当master宕机了要把slave1变为master,并把slave2指向slave1。 运行时更改master-slave,config set/get,修改一台slave(设为A)为new master 1)命令该服务不做其他redis服务的slave,命令: slaveof no one 2)修改其readonly为yes,其他的slave再指向new master A 1)命令该服务为new master A的slave,命令格式 slaveof IP port 6379:>shutdown 6378,6377>info replication "# Replication role:slave master_host:127.0.0.1 master_port:6379 master_link_status:down 6378:0>slaveof no one //不在是从服务器 "OK" 6378:0>info replication //现在已经是主服务器了,0个从 "# Replication role:master connected_slaves:0 6378:0>config get slave-read-only //不能是readonly的 1) "slave-read-only" 2) "yes" 6378:0>config set slave-read-only no "OK" 6378:0>config get slave-read-only 1) "slave-read-only" 2) "no" 6377:0>slaveof 127.0.0.1 6378 "OK" //原来6377,6378指向6379,现在6379宕机6378变为master6377变为6378的slave 6379:0>info replication "# Replication role:master connected_slaves:0 6378:0>info replication "# Replication role:master connected_slaves:1 slave0:ip=127.0.0.1,port=6377,state=online,offset=408,lag=0 6377:0>info replication "# Replication role:slave master_host:127.0.0.1 master_port:6378
监控工具 sentinel(就是刚才手工的操作) sentinel monitor mymaster 127.0.0.1 6379 2 //2个sentinel监控到失效了 sentinel auth-pass mymaster 012_345^678-90 ##master被当前sentinel实例认定为“失效”的间隔时间 ##如果当前sentinel与master直接的通讯中,在指定时间内没有响应或者响应错误代码,那么当前sentinel就认为master失效(SDOWN,“主观”失效) ##<mastername> <millseconds> 默认为30秒 sentinel down-after-milliseconds mymaster 30000 //30000毫秒,30秒 ##当前sentinel实例是否允许实施“failover”(故障转移,把不把slave变为master) ##no表示当前sentinel为“观察者”(只参与"投票".不参与实施failover),(一般是多台sentinel监控一台master,只有一台sentinel可以修改slave为master,多台sentlnel不能一起改。有2台发现宕机了就宕机了),##全局中至少有一个为yes只能一个sentinel来修改。 sentinel can-failover mymaster yes // ##sentinel notification-script mymaster /var/redis/notify.sh
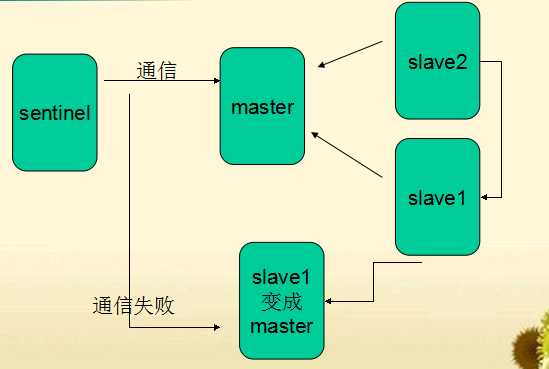
Sentinel不断与master通信,获取master的slave信息,监听master与slave的状态 如果某slave失效,直接通知master去除该slave,如果master失效,,是按照slave优先级(可配置), 选取1个slave做 new master,把其他slave--> new master 疑问: sentinel与master通信,如果某次因为master IO操作频繁,导致超时, 此时,认为master失效,很武断.解决: sentnel允许多个实例看守1个master, 当N台(N可设置)sentinel都认为master失效,才正式失效. Sentinel.conf 选项配置: port 26379 # 端口 sentinel monitor mymaster 127.0.0.1 6379 2 , //给主机起的名字(不重即可), 当2个sentinel实例都认为master失效时,正式失效 sentinel down-after-milliseconds mymaster 30000 #多少毫秒后连接不到master认为断开 sentinel can-failover mymaster yes #是否允许sentinel修改slave->master. 如为no,则只能监控,无权修改./ sentinel parallel-syncs mymaster 1 , #一次性修改几个slave指向新的new master.1表示是一台一台的来,防止新的masterio过高而宕机 sentinel failover-timeout mymaster 900000 //15分钟之内没有完成刚才的所有操作则表示操作失败,然后发送短信什么的。 sentinel client-reconfig-script mymaster /var/redis/reconfig.sh ,# 在重新配置new master,new slave过程,可以触发的脚本 Redis-server ./Sentinel.conf --sentinel //启动
slave-priority 10 //多个slave的时候可以选择哪个优先作为master,越小越靠前。 //同一个redis实例里面复制多个配置文件,就可以开启多个redis实例和sentinel。
80是主,77,78,79是从。80宕机后79是主,并且是改了配置文件,也就是说重启后79仍然是主(通过info replication查看主从信息)。如果79 的数据比80 少,那么79做主后80的数据跟79同步,那么79的数据也会丢失。Sentinel 的配置文件也改了,