lucene源码分析facet实例
Posted davidwang456
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了lucene源码分析facet实例相关的知识,希望对你有一定的参考价值。
简单的facet实例
public class SimpleFacetsExample { private final Directory indexDir = new RAMDirectory(); private final Directory taxoDir = new RAMDirectory(); private final FacetsConfig config = new FacetsConfig(); /** Empty constructor */ public SimpleFacetsExample() { config.setHierarchical("Publish Date", true); } /** Build the example index. */ private void index() throws IOException { IndexWriter indexWriter = new IndexWriter(indexDir, new IndexWriterConfig( new WhitespaceAnalyzer()).setOpenMode(OpenMode.CREATE)); // Writes facet ords to a separate directory from the main index DirectoryTaxonomyWriter taxoWriter = new DirectoryTaxonomyWriter(taxoDir); Document doc = new Document(); doc.add(new FacetField("Author", "Bob")); doc.add(new FacetField("Publish Date", "2010", "10", "15")); indexWriter.addDocument(config.build(taxoWriter, doc)); doc = new Document(); doc.add(new FacetField("Author", "Lisa")); doc.add(new FacetField("Publish Date", "2010", "10", "20")); indexWriter.addDocument(config.build(taxoWriter, doc)); doc = new Document(); doc.add(new FacetField("Author", "Lisa")); doc.add(new FacetField("Publish Date", "2012", "1", "1")); indexWriter.addDocument(config.build(taxoWriter, doc)); doc = new Document(); doc.add(new FacetField("Author", "Susan")); doc.add(new FacetField("Publish Date", "2012", "1", "7")); indexWriter.addDocument(config.build(taxoWriter, doc)); doc = new Document(); doc.add(new FacetField("Author", "Frank")); doc.add(new FacetField("Publish Date", "1999", "5", "5")); indexWriter.addDocument(config.build(taxoWriter, doc)); indexWriter.close(); taxoWriter.close(); } /** User runs a query and counts facets. */ private List<FacetResult> facetsWithSearch() throws IOException { DirectoryReader indexReader = DirectoryReader.open(indexDir); IndexSearcher searcher = new IndexSearcher(indexReader); TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir); FacetsCollector fc = new FacetsCollector(); // MatchAllDocsQuery is for "browsing" (counts facets // for all non-deleted docs in the index); normally // you‘d use a "normal" query: FacetsCollector.search(searcher, new MatchAllDocsQuery(), 10, fc); // Retrieve results List<FacetResult> results = new ArrayList<>(); // Count both "Publish Date" and "Author" dimensions Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc); results.add(facets.getTopChildren(10, "Author")); results.add(facets.getTopChildren(10, "Publish Date")); indexReader.close(); taxoReader.close(); return results; } /** User runs a query and counts facets only without collecting the matching documents.*/ private List<FacetResult> facetsOnly() throws IOException { DirectoryReader indexReader = DirectoryReader.open(indexDir); IndexSearcher searcher = new IndexSearcher(indexReader); TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir); FacetsCollector fc = new FacetsCollector(); // MatchAllDocsQuery is for "browsing" (counts facets // for all non-deleted docs in the index); normally // you‘d use a "normal" query: searcher.search(new MatchAllDocsQuery(), fc); // Retrieve results List<FacetResult> results = new ArrayList<>(); // Count both "Publish Date" and "Author" dimensions Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc); results.add(facets.getTopChildren(10, "Author")); results.add(facets.getTopChildren(10, "Publish Date")); indexReader.close(); taxoReader.close(); return results; } /** User drills down on ‘Publish Date/2010‘, and we * return facets for ‘Author‘ */ private FacetResult drillDown() throws IOException { DirectoryReader indexReader = DirectoryReader.open(indexDir); IndexSearcher searcher = new IndexSearcher(indexReader); TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir); // Passing no baseQuery means we drill down on all // documents ("browse only"): DrillDownQuery q = new DrillDownQuery(config); // Now user drills down on Publish Date/2010: q.add("Publish Date", "2010"); FacetsCollector fc = new FacetsCollector(); FacetsCollector.search(searcher, q, 10, fc); // Retrieve results Facets facets = new FastTaxonomyFacetCounts(taxoReader, config, fc); FacetResult result = facets.getTopChildren(10, "Author"); indexReader.close(); taxoReader.close(); return result; } /** User drills down on ‘Publish Date/2010‘, and we * return facets for both ‘Publish Date‘ and ‘Author‘, * using DrillSideways. */ private List<FacetResult> drillSideways() throws IOException { DirectoryReader indexReader = DirectoryReader.open(indexDir); IndexSearcher searcher = new IndexSearcher(indexReader); TaxonomyReader taxoReader = new DirectoryTaxonomyReader(taxoDir); // Passing no baseQuery means we drill down on all // documents ("browse only"): DrillDownQuery q = new DrillDownQuery(config); // Now user drills down on Publish Date/2010: q.add("Publish Date", "2010"); DrillSideways ds = new DrillSideways(searcher, config, taxoReader); DrillSidewaysResult result = ds.search(q, 10); // Retrieve results List<FacetResult> facets = result.facets.getAllDims(10); indexReader.close(); taxoReader.close(); return facets; } /** Runs the search example. */ public List<FacetResult> runFacetOnly() throws IOException { index(); return facetsOnly(); } /** Runs the search example. */ public List<FacetResult> runSearch() throws IOException { index(); return facetsWithSearch(); } /** Runs the drill-down example. */ public FacetResult runDrillDown() throws IOException { index(); return drillDown(); } /** Runs the drill-sideways example. */ public List<FacetResult> runDrillSideways() throws IOException { index(); return drillSideways(); } /** Runs the search and drill-down examples and prints the results. */ public static void main(String[] args) throws Exception { System.out.println("Facet counting example:"); System.out.println("-----------------------"); SimpleFacetsExample example = new SimpleFacetsExample(); List<FacetResult> results1 = example.runFacetOnly(); System.out.println("Author: " + results1.get(0)); System.out.println("Publish Date: " + results1.get(1)); System.out.println("Facet counting example (combined facets and search):"); System.out.println("-----------------------"); List<FacetResult> results = example.runSearch(); System.out.println("Author: " + results.get(0)); System.out.println("Publish Date: " + results.get(1)); System.out.println("Facet drill-down example (Publish Date/2010):"); System.out.println("---------------------------------------------"); System.out.println("Author: " + example.runDrillDown()); System.out.println("Facet drill-sideways example (Publish Date/2010):"); System.out.println("---------------------------------------------"); for(FacetResult result : example.runDrillSideways()) { System.out.println(result); } } }
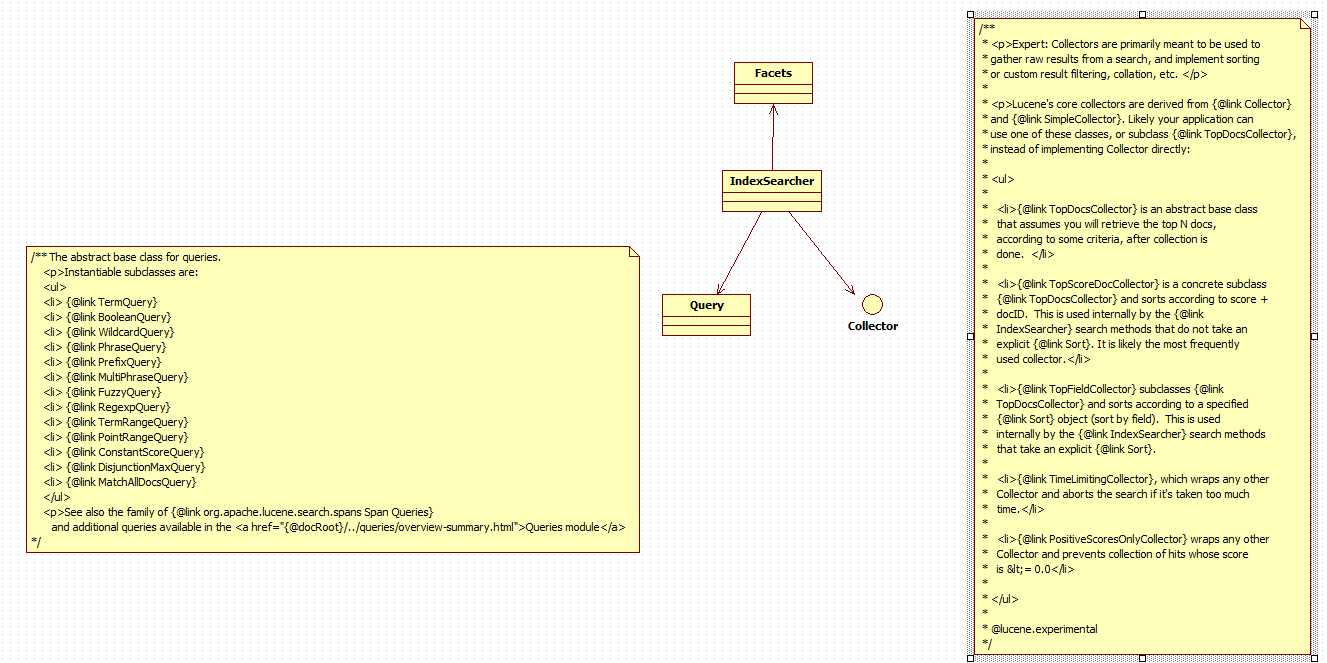
查询及其关系
查询
/** Lower-level search API. * * <p>{@link LeafCollector#collect(int)} is called for every matching document. * * @throws BooleanQuery.TooManyClauses If a query would exceed * {@link BooleanQuery#getMaxClauseCount()} clauses. */ public void search(Query query, Collector results) throws IOException { query = rewrite(query); search(leafContexts, createWeight(query, results.needsScores(), 1), results); }
关系
以上是关于lucene源码分析facet实例的主要内容,如果未能解决你的问题,请参考以下文章
Android 插件化VirtualApp 源码分析 ( 目前的 API 现状 | 安装应用源码分析 | 安装按钮执行的操作 | 返回到 HomeActivity 执行的操作 )(代码片段