部署Ceph集群--jluocc
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了部署Ceph集群--jluocc相关的知识,希望对你有一定的参考价值。
一 前言
分布式文件系统(Distributed File System):文件系统管理的物理存储资源不一定直接连接在本地节点上,而是通过计算机网络与节点相连.分布式文件系统的设计基于C/S模式
- 1,什么是Ceph?
Ceph:是一个 Linux PB 级分布式文件系统
特点:
具有高扩展,高可用,高性能的特点
可以提供对象存储,块存储,文件存储
可以提供PB级别的存储空间(PB->TB->GB)
帮助文档:http://docs.ceph.org/start/intro
中文文档:http://docs.ceph.org.cn/
Ceph核心组件:
OSD:存储设备(OSD越多性能越好)
Monitor:集群监控组件 (取基数,如3,5,7)
MDS:存放文件系统的元数据(对象存储和块存储不需要该组件)
Client:ceph客户端
二 搭建块存储
1,实验环境*
虚拟机都是rhel7.4,真机centos7
虚拟机:4台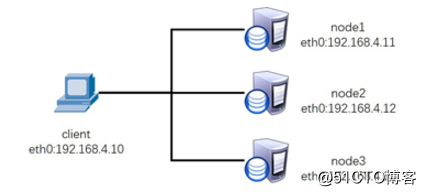
node1,node2,node3既是OSD,也是Mpnitor
真实机:(centos7)或者重新新建一台虚拟机代替真机也可以
镜像地址:https://pan.baidu.com/s/1Uo_7yEl4mTXTiS7N98Abfw
2,安装前准备
1)物理机为所有节点配置yum源服务器。
[[email protected] ~]# yum -y install vsftpd
[[email protected] ~]# mkdir /var/ftp/ceph
[[email protected] ~]# mount -o loop rhcs2.0-rhosp9-20161113-x86_64.iso /var/ftp/ceph #此光盘在网盘里
[[email protected] ~]# systemctl restart vsftpd2)修改所有节点都需要配置YUM源(这里仅以node1为例)。
[[email protected] ceph-cluster]# cat /etc/yum.repos.d/ceph.repo
[mon]
name=mon
baseurl=ftp://192.168.4.254/ceph/rhceph-2.0-rhel-7-x86_64/MON
gpgcheck=0
[osd]
name=osd
baseurl=ftp://192.168.4.254/ceph/rhceph-2.0-rhel-7-x86_64/OSD
gpgcheck=0
[tools]
name=tools
baseurl=ftp://192.168.4.254/ceph/rhceph-2.0-rhel-7-x86_64/Tools
gpgcheck=03)修改/etc/hosts并同步到所有主机。
警告:/etc/hosts解析的域名必须与本机主机名一致!!!!
[[email protected] ceph-cluster]# vim /etc/hosts
... ...
192.168.4.10 client
192.168.4.11 node1
192.168.4.12 node2
192.168.4.13 node3警告:/etc/hosts解析的域名必须与本机主机名一致!!!!
[[email protected] ceph-cluster]# for i in 10 11 12 13
> do
> scp /etc/hosts 192.168.4.$i:/etc/
> done
[[email protected] ceph-cluster]# for i in 10 11 12 13
> do
> scp /etc/yum.repos.d/ceph.repo 192.168.4.$i:/etc/yum.repos.d/
> done3)配置无密码连接(包括自己远程自己也不需要密码)。
[[email protected] ceph-cluster]# ssh-keygen -f /root/.ssh/id_rsa -N ‘‘ #生成密钥
[[email protected] ceph-cluster]# for i in 10 11 12 13 #上传密钥到个个主机
> do
> ssh-copy-id 192.168.4.$i
> done3,配置NTP时间同步
1)真实物理机创建NTP服务器。
[[email protected] ~]# yum -y install chrony
[[email protected]~]# cat /etc/chrony.conf
server 0.centos.pool.ntp.org iburst
allow 192.168.4.0/24
local stratum 10
[[email protected] ~]# systemctl restart chronyd
[[email protected] ~]# iptables -F #如果有防火墙规则,需要清空所有规则2)其他所有节点与NTP服务器同步时间(以node1为例)。
[[email protected] ceph-cluster]# cat /etc/chrony.conf
#server 0.rhel.pool.ntp.org iburst
#server 1.rhel.pool.ntp.org iburst
#server 2.rhel.pool.ntp.org iburst
server 192.168.4.254 iburst
[[email protected] ceph-cluster]# systemctl restart chronyd #重启服务
[[email protected] ceph-cluster]# systemctl enable chronyd #设置开机自启4,准备存储磁盘
直接打开虚拟机管理器添加磁盘,node1,node2,node3每台添加三个10G磁盘
5,部署软件
1)在node1安装部署工具,学习工具的语法格式。
[[email protected] ~]# yum -y install ceph-deploy
[[email protected] ~]# ceph-deploy --help #查看命令格式2)创建目录
[[email protected] ~]# mkdir ceph-cluster
[[email protected] ~]# cd ceph-cluster/6,部署Ceph集群
1)创建Ceph集群配置。
[[email protected] ceph-cluster]# ceph-deploy new node1 node2 node3
2)给所有节点安装软件包。
[[email protected] ceph-cluster]# ceph-deploy install node1 node2 node3
3)初始化所有节点的mon服务(主机名解析必须对)
[[email protected] ceph-cluster]# vim ceph.conf #文件最后追加以下内容
public_network = 192.168.4.0/24 #避免会出现如下错误加上这一行
[[email protected] ceph-cluster]# ceph-deploy mon create-initial //拷贝配置文件,并启动mon服务常见错误及解决方法(非必要操作,有错误可以参考):
如果提示如下错误信息:
[node1][ERROR ] admin_socket: exception getting command descriptions: [Error 2] No such file or directory
解决方案如下(在node1操作):
先检查自己的命令是否是在ceph-cluster目录下执行的!!!!如果时确认是在该目录下执行的create-initial命令,依然保存,可以使用如下方式修复。
[[email protected] ceph-cluster]# vim ceph.conf #文件最后追加以下内容
public_network = 192.168.4.0/24修改后重新推送配置文件:[[email protected] ceph-cluster]# ceph-deploy --overwrite-conf config push node1 node2 node3
7,创建OSD
1)准备磁盘分区(node1,node2,node3都要做)
[[email protected] ceph-cluster]# parted /dev/vdb mklabel gpt
[[email protected] ceph-cluster]# parted /dev/vdb mkpart primary 1M 50%
[[email protected] ceph-cluster]# parted /dev/vdb mkpart primary 50% 100%
[[email protected] ceph-cluster]# chown ceph.ceph /dev/vdb1 #授权给ceph用户
[[email protected] ceph-cluster]# chown ceph.ceph /dev/vdb2
提示:重启后失效,要想永久有效,1,把命令写入/etc/rc.local文件中,并给文件赋予执行权限;2,用udev写入权限
//这两个分区用来做存储服务器的日志journal盘2)初始化清空磁盘数据(仅node1操作即可)
[[email protected] ceph-cluster]# ceph-deploy disk zap node1:vdc node1:vdd
[[email protected] ceph-cluster]# ceph-deploy disk zap node2:vdc node2:vdd
[[email protected] ceph-cluster]# ceph-deploy disk zap node3:vdc node3:vdd
提示:如果已经初始化过了,需要重新清空磁盘数据,就要取(node1,node2,node3)卸载掉3)创建OSD存储空间(仅node1操作即可)
[[email protected] ceph-cluster]# ceph-deploy osd create node1:vdc:/dev/vdb1 node1:vdd:/dev/vdb2
//创建osd存储设备,vdc为集群提供存储空间,vdb1提供JOURNAL日志,
//一个存储设备对应一个日志设备,日志需要SSD,不需要很大
[[email protected] ceph-cluster]# ceph-deploy osd create node2:vdc:/dev/vdb1 node2:vdd:/dev/vdb2
[[email protected] ceph-cluster]# ceph-deploy osd create node3:vdc:/dev/vdb1 node3:vdd:/dev/vdb2 4)常见错误(非必须操作)
使用osd create创建OSD存储空间时,如提示run ‘gatherkeys‘,可以使用如下命令修复:
[[email protected] ceph-cluster]# ceph-deploy gatherkeys node1 node2 node3 8,验证测试
1) 查看集群状态
[[email protected] ceph-cluster]# ceph -s
cluster d3266b4f-5c8c-44f3-b11e-7a2cafd1f75b
health HEALTH_OK #出现ok就成功了,err就失败了,如果出现warning,执行 systemctl restart ceph*.service ceph*.target重启服务
monmap e1: 3 mons at {node1=192.168.4.11:6789/0,node2=192.168.4.12:6789/0,node3=192.168.4.13:6789/0}
election epoch 6, quorum 0,1,2 node1,node2,node3
osdmap e42: 6 osds: 6 up, 6 in
flags sortbitwise
pgmap v323: 64 pgs, 1 pools, 88496 kB data, 5147 objects
503 MB used, 119 GB / 119 GB avail
64 active+clean2)常见错误(非必须操作)
如果查看状态包含如下信息:
health: HEALTH_WARN
clock skew detected on node2, node3…
clock skew表示时间不同步,解决办法:请先将所有主机的时间都使用NTP时间同步!!!
如果状态还是失败,可以尝试执行如下命令,重启ceph服务:
[[email protected] ceph-cluster]# systemctl restart ceph*.service ceph*.target9,创建镜像
1)查看存储池。
[[email protected] ceph-cluster]# ceph osd lspools
0 rbd,2)创建镜像、查看镜像
两种创建镜像(共享硬盘)方式
方式一(没有指明存储池默认rbd)
[[email protected] ceph-cluster]# rbd create demo-image --image-feature layering --size 10G
方式二(指明存储池rbd)
[[email protected] ceph-cluster]# rbd create rbd/image --image-feature layering --size 10G
[[email protected] ceph-cluster]# rbd list #rbd ls也可以查看镜像
demo-image
image
[[email protected] ceph-cluster]# rbd info demo-image #查看具体某个镜像信息
rbd image ‘demo-image‘:
size 10240 MB in 2560 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.d3aa2ae8944a
format: 2
features: layering10,动态调整镜像大小
1)缩小容量
[[email protected] ceph-cluster]# rbd resize --size 7G image --allow-shrink
[[email protected] ceph-cluster]# rbd info image2)扩容容量
[[email protected] ceph-cluster]# rbd resize --size 15G image
[[email protected] ceph-cluster]# rbd info image11,通过KRBD访问
1)集群内将镜像映射为本地磁盘
[[email protected] ceph-cluster]# rbd map demo-image#使用内核将镜像映射到块设备
/dev/rbd0
[[email protected] ceph-cluster]# lsblk
… …
rbd0 251:0 0 10G 0 disk #此处为加载识别的块设备
[[email protected] ceph-cluster]# mkfs.xfs /dev/rbd0 #格式化
[[email protected] ceph-cluster]# mount /dev/rbd0 /mnt #挂载使用
[[email protected] ceph-cluster]# df -h #查看当前挂载信息2)客户端通过KRBD访问
#客户端需要安装ceph-common软件包
#拷贝配置文件(否则不知道集群在哪)
#拷贝连接密钥(否则无连接权限)
[[email protected] ~]# yum -y install ceph-common
[[email protected] ~]# scp 192.168.4.11:/etc/ceph/ceph.conf /etc/ceph/ #从集群中下载配置文件
[[email protected] ~]# scp 192.168.4.11:/etc/ceph/ceph.client.admin.keyring /etc/ceph/ #从集群中下载密钥
[[email protected] ~]# rbd map image #使用内核将镜像映射到块设备
[[email protected] ~]# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sr0 11:0 1 1024M 0 rom
vda 252:0 0 20G 0 disk
├─vda1 252:1 0 1G 0 part /boot
└─vda2 252:2 0 19G 0 part
├─rhel-root 253:0 0 17G 0 lvm /
└─rhel-swap 253:1 0 2G 0 lvm [SWAP]
rbd0 251:0 0 15G 0 disk #此处是使用的网络磁盘
[[email protected] ~]# rbd showmapped #查看使用的网络镜像(磁盘)信息
id pool image snap device
0 rbd image - /dev/rbd03) 客户端格式化、挂载分区并使用
[[email protected] ~]# mkfs.xfs /dev/rbd0
[[email protected] ~]# mount /dev/rbd0 /mnt/
[[email protected] ~]# echo "test" > /mnt/test.txt12,创建镜像快照
磁盘快照(Snapshot)是针对整个磁盘卷册进行快速的档案系统备份,与其它备份方式最主要的不同点在于「速度」。进行磁盘快照时,并不牵涉到任何档案复制动作。就算数据量再大,一般来说,通常可以在一秒之内完成备份动作。
磁盘快照的基本概念与磁带备份等机制有非常大的不同。在建立磁盘快照时,并不需要复制数据本身,它所作的只是通知LX Series NAS服务器将目前有数据的磁盘区块全部保留起来,不被覆写。这个通知动作只需花费极短的时间。接下来的档案修改或任何新增、删除动作,均不会覆写原本数据所在的磁盘区块,而是将修改部分写入其它可用的磁盘区块中。所以可以说,数据复制,或者说数据备份,是在平常档案存取时就做好了,而且对效能影响极低.
1)创建镜像快照
[[email protected] ceph-cluster]# rbd snap create image --snap image-snap1
[[email protected] ceph-cluster]# rbd snap ls image #查看image的快照
SNAPID NAME SIZE
4 image-snap1 15360 MB2)删除客户端写入的测试文件
[[email protected] ~]# rm -rf /mnt/test.txt
[[email protected] ~]# umount /mnt 先卸载再去还原快照,不然会报下面错误3) 还原快照
[[email protected] ceph-cluster]# rbd snap rollback image --snap image-snap1
#客户端重新挂载分区
[[email protected] ~]# mount /dev/rbd0 /mnt/
[[email protected] ~]# ls /mnt
test.txt
快照还原问题:
[[email protected] ~]# mount /dev/rbd0 /mnt
mount: 文件系统类型错误、选项错误、/dev/rbd0 上有坏超级块、
缺少代码页或助手程序,或其他错误
有些情况下在 syslog 中可以找到一些有用信息- 请尝试
dmesg | tail 这样的命令看看
解决办法:
1,先在客户机卸载
2,在node1在还原快照
2,在客户机上挂载13,创建快照克隆
1)克隆快照
[[email protected] ceph-cluster]# rbd snap protect image --snap image-snap1 #把快照保护起来
[[email protected] ceph-cluster]# rbd snap rm image --snap image-snap1 //会失败
[[email protected] ceph-cluster]# rbd clone image --snap image-snap1 image-clone --image-feature layering #使用image的快照image-snap1克隆一个新的image-clone镜像2)查看克隆镜像与父镜像快照的关系
[[email protected] ceph-cluster]# rbd info image-clone
rbd image ‘image-clone‘:
size 15360 MB in 3840 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.d3f53d1b58ba
format: 2
features: layering
flags:
parent: rbd/[email protected]
#克隆镜像很多数据都来自于快照链
#如果希望克隆镜像可以独立工作,就需要将父快照中的数据,全部拷贝一份,但比较耗时!!!
[[email protected] ceph-cluster]# rbd flatten image-clone #解除与快照的关系
[[email protected] ceph-cluster]# rbd info image-clone
rbd image ‘image-clone‘:
size 15360 MB in 3840 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.d3f53d1b58ba
format: 2
features: layering
flags:
#注意,父快照信息没了14,其他操作
1) 客户端撤销磁盘映射
[[email protected] ~]# umount /mnt
[[email protected] ~]# rbd showmapped
id pool image snap device
0 rbd image - /dev/rbd0
[[email protected] ~]# rbd unmap /dev/rbd/rbd/image #撤销磁盘映射image2)删除快照与镜像
[[email protected] ceph-deploy]# rbd snap unprotect image --snap image-snap1 #解除保护
[[email protected] ceph-cluster]# rbd snap rm image --snap image-snap1 #删除快照
[[email protected] ceph-cluster]# rbd list
[[email protected] ceph-cluster]# rbd rm image15,块存储应用案例
1)创建磁盘镜像。
[[email protected] ceph-cluster]# rbd create vm1-image --image-feature layering --size 10G
[[email protected] ceph-cluster]# rbd create vm2-image --image-feature layering --size 10G
[[email protected] ceph-cluster]# rbd list
[[email protected] ceph-cluster]# rbd info vm1-image
[[email protected] ceph-cluster]# qemu-img info rbd:rbd/vm1-image
image: rbd:rbd/vm1-image
file format: raw
virtual size: 10G (10737418240 bytes)
disk size: unavailable2)Ceph认证账户。
Ceph默认开启用户认证,客户端需要账户才可以访问,
默认账户名称为client.admin,key是账户的密钥,
可以使用ceph auth添加新账户(案例我们使用默认账户)。
[[email protected] ceph-cluster]# cat /etc/ceph/ceph.conf //配置文件
[global]
mon_initial_members = node1, node2, node3
mon_host = 192.168.2.10,192.168.2.20,192.168.2.30
auth_cluster_required = cephx //开启认证
auth_service_required = cephx //开启认证
auth_client_required = cephx //开启认证
[[email protected] ceph-cluster]# cat /etc/ceph/ceph.client.admin.keyring //账户文件
[client.admin]
key = AQBTsdRapUxBKRAANXtteNUyoEmQHveb75bISg==3)部署客户端环境。
注意:这里使用真实机当客户端!!!
客户端需要安装ceph-common软件包,拷贝配置文件(否则不知道集群在哪),
拷贝连接密钥(否则无连接权限)。
[[email protected] ~]# yum -y install ceph-common
[[email protected] ~]# scp 192.168.4.11:/etc/ceph/ceph.conf /etc/ceph/ #下载ceph配置文件
[[email protected] ~]# scp 192.168.4.11:/etc/ceph/ceph.client.admin.keyring /etc/ceph/ #下载ceph密钥4)创建KVM虚拟机。
使用virt-manager创建1台普通的KVM虚拟机。名称为vm1
5)配置libvirt secret。
编写账户信息文件(真实机操作)
[[email protected] ~]# vim secret.xml //新建临时文件,内容如下
<secret ephemeral=‘no‘ private=‘no‘>
<usage type=‘ceph‘>
<name>client.admin secret</name>
</usage>
</secret>
#使用XML配置文件创建secret
[[email protected] ~]# virsh secret-define --file secret.xml
生成 secret c409ec4c-803b-46bc-b4e4-35dc86a08f85
//随机的UUID,这个UUID对应的有账户信息
编写账户信息文件(真实机操作)
--获取client.admin的key,或者直接查看密钥文件
方式一:
[[email protected] ~]# ceph auth get-key client.admin
方式二:
[[email protected] ~]# cat /etc/ceph/ceph.client.admin.keyring
[client.admin]
key = AQDExOpbE+W9BxAA9QBqQUAY0tFmSmjOWmS8Nw==--设置secret,添加账户的密钥
[[email protected] ~]# virsh secret-set-value --secret c409ec4c-803b-46bc-b4e4-35dc86a08f85 --base64 AQDExOpbE+W9BxAA9QBqQUAY0tFmSmjOWmS8Nw==
//这里secret后面是之前创建的secret的UUID
//base64后面是client.admin账户的密码
//现在secret中既有账户信息又有密钥信息
[[email protected] room2018]# virsh secret-list #查看uuid
UUID 用量
--------------------------------------------------------------------------------
c409ec4c-803b-46bc-b4e4-35dc86a08f85 ceph client.admin secret6)虚拟机的XML配置文件。
每个虚拟机都会有一个XML配置文件,包括:
虚拟机的名称、内存、CPU、磁盘、网卡等信息
[[email protected] ~]# vim /etc/libvirt/qemu/vm1.xml
//修改前内容如下
<disk type=‘file‘ device=‘disk‘>
<driver name=‘qemu‘ type=‘qcow2‘/>
<source file=‘/var/lib/libvirt/images/vm1.qcow2‘/>
<target dev=‘vda‘ bus=‘virtio‘/>
<address type=‘pci‘ domain=‘0x0000‘ bus=‘0x00‘ slot=‘0x07‘ function=‘0x0‘/>
</disk>
不推荐直接使用vim修改配置文件,推荐使用virsh edit修改配置文件,效果如下:
[[email protected]] virsh edit vm1 //vm1为虚拟机名称
<disk type=‘network‘ device=‘disk‘>
<driver name=‘qemu‘ type=‘raw‘/>
<auth username=‘admin‘>
<secret type=‘ceph‘ uuid=‘c409ec4c-803b-46bc-b4e4-35dc86a08f85‘/>
</auth>
<source protocol=‘rbd‘ name=‘rbd/vm1-image‘>
<host name=‘192.168.4.11‘ port=‘6789‘/>
</source>
<target dev=‘vda‘ bus=‘virtio‘/>
<address type=‘pci‘ domain=‘0x0000‘ bus=‘0x00‘ slot=‘0x07‘ function=‘0x0‘/>
</disk>
提示:保存退出出现"编辑了域 rhel7.4 XML 配置。"说明成功了
源路经:rbd://192.168.4.11:6789/rbd/vm1-imageCeph块存储总结:
1,Linux可以直接使用
2,Kvm虚拟机使用,修改kvm虚拟机xml配置文件
二 Ceph文件系统(MDS)
1,添加一台新的虚拟机,要求如下:
IP地址:192.168.4.14
主机名:node4(部署元数据服务器)
配置yum源(包括rhel、ceph的源)
与真机主机同步时间([[email protected] ceph-deploy]# scp /etc/chrony.conf [email protected]:/etc/)
node1允许无密码远程node4 命令:ssh-copy-id [email protected]
[[email protected] ceph-deploy]#vim /etc/hosts #并拷贝到node1-4,client
192.168.4.10 client
192.168.4.11 node1
192.168.4.12 node2
192.168.4.13 node3
192.168.4.14 node4
2,部署元数据服务器
登陆node4,安装ceph-mds软件包
[[email protected] ceph-cluster]yum -y install ceph-mds
登陆node1部署节点操作
[[email protected] ceph-cluster]# cd /root/ceph-cluster #该目录,是最早部署ceph集群时,创建的目录
[[email protected] ceph-cluster]# ceph-deploy mds create node4 #给nod4拷贝配置文件,启动mds服务
[[email protected] ceph-cluster]# ceph-deploy admin node4 #同步配置文件和key3,创建存储池
[[email protected] ceph-cluster]ceph osd pool create cephfs_data 128 #创建存储池,对应128个PG
[[email protected] ceph-cluster]ceph osd pool create cephfs_metadata 128 #创建存储池,对应128个PG4,创建Ceph文件系统
[[email protected] ceph-cluster]ceph mds stat //查看mds状态
e2:, 1 up:standby
[[email protected] ceph-cluster]ceph fs new myfs1 cephfs_metadata cephfs_data
new fs with metadata pool 2 and data pool 1
//注意,现在medadata池,再写data池
//默认,只能创建1个文件系统,多余的会报错
[[email protected] ceph-cluster]ceph fs ls
name: myfs1, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
[[email protected] ceph-cluster]ceph mds stat
e4: 1/1/1 up {0=node4=up:creating}*5,客户端挂载*
[[email protected] ~]# mount -t ceph 192.168.4.11:6789:/ /mnt/cephfs/ -o name=admin,secret=AQBTsdRapUxBKRAANXtteNUyoEmQHveb75bISg==
//注意:文件系统类型为ceph
//192.168.4.11为MON节点的IP(不是MDS节点)
//admin是用户名,secret是密钥
//密钥可以在/etc/ceph/ceph.client.admin.keyring中找到
[[email protected] ~]# df -h
文件系统 容量 已用 可用 已用% 挂载点
/dev/mapper/rhel-root 17G 5.2G 12G 31% /
devtmpfs 481M 0 481M 0% /dev
tmpfs 497M 0 497M 0% /dev/shm
tmpfs 497M 7.0M 490M 2% /run
tmpfs 497M 0 497M 0% /sys/fs/cgroup
/dev/vda1 1014M 161M 854M 16% /boot
tmpfs 100M 0 100M 0% /run/user/0
192.168.4.11:6789:/ 120G 512M 120G 1% /mnt/cephfs三 创建对象存储服务器(RGW)
1,部署对象存储服务器
1)准备实验环境,要求如下:
IP地址:192.168.4.15
主机名:node5
配置yum源(包括rhel、ceph的源) #参考上面步骤
与真机主机同步时间 参考上面配置ntp步骤
node1允许无密码远程node5 命令:[[email protected] ceph-deploy]# ssh-copy-id [email protected]
修改node1的/etc/hosts,并同步到所有node1-5主机 #参考上面同步脚本
[[email protected] ceph-cluster]# vim /etc/hosts
... ...
192.168.4.10 client
192.168.4.11 node1
192.168.4.12 node2
192.168.4.13 node3
192.168.4.14 node4
192.168.4.15 node5
2)部署RGW软件包
[[email protected] ceph-deploy]# ceph-deploy install --rgw node5 #给node5安装软件包
[[email protected] ceph-deploy]# ceph-deploy admin node5 #同步配置文件与密钥到node53)新建网关实例
[[email protected] ceph-deploy]# ceph-deploy rgw create node5 #启动一个rgw服务
[[email protected] ~]# ps aux |grep radosgw #登陆node5验证服务是否启动
ceph 4109 0.2 1.4 2289196 14972 ? Ssl 22:53 0:00 /usr/bin/radosgw -f --cluster ceph --name client.rgw.node4 --setuser ceph --setgroup ceph
[[email protected] ~]# systemctl status [email protected]*4)修改服务端口
登陆node5,RGW默认服务端口为7480,修改为8000或80更方便客户端记忆和使用
[[email protected] ~]# vim /etc/ceph/ceph.conf
[client.rgw.node5]
host = node5
rgw_frontends = "civetweb port=80"
//node5为主机名
//civetweb是RGW内置的一个web服务
[[email protected] ~]# systemctl restart [email protected] #重启服务
[[email protected] ~]# ss -tunlp | grep :80 #查看端口80信息
tcp LISTEN 0 128 *:80 *:* users:(("radosgw",pid=5994,fd=30))2,客户端测试
1)curl测试
[[email protected] ~]# curl 192.168.4.15:8000 #出现这个就搭建成功了
<?xml version="1.0" encoding="UTF-8"?><ListAllMyBucketsResult xmlns="http://s3.amazonaws.com/doc/2006-03-01/"><Owner><ID>anonymous</ID><DisplayName></DisplayName></Owner><Buckets></Buckets></ListAllMyBucketsResult>
真机访问: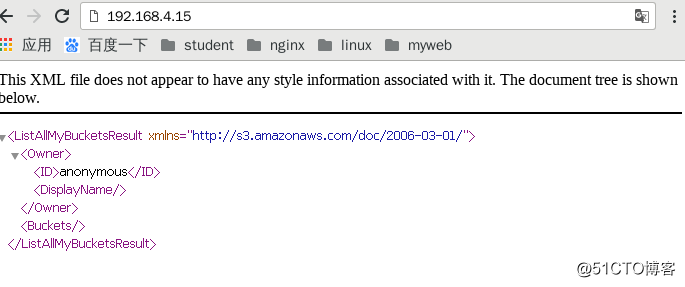
2)使用第三方软件访问
登陆node5(RGW)创建账户
[[email protected] ~]# radosgw-admin user create --uid="testuser" --display-name="First User"
… …
"keys": [
{
"user": "testuser",
"access_key": "5E42OEGB1M95Y49IBG7B",
"secret_key": "i8YtM8cs7QDCK3rTRopb0TTPBFJVXdEryRbeLGK6"
}
],
... ...
[[email protected] ~]# radosgw-admin user info --uid=testuser
//testuser为用户,key是账户访问密钥3)客户端安装软件
[[email protected] ~]# yum install s3cmd-2.0.1-1.el7.noarch.rpm
修改软件配置
[[email protected] ~]# s3cmd –configure
Access Key: 5E42OEGB1M95Y49IBG7B
Secret Key: i8YtM8cs7QDCK3rTRopb0TTPBFJVXdEryRbeLGK6
S3 Endpoint [s3.amazonaws.com]: 192.168.4.15:8000
[%(bucket)s.s3.amazonaws.com]: %(bucket)s.192.168.4.15:8000
Use HTTPS protocol [Yes]: No
Test access with supplied credentials? [Y/n] Y
Save settings? [y/N] y
//注意,其他提示都默认回车4)创建存储数据的bucket(类似于存储数据的目录)
[[email protected] ~]# s3cmd ls
[[email protected] ~]# s3cmd mb s3://my_bucket
Bucket ‘s3://my_bucket/‘ created
[[email protected] ~]# s3cmd ls
2018-05-09 08:14 s3://my_bucket
[[email protected] ~]# s3cmd put /var/log/messages s3://my_bucket/log/
[[email protected] ~]# s3cmd ls
2018-05-09 08:14 s3://my_bucket
[[email protected] ~]# s3cmd ls s3://my_bucket
DIR s3://my_bucket/log/
[[email protected] ~]# s3cmd ls s3://my_bucket/log/
2018-05-09 08:19 309034 s3://my_bucket/log/messages
测试下载功能
[[email protected] ~]# s3cmd get s3://my_bucket/log/messages /tmp/
测试删除功能
[[email protected] ~]# s3cmd del s3://my_bucket/log/messages以上是关于部署Ceph集群--jluocc的主要内容,如果未能解决你的问题,请参考以下文章