_from_directory( validation_dir, target_size = (150,150), batch_size = 20, class_mode = ‘binary‘ ) history = model.fit_generator( train_generator, steps_per_epoch = 50, epochs = 30, validation_data = validation_generator, validation_steps = 50#需要从验证生成器中抽取50个批次用于评估 ) model.save(‘cats_and_dogs_small_2.h5‘) |
|
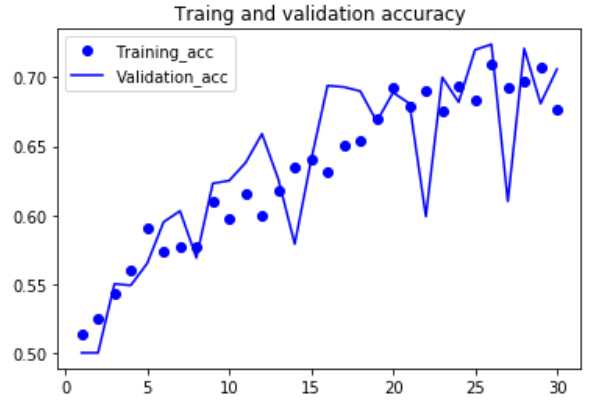
#绘制损失曲线和精度曲线 import matplotlib.pyplot as plt acc = history.history[‘acc‘] val_acc = history.history[‘val_acc‘] loss = history.history[‘loss‘] val_loss = history.history[‘val_loss‘] epochs = range(1,len(acc)+1) plt.plot(epochs,acc,‘bo‘,label=‘Training_acc‘) plt.plot(epochs,val_acc,‘b‘,label=‘Validation_acc‘) plt.title(‘Traing and validation accuracy‘) plt.legend() plt.figure() plt.plot(epochs,loss,‘bo‘,label=‘Training loss‘) plt.plot(epochs,val_loss,‘b‘,label=‘Validation_loss‘) plt.title(‘Traing and validation loss‘) plt.legend() plt.show()
|
|
以上是关于自己训练卷积模型实现猫狗的主要内容,如果未能解决你的问题,请参考以下文章