机器学习工程师 - Udacity 监督学习
Posted paulonetwo
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习工程师 - Udacity 监督学习相关的知识,希望对你有一定的参考价值。
一、线性回归
1.线性回归:一种用于预测数值数据的非常有效的算法。
假设直线为y=w1x+w2;点为(p,q)。调整直线的技巧:
1)绝对值技巧:如果点在直线上方,y=(w1+pɑ)x+(w2+ɑ),其中ɑ为学习速率。点在直线下方,y=(w1-pɑ)x+(w2-ɑ)。
p存在的原因:
a.如果点不在y轴的右侧,而在左侧,此时p为负,可保证直线绕点的方向旋转;
b.如果点距y轴近,则p的值较小,直线一次旋转的角度就小,如果点距y轴远,则p的值较大,直线一次旋转的角度就大,这符合我们的期望。
2)平方技巧:无论点在直线的上方还是下方,y=(w1+p(q-y)ɑ)x+(w2+(q-y)ɑ),因为(q-y)的正负随点的位置变化。该技巧的优点是,如果点距直线近,则小幅移动直线,如果点距直线远,则大幅移动直线。
2.梯度下降
梯度指出了误差函数增加至最大时的方向。因此我们将权值改为权值减去权值的误差导数和学习速率的乘积。
梯度下降与使用绝对值技巧和平方技巧完全相同。
3.误差函数
线性回归最常见的两类误差函数为平均绝对误差和均方误差。
4.小批量梯度下降法
随机梯度下降法:逐个地在每个数据点应用平方(或绝对)误差,并重复这一流程很多次。
批量梯度下降法:同时在每个数据点应用平方(或绝对)误差,并重复这一流程很多次。
实际上,在大部分情况下,两种都不用。思考以下情形:如果你的数据十分庞大,两种方法的计算速度都将会很缓慢。线性回归的最佳方式是将数据拆分成很多小批次。每个批次都大概具有相同数量的数据点。然后使用每个批次更新权重。这种方法叫做小批次梯度下降法。
5.绝对值误差VS平方误差
当直线位于两点之间时,直线的任意位置的绝对值误差是一样的,但只有在两点中点时平方误差最小。
6.scikit-learn中的线性回归
from sklearn.linear_model import LinearRegression
model = LinearRegression()
model.fit(x_values, y_values)
print(model.predict([ [127], [248] ]))
[[ 438.94308857, 127.14839521]]
用 [127] 这样的数组(而不只是 127)进行行预测的原因是模型可以使用多个特征进行预测。
7.多元线性回归
你可以使用两个以上的预测器变量,实际上可以使用任意多个,只要有用即可!如果你使用 n 个预测器变量,那么模型可以用以下方程表示:
y = m1x1 + m2x2 + m3x3 + ... + mnxn + b
我们依然可以通过相同的方式拟合模型并作出预测。
8.解数学方程组
在二元线性回归中,我们可以通过求解方程组得到准确的线性方程,但在n元线性回归中,需要求解含有n个未知数的n元方程组,在某个点上的解,需要转置一个n*n的矩阵,转化大矩阵,需要大量的时间和算力。这就是我们使用梯度下降法的原因。但如果我们的数据稀疏,即如果矩阵的大部分条目 x 是 0,就会有一些非常有趣的算法,能够迅速找到求取权重所需的倒数,将使这种方法在现实生活中非常有用。
9.线性回归注意事项
1)最适用于线性数据
线性回归会根据训练数据生成直线模型。如果训练数据包含非线性关系,你需要选择:调整数据(进行数据转换)、增加特征数量或改用其他模型。
2)容易受到异常值影响
线性回归的目标是求取对训练数据而言的 “最优拟合” 直线。如果数据集中存在不符合总体规律的异常值,最终结果将会存在不小偏差。
10.多项式回归
仅用一条直线无法很好地拟合数据时,我们可以使用多项式,如2x3-8x2。这就可以用类似线性回归的算法进行解决。
11.正则化
改善模型,确保不会过度拟合。可用于回归和分类。通过将误差加上一个模型复杂度惩罚项来实现。
L1正则化:惩罚项为所有权重的绝对值的和。计算效率不高,只有数据稀疏时比L2快。最大好处在于提供特征选择。
L2正则化:惩罚项为所有权重的平方的和。
可以通过λ乘以惩罚项来调节想选择简单模型还是复杂模型。
12.神经网络回归
解决非线性数据的另一种方法是使用分段线性函数。
为了得到任意值而不是0~1之间的值,我们可以删掉神经网络中的最后一个sigmoid单元,得到的就是前面各层的输出加权总和。为了了训练这个网络,我们可以使用不同的误差或损失函数,再结合反向传播。
二、感知器
1.感知器是一种分类算法,是神经网络的基础。分类算法的目标是通过线性划分使得预测值尽可能与标签相似。
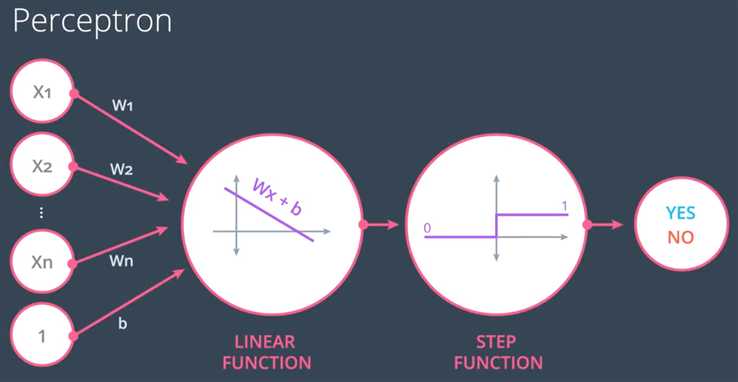
参阅:感知器、logistic与svm区别与联系(https://blog.csdn.net/m0_37786651/article/details/61614865)
2.感知器算法
如果错误点在直线上方,用该点坐标及1(代表偏差)乘以学习速率,然后用直线的系数减去这些值得到新的直线;如果点在直线下方,将减改为加。
对于坐标轴为 (p,q) 的点,标签 y,以及等式 y^ = step(w1x1 + w2x2 + b) 给出的预测:
如果点分类正确,则什么也不做。
如果点分类为正,但是标签为负,则分别减去 αp,αq, 和 α 至 w1, w2,和 b。
如果点分类为负,但是标签为正,则分别将 αp,αq, 和 α 加到 w1, w2, 和 b上。
三、决策树
1.熵(Entropy)
集合越稳固或越具有同类性,其熵越低。
熵越低,知识越高。
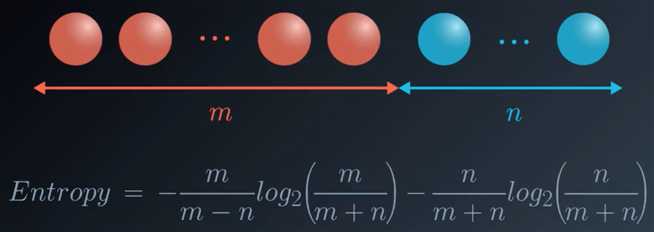
2.信息增益
父结点的熵与子结点熵平均值之间的差值。
决策树应使信息增益最大。
3.随机森林
决策树经常会过拟合。
随机从数据中挑选几列,并根据这些列构建决策树,然后随机选取其它几列,再次构建决策树,然后让决策树进行选择,当有新的数据时,只需让所有的决策树做出预测,并选取结果中显示最多的。
比随机选取列更好的方法是集成方法。
4.决策树的超参数
1)最大深度
决策树的最大深度指树根和叶子之间的最大长度。当决策树的最大深度为 k 时,它最多可以拥有 2^k 片叶子。
2)每片叶子的最小样本数
在分裂节点时,很有可能一片叶子上有 99 个样本,而另一片叶子上只有 1 个样本。这将使我们陷入困境,并造成资源和时间的浪费。如果想避免这种问题,我们可以设置每片叶子允许的最小样本数。这个数字可以被指定为一个整数,也可以是一个浮点数。如果它是整数,它将表示这片叶子上的最小样本数。如果它是个浮点数,它将被视作每片叶子上的最小样本比例。比如,0.1 或 10% 表示如果一片叶子上的样本数量小于该节点中样本数量的 10%,这种分裂将不被允许。
3)每次分裂的最小样本数
这个参数与每片叶子上的最小样本树相同,只不过是应用在节点的分裂当中。
4)最大特征数
有时,我们会遇到特征数量过于庞大,而无法建立决策树的情况。在这种状况下,对于每一个分裂,我们都需要检查整个数据集中的每一个特征。这种过程极为繁琐。而解决方案之一是限制每个分裂中查找的特征数。如果这个数字足够庞大,我们很有可能在查找的特征中找到良好特征(尽管也许并不是完美特征)。然而,如果这个数字小于特征数,这将极大加快我们的计算速度。
5.sklearn中的决策树
from sklearn.tree import DecisionTreeClassifier
model = DecisionTreeClassifier()
model.fit(x_values, y_values)
当我们定义模型时,可以指定超参数。在实践中,最常见的超参数包括:
max_depth:树中的最大层级数量。
min_samples_leaf:叶子允许的最低样本数量。
min_samples_split:拆分内部节点所需的最低样本数量。
max_features:寻找最佳拆分方法时要考虑的特征数量。
四、朴素贝叶斯
1.优点:能够处理大量特征;相对比较简单,易于实现;很少需要调整参数,除非通常分布数据已知的情况需要调整;很少会过拟合数据;训练和预测速度很快。
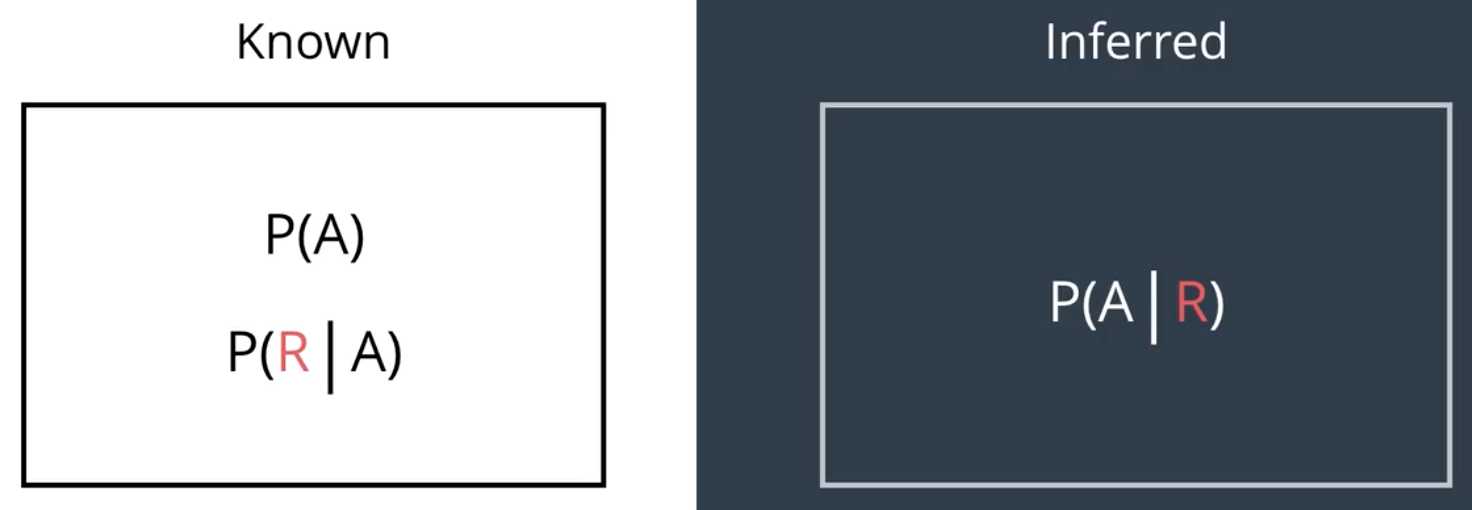
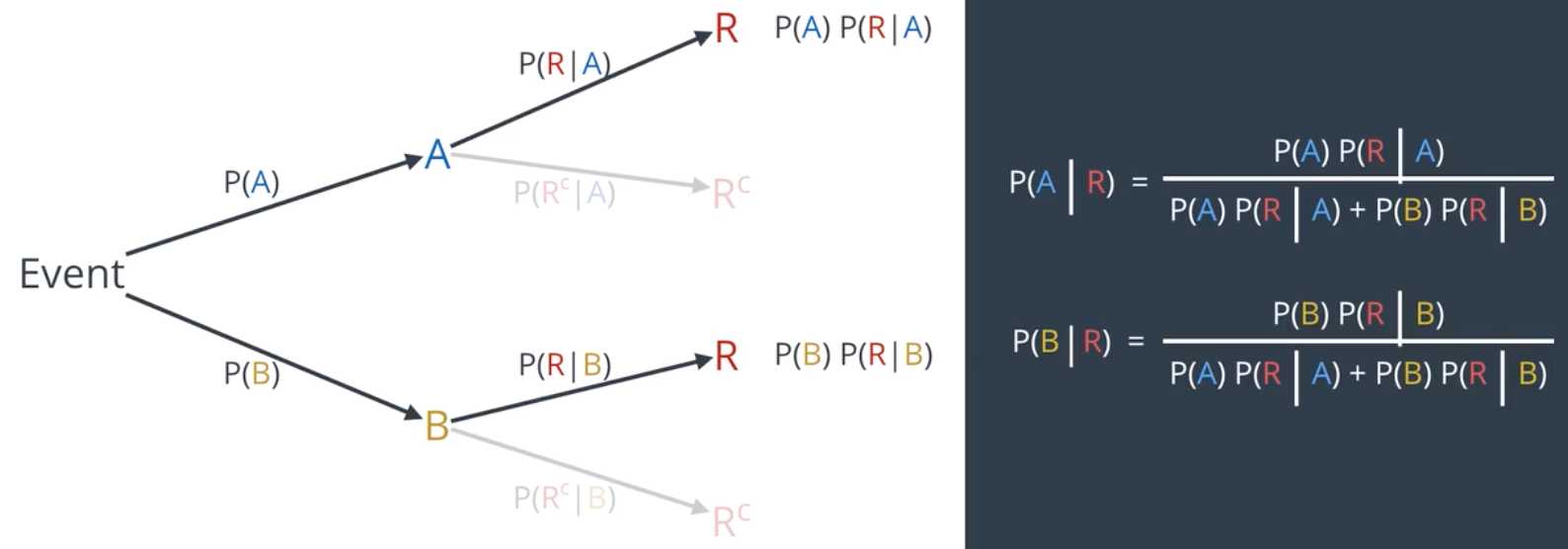
P(A)和P(B)称为先验概率,即在不知道R事件发生的情况下事件A和B发生的概率。P(A | R)和P(B | R)称为后验概率,在已知R事件发生的情况下推断出的A和B事件发生的概率。
2.误报
检测准确率为99%,患病率为万分之一,某人被检测为阳性,那么他实际患病的概率小于1%。
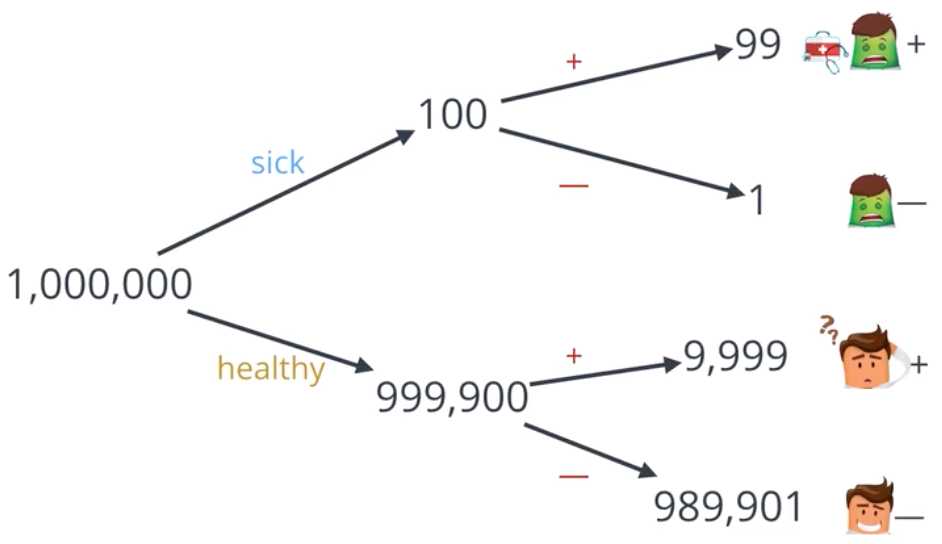
造成这种误报的原因是患病率远低于检测准确率,这种现象叫做“假阳性”,它不光是医学界的噩梦,也是法律界和其他很多领域的噩梦。
3.朴素贝叶斯算法
1)P(A∩B)=P(A)P(B),仅在两个事件相互独立时成立。在朴素贝叶斯中,我们总是假设概率是相互独立的。
2)P(A | B)P(B)=P(B | A)P(A),这是贝叶斯定理的基础。在朴素贝叶斯中,我们将P(B)去掉,记为:P(A | B)∝P(B | A)P(A),即P(A | B)与P(B | A)P(A)成比例。
以垃圾邮件检测为例:
P(spam | ‘easy‘,‘money‘, ...,‘cheap‘) ∝P(‘easy‘,‘money‘, ...,‘cheap‘ | spam)P(spam)
即,
P(spam | ‘easy‘,‘money‘, ...,‘cheap‘) ∝P(‘easy‘ | spam)P(‘money‘ | spam)...P(‘cheap‘ | spam)P(spam)
同理,计算出P(ham | ‘easy‘,‘money‘, ...,‘cheap‘)
计算它们的比例,得出邮件是否为垃圾邮件的最终概率。
4.sklearn中的朴素贝叶斯
from sklearn.naive_bayes import MultinomialNB
naive_bayes = MultinomialNB()
naive_bayes.fit(training_data, y_train)
五、支持向量机
1.SVM的目标不仅是分类数据,而且会寻找最佳潜在边界,即点与点之间保持最大距离的边界。
2.误差

待续
以上是关于机器学习工程师 - Udacity 监督学习的主要内容,如果未能解决你的问题,请参考以下文章
机器学习工程师 - Udacity 强化学习 Part Three