爬虫基础1 怎么使用浏览器查看网络请求
Posted alfredzky
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫基础1 怎么使用浏览器查看网络请求相关的知识,希望对你有一定的参考价值。
推荐使用火狐和谷歌浏览器,一般两个对照着看。
下面是两个浏览器对同一个网址的页面进行检查的,对比,火狐直接是中文显示,谷歌则是英文显示。
如下页面是火狐的

如下是谷歌浏览器的
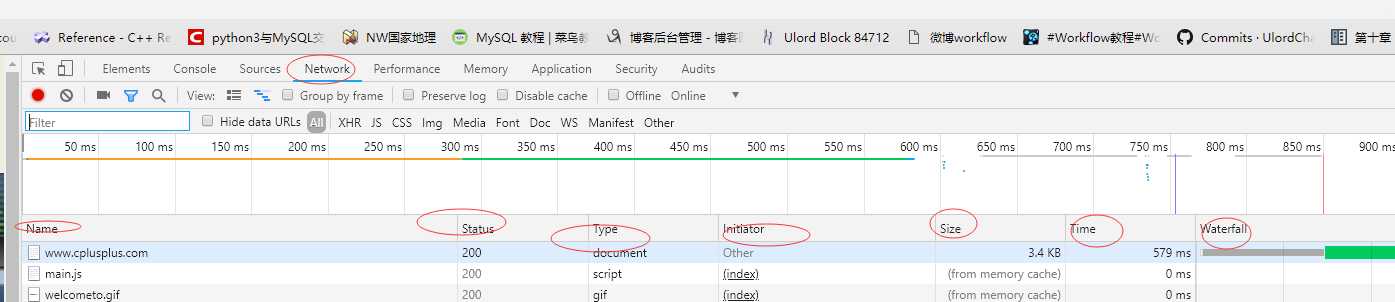
下面是这些字段的介绍:
1.Name:请求的名称,一般是会将URL的最后一部分内容当做名称
2.Satus:响应的状态码,200代表响应成功。
3.Type:请求的文档类型,这里是document,代表请求的是一个html文档,内容就是一些HTML代码。
4.Initiator:请求源,用来标记请求是由那个对象或进程发起的。
5.Size:从服务器下载的文件和请求资源的大小。如果是从缓冲中取得的资源,则该列会显示from memory cache
6.Time:发起请求到获取响应所用的总时间
7.Waterfall:网络请求的可视化pubuliu
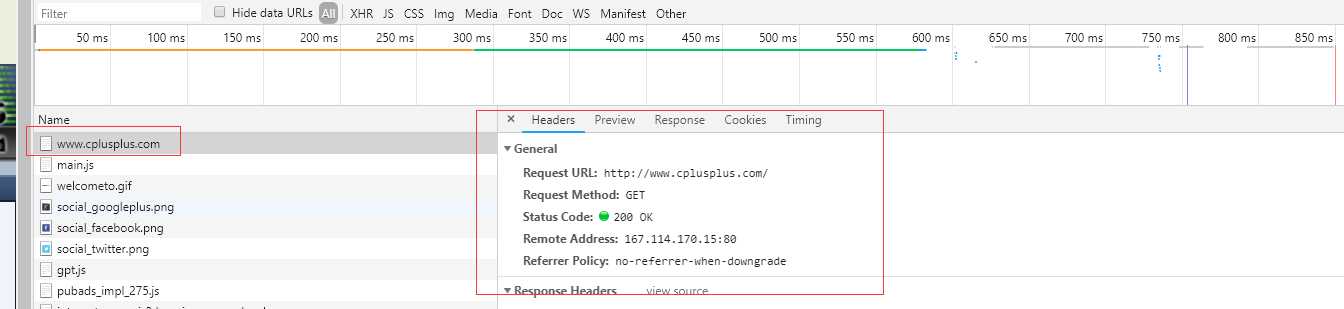
点击名字进去后,就可以看到更详细的内容,上面分别是Header,Preview,Response,Cookies,Timing等四个字段。请求头,预览,响应,cookies储存在用户本地终端上的数据,时间。
主要看消息头里面的东西
General:
Requests URL:请求的url
Request Method:请求方法
Status Code:显示状态码
Remote Address:域名对应的真实ip:port
Referrer Policy:按照浏览器的默认值执行。默认值为 no-referrer-when-downgrade。部分标签可重定义此安全策略,当发生降级(比如从 https:// 跳转到 http:// )时,不传递 Referrer 报头。但是反过来的话不受影响。通常也会当作浏览器的默认安全策略。
以上是关于爬虫基础1 怎么使用浏览器查看网络请求的主要内容,如果未能解决你的问题,请参考以下文章